Attribution-Guided Decoding
作者: Piotr Komorowski, Elena Golimblevskaia, Reduan Achtibat, Thomas Wiegand, Sebastian Lapuschkin, Wojciech Samek
分类: cs.LG
发布日期: 2025-09-30
💡 一句话要点
提出基于归因引导的解码方法(AGD),提升LLM指令遵循和知识准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 归因分析 解码策略 指令遵循 知识准确性 幻觉抑制
📋 核心要点
- 现有LLM解码方法在指令遵循和知识准确性方面存在不足,控制方法又容易降低生成质量。
- AGD通过选择对用户定义感兴趣区域(ROI)具有最高归因的token,引导LLM生成过程。
- 实验表明,AGD在指令遵循和知识密集型任务中均有显著提升,并提出了自适应变体。
📝 摘要(中文)
大型语言模型(LLM)遵循复杂指令和生成准确文本的能力至关重要。然而,标准解码方法难以稳健地满足这些要求,而现有的控制技术通常会降低输出质量。本文提出了一种基于可解释性的解码策略——归因引导解码(AGD)。AGD不直接操纵模型激活,而是考虑一组高概率的候选输出token,并选择对用户定义的感兴趣区域(ROI)具有最高归因的token。ROI可以灵活地定义在模型输入或内部组件的不同部分,从而引导生成过程朝着期望的行为发展。实验表明,AGD在三个具有挑战性的领域中有效。在指令遵循方面,AGD显著提高了遵循度(例如,在Llama 3.1上将总体成功率从66.0%提高到79.1%)。在知识密集型任务中,引导生成过程利用内部知识组件或上下文来源可以减少幻觉并提高事实准确性,无论是在闭卷还是开卷设置中。此外,我们提出了一种自适应的、基于熵的AGD变体,通过仅在模型不确定时应用指导来减轻质量下降并减少计算开销。这项工作提出了一种通用、更可解释且有效的方法来增强现代LLM的可靠性。
🔬 方法详解
问题定义:现有的大型语言模型在解码过程中,难以同时保证指令的严格遵循和生成内容的准确性。传统的解码方法缺乏对模型行为的细粒度控制,容易产生幻觉或偏离用户意图。现有的控制方法,如直接干预模型激活,可能会损害模型的整体生成能力,导致输出质量下降。
核心思路:AGD的核心思想是利用模型的可解释性,通过归因分析来引导解码过程。它不直接修改模型的内部状态,而是通过选择对特定区域(ROI)具有最高影响力的token来间接控制生成。这种方法旨在在保证生成质量的同时,提高模型对指令的遵循度和知识的准确性。
技术框架:AGD的整体流程如下:1) 对于每个解码步骤,模型生成一组候选token及其概率分布。2) 用户定义一个感兴趣区域(ROI),可以是输入文本的特定部分,也可以是模型的内部组件。3) 对于每个候选token,计算其对ROI的归因值。4) 选择具有最高归因值的token作为最终输出。5) 将选定的token添加到已生成的序列中,并重复该过程直到生成完成。
关键创新:AGD的关键创新在于其基于归因的解码策略。与传统的解码方法相比,AGD能够利用模型的可解释性信息来指导生成过程,从而实现更细粒度的控制。与直接操纵模型激活的方法相比,AGD更加温和,可以避免对模型整体生成能力的损害。自适应AGD变体进一步优化了计算效率和生成质量。
关键设计:ROI的定义是AGD的关键设计之一,它决定了模型关注的重点。归因方法的选择也很重要,可以使用诸如Integrated Gradients或LRP等方法。自适应AGD使用熵来衡量模型的不确定性,并仅在模型不确定时应用归因引导。具体参数设置取决于具体的任务和模型。
🖼️ 关键图片

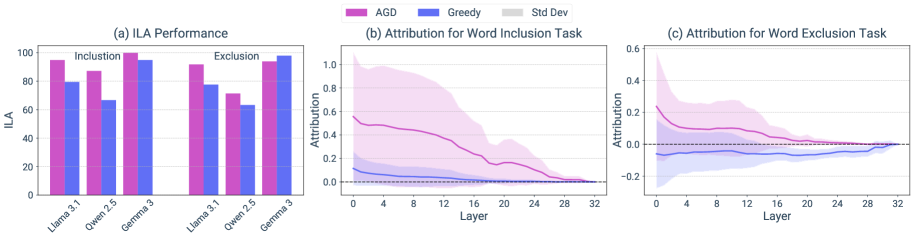

📊 实验亮点
实验结果表明,AGD在指令遵循任务中显著提高了Llama 3.1的成功率,从66.0%提升至79.1%。在知识密集型任务中,AGD能够有效减少幻觉并提高事实准确性。自适应AGD变体在保持性能的同时,降低了计算开销。这些结果验证了AGD的有效性和通用性。
🎯 应用场景
AGD可应用于各种需要高质量和可靠输出的LLM应用场景,例如:智能客服、内容创作、代码生成、医疗诊断等。通过引导模型关注关键信息,AGD可以提高生成内容的准确性、一致性和可控性,从而提升用户体验和应用价值。未来,AGD可以与其他控制技术相结合,进一步增强LLM的可靠性和安全性。
📄 摘要(原文)
The capacity of Large Language Models (LLMs) to follow complex instructions and generate factually accurate text is critical for their real-world application. However, standard decoding methods often fail to robustly satisfy these requirements, while existing control techniques frequently degrade general output quality. In this work, we introduce Attribution-Guided Decoding (AGD), an interpretability-based decoding strategy. Instead of directly manipulating model activations, AGD considers a set of high-probability output token candidates and selects the one that exhibits the highest attribution to a user-defined Region of Interest (ROI). This ROI can be flexibly defined over different parts of the model's input or internal components, allowing AGD to steer generation towards various desirable behaviors. We demonstrate AGD's efficacy across three challenging domains. For instruction following, we show that AGD significantly boosts adherence (e.g., improving the overall success rate on Llama 3.1 from 66.0% to 79.1%). For knowledge-intensive tasks, we show that guiding generation towards usage of internal knowledge components or contextual sources can reduce hallucinations and improve factual accuracy in both closed-book and open-book settings. Furthermore, we propose an adaptive, entropy-based variant of AGD that mitigates quality degradation and reduces computational overhead by applying guidance only when the model is uncertain. Our work presents a versatile, more interpretable, and effective method for enhancing the reliability of modern LLMs.