TAP: Two-Stage Adaptive Personalization of Multi-Task and Multi-Modal Foundation Models in Federated Learning
作者: Seohyun Lee, Wenzhi Fang, Dong-Jun Han, Seyyedali Hosseinalipour, Christopher G. Brinton
分类: cs.LG, cs.AI
发布日期: 2025-09-30 (更新: 2026-01-30)
备注: 25 pages
💡 一句话要点
提出TAP:联邦学习中多任务多模态基础模型的两阶段自适应个性化方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 个性化模型 基础模型 多任务学习 多模态学习 知识蒸馏 自适应学习
📋 核心要点
- 现有联邦学习方法难以在数据、任务和模态异构的客户端上进行基础模型的个性化微调。
- TAP通过两阶段自适应个性化,利用架构不匹配选择性替换,并进行FL后知识蒸馏,实现个性化。
- 实验表明,TAP在各种数据集和任务上优于现有联邦个性化基线,验证了其有效性。
📝 摘要(中文)
在联邦学习(FL)中,模型的本地个性化受到了广泛关注,但基础模型的个性化微调仍然是一个重大挑战。特别是在文献中,对于如何在客户端之间数据、任务和模态都异构的环境中微调和个性化基础模型,缺乏深入的理解。为了解决这一差距,我们提出了TAP(两阶段自适应个性化),它具有两个关键特征:(i)利用客户端和服务器之间不匹配的模型架构,选择性地进行替换操作,以在有利于客户端本地任务时进行;(ii)进行FL后的知识蒸馏,以捕获有益的通用知识,而不损害个性化。在开发TAP时,我们首次对服务器上基于模态-任务对架构的联邦基础模型训练进行了收敛性分析,并证明随着模态-任务对数量的增加,其满足所有任务的能力会下降。通过广泛的实验,我们证明了我们提出的算法在各种数据集和任务中的有效性,并与最先进的联邦个性化基线进行了比较。
🔬 方法详解
问题定义:论文旨在解决联邦学习中,如何在客户端数据、任务和模态异构的情况下,对基础模型进行有效的个性化微调的问题。现有方法在处理这种异构性时存在不足,无法充分利用基础模型的通用知识,同时保证每个客户端的个性化需求。
核心思路:论文的核心思路是采用两阶段自适应个性化策略。第一阶段,利用客户端和服务器模型架构的不匹配,选择性地替换客户端模型的部分结构,以适应本地任务。第二阶段,在联邦学习完成后,进行知识蒸馏,将服务器的通用知识迁移到客户端的个性化模型中,从而在不损害个性化的前提下,提升模型的泛化能力。
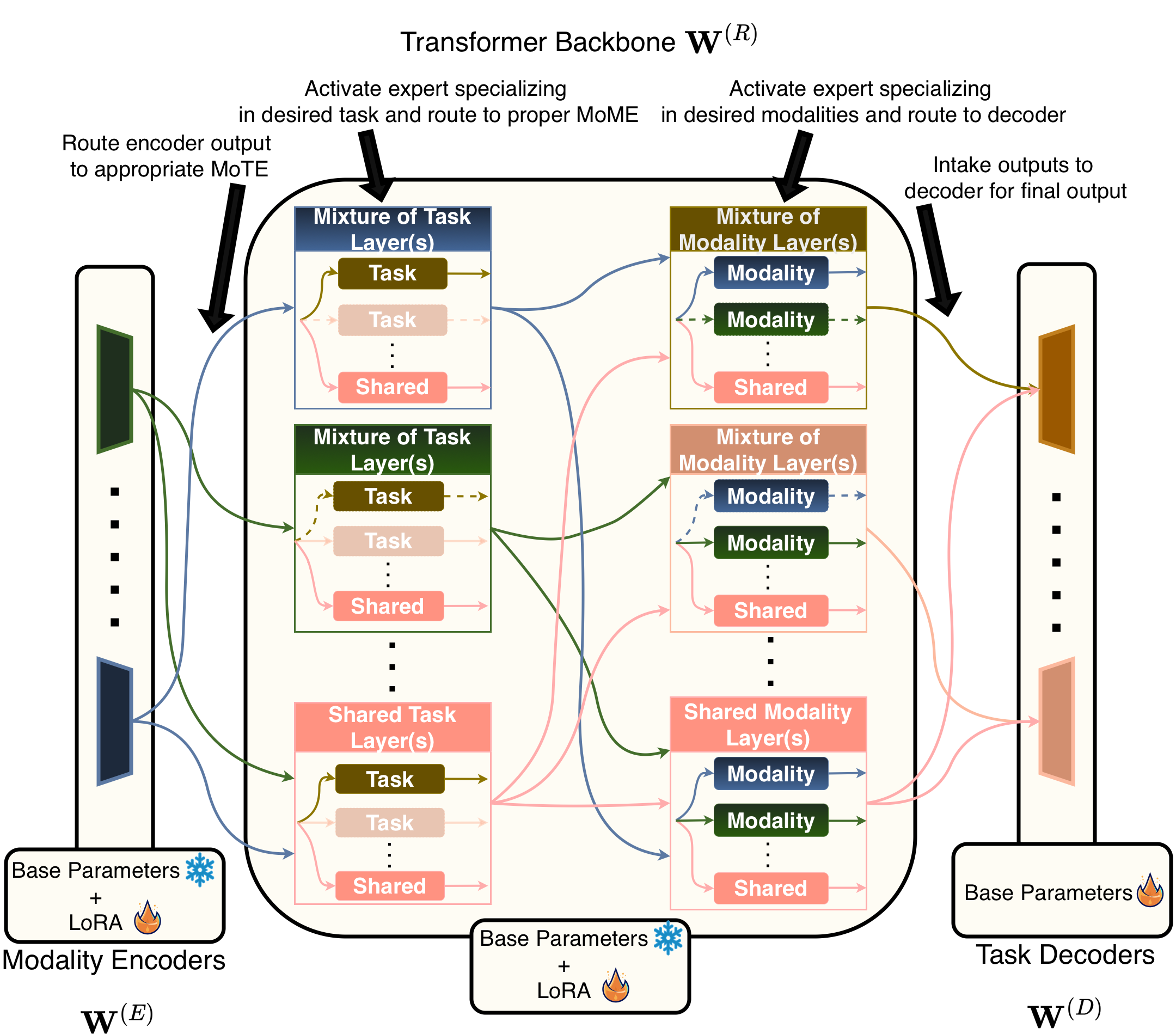
技术框架:TAP算法包含两个主要阶段:1) 自适应模型替换:服务器维护一个基础模型,客户端拥有各自的模型,这些模型可能与服务器模型架构不同。客户端根据本地任务的特点,选择性地用服务器模型的相应部分替换本地模型。替换的决策基于对本地任务性能的评估。2) 知识蒸馏:联邦学习完成后,服务器将其学习到的通用知识通过知识蒸馏的方式传递给客户端。客户端使用服务器模型的输出作为软标签,进一步微调本地模型。
关键创新:TAP的关键创新在于其两阶段的自适应个性化策略。首先,选择性模型替换允许客户端根据本地任务的需要,灵活地调整模型结构,避免了全局模型对所有客户端的强制约束。其次,FL后的知识蒸馏能够在保留个性化的同时,有效地利用服务器学习到的通用知识,提升模型的泛化能力。此外,论文还首次对联邦基础模型训练在模态-任务对架构下的收敛性进行了分析。
关键设计:在自适应模型替换阶段,客户端需要评估替换操作对本地任务性能的影响。这可以通过计算替换前后模型在本地验证集上的性能差异来实现。在知识蒸馏阶段,可以使用交叉熵损失函数,将服务器模型的输出作为软标签,指导客户端模型的训练。论文还分析了模态-任务对数量对模型性能的影响,并提出了相应的优化策略。
🖼️ 关键图片
📊 实验亮点
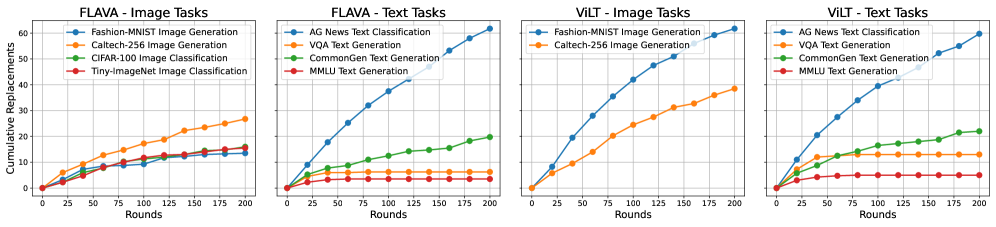
论文通过大量实验验证了TAP算法的有效性。实验结果表明,TAP在各种数据集和任务上均优于现有的联邦个性化基线方法。具体的性能提升幅度取决于数据集和任务的特点,但总体而言,TAP能够显著提高模型的准确率和泛化能力。此外,实验还验证了TAP的收敛性,并分析了不同参数设置对模型性能的影响。
🎯 应用场景
该研究成果可应用于医疗健康、金融风控、智能交通等领域。例如,在医疗领域,不同医院的数据模态和任务类型可能存在差异,TAP可以帮助每个医院个性化地微调医学影像分析模型,提高诊断准确率。在金融领域,可以为不同地区的银行定制风险评估模型,提升风控效果。该方法具有很强的实际应用价值和推广潜力。
📄 摘要(原文)
In federated learning (FL), local personalization of models has received significant attention, yet personalized fine-tuning of foundation models remains a significant challenge. In particular, there is a lack of understanding in the literature on how to fine-tune and personalize foundation models in settings that are heterogeneous across clients not only in data, but also in tasks and modalities. To address this gap, we propose TAP (Two-Stage Adaptive Personalization), which has two key features: (i) leveraging mismatched model architectures between the clients and server to selectively conduct replacement operations when it benefits a client's local tasks; (ii) engaging in post-FL knowledge distillation for capturing beneficial general knowledge without compromising personalization. In developing TAP, we introduce the first convergence analysis of federated foundation model training at the server under its modality-task pair architecture, and demonstrate that as the number of modality-task pairs increases, its ability to cater to all tasks suffers. Through extensive experiments, we demonstrate the effectiveness of our proposed algorithm across a variety of datasets and tasks in comparison to state-of-the-art federated personalization baselines.