TASP: Topology-aware Sequence Parallelism
作者: Yida Wang, Ke Hong, Xiuhong Li, Yuanchao Xu, Wenxun Wang, Guohao Dai, Yu Wang
分类: cs.LG, cs.DC
发布日期: 2025-09-30 (更新: 2025-10-09)
🔗 代码/项目: GITHUB
💡 一句话要点
提出TASP,利用拓扑感知序列并行加速长文本大模型训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 序列并行 长文本模型 拓扑感知 通信优化 大语言模型
📋 核心要点
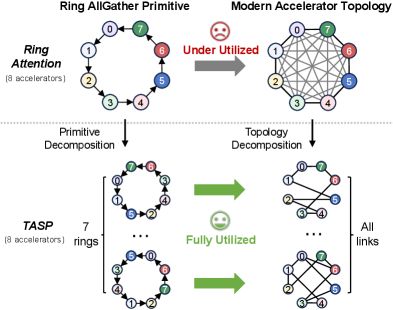
- 现有Ring Attention方法在长文本LLM序列并行中,因Ring AllGather通信原语与现代加速器AlltoAll拓扑不匹配,导致通信效率低下。
- TASP通过拓扑分解和原语分解,将加速器拓扑分解为多个并发环形数据路径,并分解Ring AllGather原语,充分利用通信能力。
- 实验表明,TASP在NVIDIA H100和AMD MI300X系统上,比Ring Attention及其变体实现了更高的通信效率和高达3.58倍的加速。
📝 摘要(中文)
长文本大语言模型(LLMs)由于自注意力机制的二次复杂度而面临限制。主流的序列并行(SP)方法Ring Attention试图通过将query分片到多个加速器上,并通过Ring AllGather通信原语使每个Q张量访问来自其他加速器的所有KV张量来解决这个问题。然而,它表现出较低的通信效率,限制了它的实际应用。这种低效源于它所采用的Ring AllGather通信原语与现代加速器的AlltoAll拓扑结构之间的不匹配。Ring AllGather原语由环状数据传输的迭代组成,这只能利用AlltoAll拓扑结构中非常有限的一部分。受完整有向图的哈密顿分解的启发,我们发现现代加速器拓扑可以分解为多个正交的环形数据路径,这些路径可以并发地传输数据而不会相互干扰。基于此,我们进一步观察到Ring AllGather原语也可以在每次迭代中分解为相同数量的并发环状数据传输。基于这些见解,我们提出TASP,一种用于长文本LLM的拓扑感知SP方法,它通过拓扑分解和原语分解充分利用现代加速器的通信能力。在单节点和多节点NVIDIA H100系统以及单节点AMD MI300X系统上的实验结果表明,TASP在这些现代加速器拓扑上实现了比Ring Attention更高的通信效率,并且实现了比Ring Attention及其变体Zigzag-Ring Attention高达3.58倍的加速。
🔬 方法详解
问题定义:论文旨在解决长文本大语言模型训练中,由于自注意力机制的复杂度,以及现有序列并行方法(如Ring Attention)通信效率低下的问题。Ring Attention采用的Ring AllGather通信原语与现代加速器的AlltoAll拓扑结构不匹配,导致通信瓶颈。
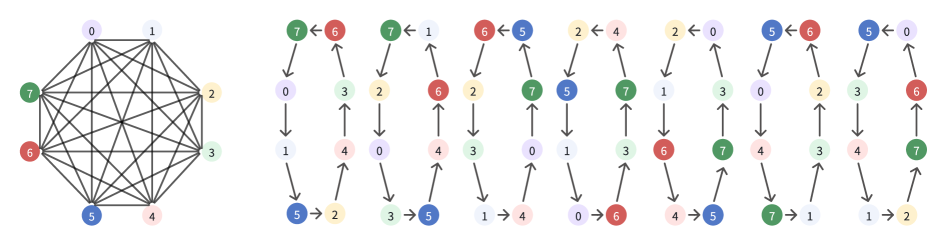
核心思路:论文的核心思路是利用现代加速器拓扑的特性,将AlltoAll拓扑分解为多个正交的环形数据路径,并对Ring AllGather原语进行分解,使其能够并发地在这些环形路径上传输数据,从而充分利用加速器的通信带宽。这种拓扑感知的方法能够更有效地进行数据交换,提高训练效率。
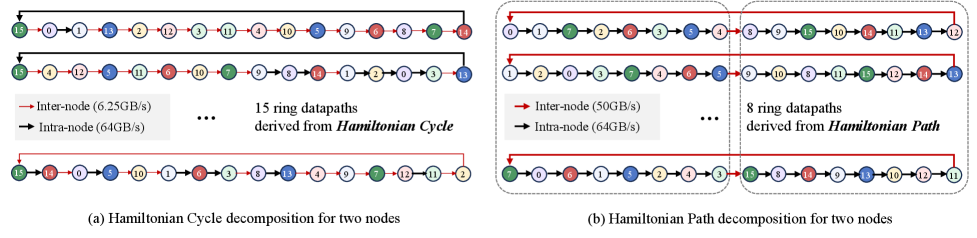
技术框架:TASP的技术框架主要包括两个关键部分:拓扑分解和原语分解。首先,对加速器拓扑进行分解,识别出多个可以并发传输数据的环形路径。然后,将Ring AllGather原语分解为多个可以在这些环形路径上并行执行的子原语。通过这种方式,TASP能够充分利用加速器的通信能力,减少通信开销。
关键创新:TASP最重要的技术创新点在于其拓扑感知的设计。它不再简单地使用传统的Ring AllGather原语,而是根据加速器的实际拓扑结构,对通信过程进行优化。这种方法能够更好地适应现代加速器的架构,提高通信效率。与现有方法相比,TASP能够更充分地利用加速器的通信带宽,从而实现更高的训练速度。
关键设计:TASP的关键设计在于如何进行拓扑分解和原语分解。拓扑分解需要根据加速器的具体架构,识别出最佳的环形路径集合。原语分解需要将Ring AllGather原语分解为多个可以在这些环形路径上并行执行的子原语,并确保这些子原语之间不会相互干扰。具体的参数设置和网络结构取决于具体的硬件平台和模型架构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TASP在NVIDIA H100和AMD MI300X等现代加速器上,相比Ring Attention及其变体Zigzag-Ring Attention,实现了更高的通信效率和显著的加速。具体而言,TASP实现了高达3.58倍的加速,证明了其在实际应用中的有效性。
🎯 应用场景
TASP可应用于各种需要长文本处理的大语言模型训练场景,例如文档摘要、机器翻译、代码生成等。通过提高训练效率,TASP能够降低训练成本,加速模型迭代,并促进更大规模、更复杂模型的开发。该方法对于充分利用现代加速器的计算和通信能力具有重要意义。
📄 摘要(原文)
Long-context large language models (LLMs) face constraints due to the quadratic complexity of the self-attention mechanism. The mainstream sequence parallelism (SP) method, Ring Attention, attempts to solve this by distributing the query into multiple query chunks across accelerators and enable each Q tensor to access all KV tensors from other accelerators via the Ring AllGather communication primitive. However, it exhibits low communication efficiency, restricting its practical applicability. This inefficiency stems from the mismatch between the Ring AllGather communication primitive it adopts and the AlltoAll topology of modern accelerators. A Ring AllGather primitive is composed of iterations of ring-styled data transfer, which can only utilize a very limited fraction of an AlltoAll topology. Inspired by the Hamiltonian decomposition of complete directed graphs, we identify that modern accelerator topology can be decomposed into multiple orthogonal ring datapaths which can concurrently transfer data without interference. Based on this, we further observe that the Ring AllGather primitive can also be decomposed into the same number of concurrent ring-styled data transfer at every iteration. Based on these insights, we propose TASP, a topology-aware SP method for long-context LLMs that fully utilizes the communication capacity of modern accelerators via topology decomposition and primitive decomposition. Experimental results on both single-node and multi-node NVIDIA H100 systems and a single-node AMD MI300X system demonstrate that TASP achieves higher communication efficiency than Ring Attention on these modern accelerator topologies and achieves up to 3.58 speedup than Ring Attention and its variant Zigzag-Ring Attention. The code is available at https://github.com/infinigence/HamiltonAttention.