Clip-Low Increases Entropy and Clip-High Decreases Entropy in Reinforcement Learning of Large Language Models
作者: Jaesung R. Park, Junsu Kim, Gyeongman Kim, Jinyoung Jo, Sean Choi, Jaewoong Cho, Ernest K. Ryu
分类: cs.LG
发布日期: 2025-09-30
💡 一句话要点
揭示PPO/GRPO中裁剪机制对LLM强化学习熵的影响,提出clip-low增加探索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 熵崩溃 PPO GRPO 裁剪机制 探索 RLVR
📋 核心要点
- RLVR在提升LLM推理能力方面表现出色,但易出现熵崩溃,限制了模型探索和长期训练效果。
- 论文核心思想是分析PPO/GRPO裁剪机制对熵的影响,发现clip-low增加熵,clip-high降低熵。
- 实验表明,标准裁剪参数下clip-high主导,导致熵降低。通过调整clip-low可有效控制熵,防止熵崩溃。
📝 摘要(中文)
基于可验证奖励的强化学习(RLVR)已成为提升大型语言模型(LLM)推理能力的主流方法。然而,RLVR容易出现熵崩溃,LLM迅速收敛到近乎确定性的形式,阻碍了长期强化学习训练中的探索和进步。本文揭示了PPO和GRPO中的裁剪机制会对熵产生偏差。通过理论和实证分析,我们表明clip-low会增加熵,而clip-high会降低熵。此外,在标准裁剪参数下,clip-high的影响占主导地位,即使在为RL算法提供纯粹随机奖励时,也会导致整体熵降低。我们的发现强调了RLVR中一个被忽视的混淆因素:裁剪机制独立于奖励信号影响熵,进而影响推理行为。此外,我们的分析表明,可以有意识地使用裁剪来控制熵。具体而言,通过更激进的clip-low值,可以增加熵,促进探索,并最终防止RLVR训练中的熵崩溃。
🔬 方法详解
问题定义:论文旨在解决大型语言模型强化学习训练过程中出现的熵崩溃问题。现有方法,特别是基于PPO和GRPO的RLVR,虽然在提升LLM推理能力方面有效,但由于缺乏足够的探索,模型容易过早收敛,导致性能瓶颈。现有方法忽略了裁剪机制对熵的影响,导致训练不稳定。
核心思路:论文的核心思路是深入分析PPO和GRPO中裁剪机制对策略熵的影响。通过理论推导和实验验证,揭示clip-low和clip-high分别对熵产生相反的影响。通过控制裁剪参数,特别是clip-low,可以调节策略的探索能力,从而缓解熵崩溃问题。
技术框架:论文主要采用理论分析和实证研究相结合的方法。首先,对PPO和GRPO的裁剪机制进行数学建模,推导出裁剪参数与策略熵之间的关系。然后,设计一系列实验,验证理论分析的正确性,并评估不同裁剪参数对RLVR训练效果的影响。整体流程包括:理论分析 -> 实验设计 -> 结果验证 -> 参数优化。
关键创新:论文最重要的技术创新在于揭示了PPO/GRPO中裁剪机制对策略熵的隐蔽影响。以往的研究主要关注奖励函数的设计和优化,而忽略了裁剪机制本身对探索能力的影响。论文首次明确指出clip-low增加熵,clip-high降低熵,为解决熵崩溃问题提供了新的视角。
关键设计:论文的关键设计包括:1) 对PPO和GRPO的裁剪函数进行精确的数学建模,推导出熵的上下界;2) 设计对照实验,分别评估clip-low和clip-high对熵的影响;3) 探索不同的clip-low值,寻找最佳的熵控制策略;4) 实验中使用了标准的LLM强化学习训练流程,并针对裁剪参数进行了细致的调整。
🖼️ 关键图片
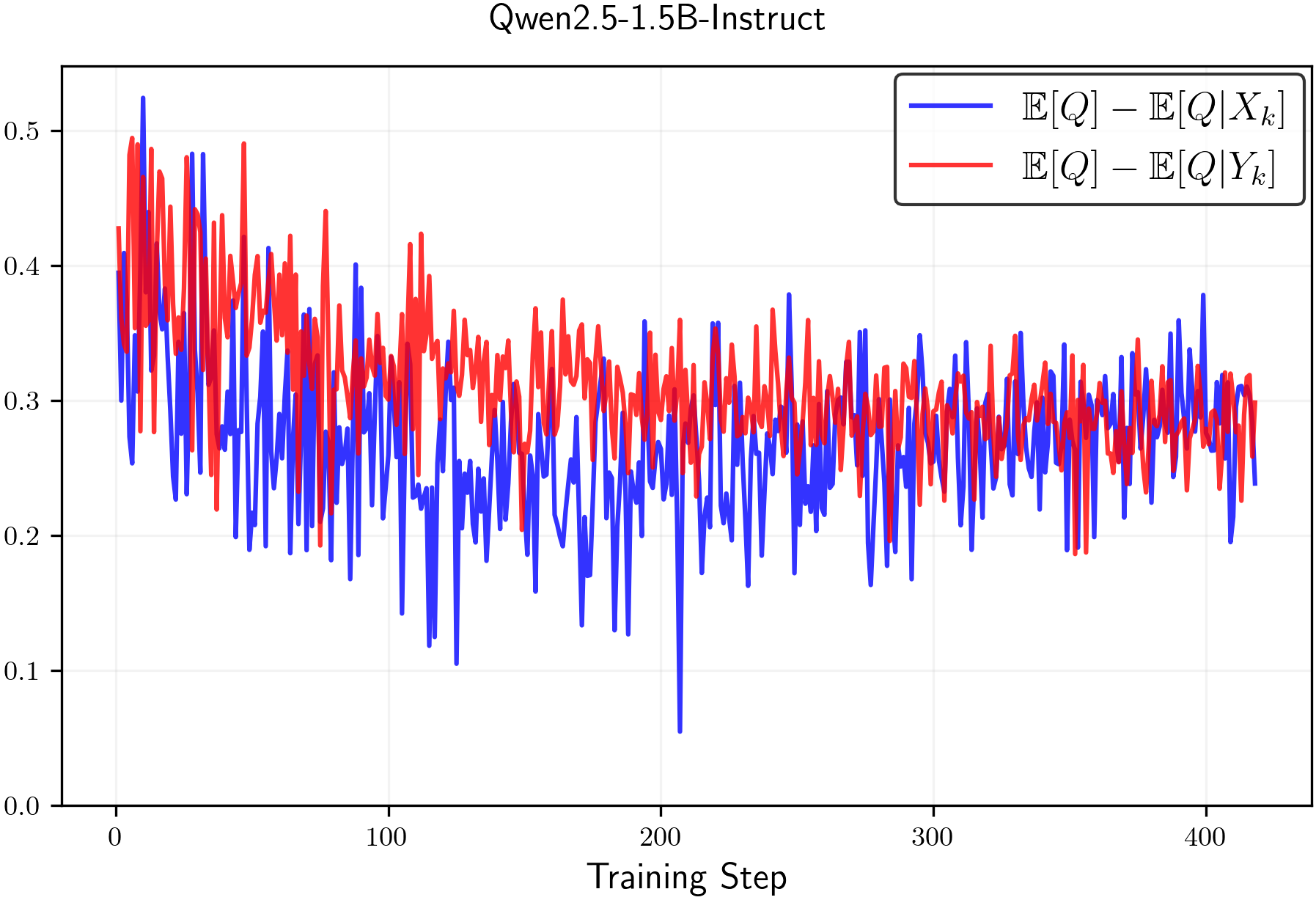
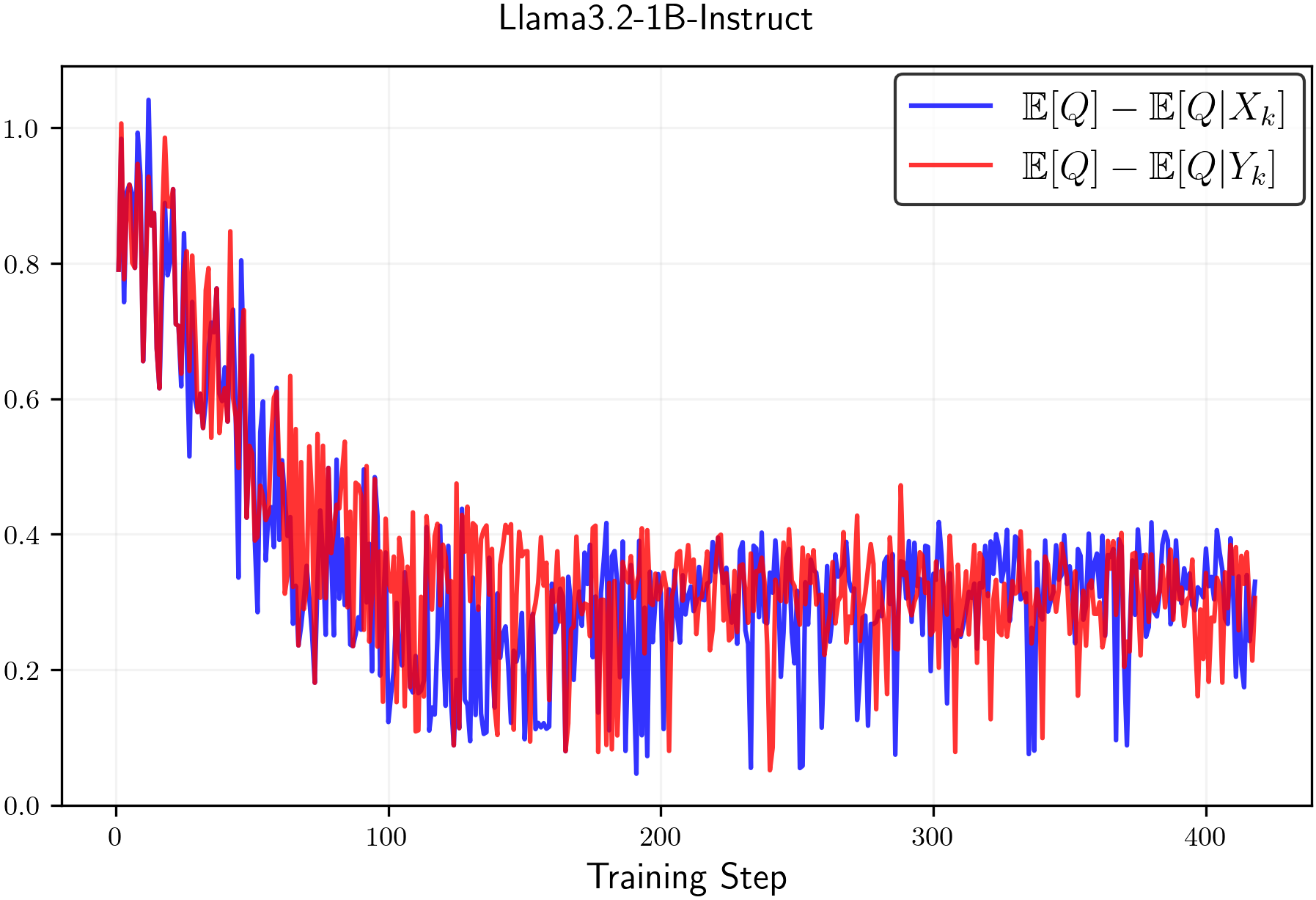
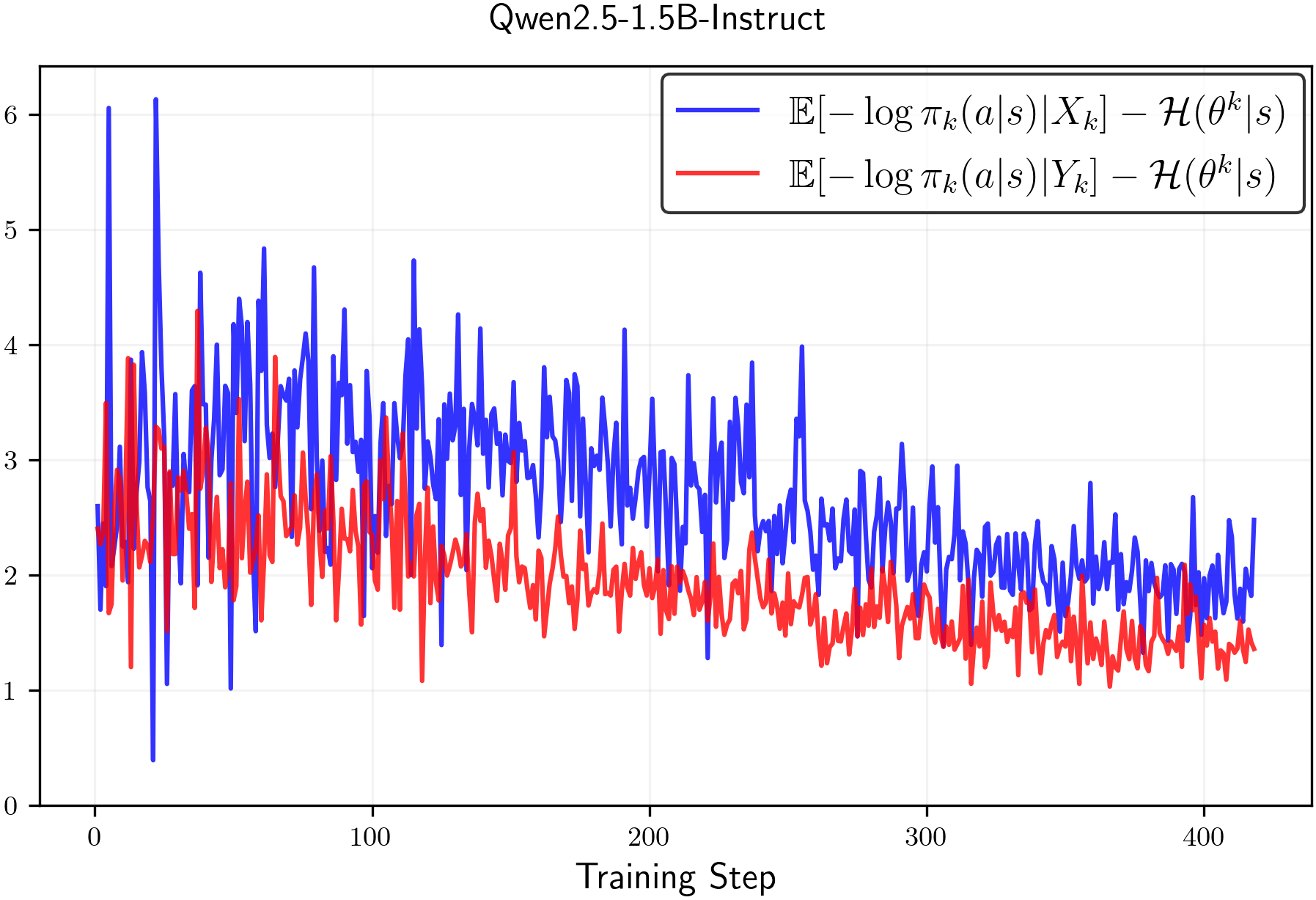
📊 实验亮点
论文通过实验验证了clip-low增加熵,clip-high降低熵的结论。在标准裁剪参数下,即使使用随机奖励,模型仍然会因为clip-high的影响而出现熵降低。通过调整clip-low的值,可以有效增加熵,防止熵崩溃,从而提升RLVR训练的效果。具体的性能提升幅度未知,但论文强调了熵控制的重要性。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型进行强化学习的任务,例如对话生成、文本摘要、代码生成等。通过控制裁剪参数,可以提高模型的探索能力,避免过早收敛,从而获得更优的性能。该研究对于提升LLM的长期训练效果具有重要意义。
📄 摘要(原文)
Reinforcement learning with verifiable rewards (RLVR) has recently emerged as the leading approach for enhancing the reasoning capabilities of large language models (LLMs). However, RLVR is prone to entropy collapse, where the LLM quickly converges to a near-deterministic form, hindering exploration and progress during prolonged RL training. In this work, we reveal that the clipping mechanism in PPO and GRPO induces biases on entropy. Through theoretical and empirical analyses, we show that clip-low increases entropy, while clip-high decreases it. Further, under standard clipping parameters, the effect of clip-high dominates, resulting in an overall entropy reduction even when purely random rewards are provided to the RL algorithm. Our findings highlight an overlooked confounding factor in RLVR: independent of the reward signal, the clipping mechanism influences entropy, which in turn affects the reasoning behavior. Furthermore, our analysis demonstrates that clipping can be deliberately used to control entropy. Specifically, with a more aggressive clip-low value, one can increase entropy, promote exploration, and ultimately prevent entropy collapse in RLVR training.