Accelerating Transformers in Online RL
作者: Daniil Zelezetsky, Alexey K. Kovalev, Aleksandr I. Panov
分类: cs.LG
发布日期: 2025-09-30
💡 一句话要点
提出基于加速器策略的Transformer在线强化学习方法,提升训练稳定性和速度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Transformer 强化学习 在线学习 行为克隆 加速器策略
📋 核心要点
- Transformer模型在强化学习中面临训练不稳定和计算需求高的挑战,尤其是在在线强化学习场景下。
- 论文提出使用加速器策略,先通过行为克隆预训练Transformer,再进行在线强化学习,提升训练稳定性和速度。
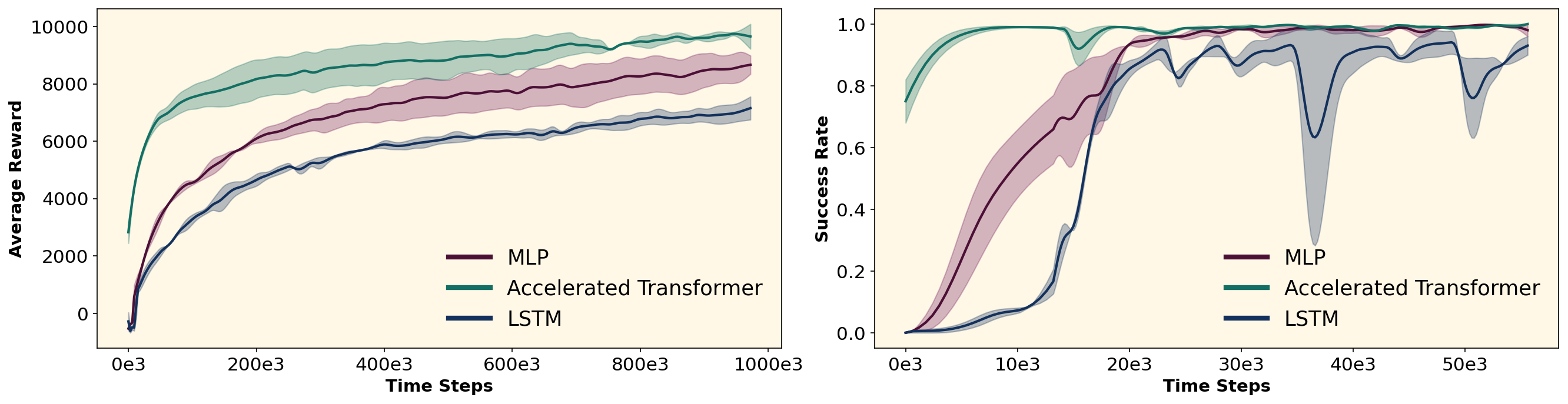
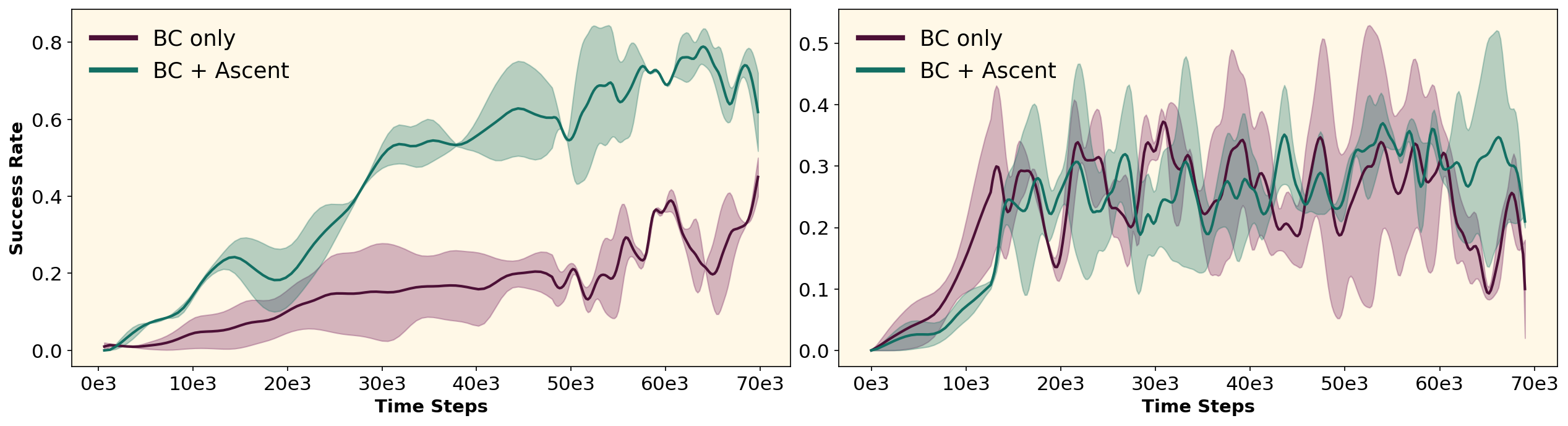
- 实验表明,该方法能稳定训练Transformer,降低图像环境训练时间,并显著减少离策略方法所需的重放缓冲区大小。
📝 摘要(中文)
本文提出了一种使用加速器策略训练Transformer的方法,旨在解决基于Transformer的模型在无模型在线强化学习中难以实现的问题。该方法首先利用一个更简单、更稳定的加速器模型与环境交互,并通过行为克隆训练Transformer。然后,预训练的Transformer开始完全在线地与环境交互。实验结果表明,该算法不仅能够稳定地训练Transformer,还能在基于图像的环境中将训练时间缩短一半。此外,它还将离策略方法所需的重放缓冲区大小减少到1-2万,从而显著降低了整体计算需求。该方法在基于状态和图像的ManiSkill环境以及MDP和POMDP设置下的MuJoCo任务中进行了验证。
🔬 方法详解
问题定义:现有基于Transformer的强化学习方法,尤其是在线强化学习,面临训练不稳定、计算资源需求大的问题。Transformer模型本身复杂,直接用于在线学习容易发散,且需要大量的样本数据进行训练,导致训练时间长,对硬件要求高。
核心思路:论文的核心思路是利用一个更简单、更稳定的“加速器”策略来辅助Transformer的训练。加速器策略先与环境交互,收集数据,并利用这些数据通过行为克隆的方式预训练Transformer。这样,Transformer在开始与环境交互之前,已经具备了一定的策略基础,从而降低了训练的难度和不稳定性。
技术框架:该算法包含两个主要阶段:第一阶段是加速器策略训练阶段,加速器策略与环境交互并收集数据,同时使用这些数据通过行为克隆训练Transformer。第二阶段是Transformer在线学习阶段,预训练的Transformer开始与环境交互,并使用标准的强化学习算法进行在线更新。加速器策略不再直接参与环境交互,但其训练数据仍然可以用于辅助Transformer的训练。
关键创新:该方法最重要的创新点在于引入了“加速器”策略的概念,将Transformer的训练过程分解为预训练和在线学习两个阶段。通过行为克隆预训练,Transformer可以更快地学习到有用的策略,从而提高训练效率和稳定性。这种方法避免了直接从零开始训练Transformer的困难,降低了对样本数据的需求。
关键设计:加速器策略可以选择相对简单的模型结构,例如线性模型或浅层神经网络,以保证其训练的稳定性和效率。行为克隆的损失函数通常采用均方误差或交叉熵损失,用于最小化Transformer的输出与加速器策略的输出之间的差异。在在线学习阶段,可以使用各种标准的强化学习算法,例如PPO、SAC等。重放缓冲区的大小可以根据具体任务进行调整,但通常可以设置得较小,例如1-2万。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该算法在ManiSkill和MuJoCo等环境中能够稳定地训练Transformer模型。在图像环境中,训练时间缩短了高达两倍。此外,离策略方法所需的重放缓冲区大小减少到1-2万,显著降低了计算需求。这些结果表明,该方法在提高Transformer训练效率和降低资源消耗方面具有显著优势。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过加速Transformer的训练,可以更快地开发出高性能的智能体,从而提高自动化水平和智能化程度。尤其是在资源受限的场景下,该方法能够降低对计算资源的需求,使得Transformer模型能够在更广泛的平台上应用。
📄 摘要(原文)
The appearance of transformer-based models in Reinforcement Learning (RL) has expanded the horizons of possibilities in robotics tasks, but it has simultaneously brought a wide range of challenges during its implementation, especially in model-free online RL. Some of the existing learning algorithms cannot be easily implemented with transformer-based models due to the instability of the latter. In this paper, we propose a method that uses the Accelerator policy as a transformer's trainer. The Accelerator, a simpler and more stable model, interacts with the environment independently while simultaneously training the transformer through behavior cloning during the first stage of the proposed algorithm. In the second stage, the pretrained transformer starts to interact with the environment in a fully online setting. As a result, this model-free algorithm accelerates the transformer in terms of its performance and helps it to train online in a more stable and faster way. By conducting experiments on both state-based and image-based ManiSkill environments, as well as on MuJoCo tasks in MDP and POMDP settings, we show that applying our algorithm not only enables stable training of transformers but also reduces training time on image-based environments by up to a factor of two. Moreover, it decreases the required replay buffer size in off-policy methods to 10-20 thousand, which significantly lowers the overall computational demands.