Muon Outperforms Adam in Tail-End Associative Memory Learning
作者: Shuche Wang, Fengzhuo Zhang, Jiaxiang Li, Cunxiao Du, Chao Du, Tianyu Pang, Zhuoran Yang, Mingyi Hong, Vincent Y. F. Tan
分类: cs.LG, cs.AI, math.OC
发布日期: 2025-09-30 (更新: 2025-10-05)
💡 一句话要点
Muon优化器在长尾关联记忆学习中优于Adam,提升尾部类别学习效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Muon优化器 Adam优化器 长尾学习 关联记忆 大型语言模型
📋 核心要点
- 大型语言模型训练中,Muon优化器速度优于Adam,但其内在机制尚不清晰。
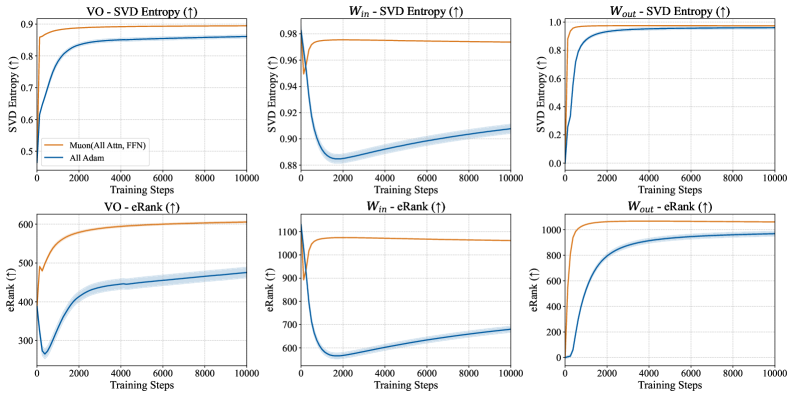
- 论文从关联记忆角度解释Muon的优势,发现其擅长优化Value/Output权重和前馈网络。
- 理论分析表明,Muon在长尾数据上能更有效地学习尾部类别,实现更平衡的学习效果。
📝 摘要(中文)
Muon优化器在训练大型语言模型(LLMs)时始终比Adam更快,但其成功机制尚不明确。本文通过关联记忆的视角揭示了这一机制。通过消融Muon优化的Transformer组件,我们发现LLMs的关联记忆参数,即Value和Output(VO)注意力权重以及前馈网络(FFNs),是Muon优越性的主要贡献者。受此关联记忆观点的启发,我们解释了Muon在本质上具有重尾分布的真实语料库上的优越性:一些类别(尾部类别)出现的频率远低于其他类别。这种优越性可以通过两个关键属性来解释:(i)其更新规则始终产生比Adam更各向同性的奇异谱;因此,(ii)在重尾数据上,它比Adam更有效地优化尾部类别。除了经验证据外,我们通过分析类别不平衡数据下的单层关联记忆模型,从理论上证实了这些发现。我们证明,无论特征嵌入如何,Muon始终实现跨类别的平衡学习,而Adam可能会根据嵌入属性导致学习误差的巨大差异。总而言之,我们的经验观察和理论分析揭示了Muon的核心优势:其更新规则与线性关联记忆的外积结构对齐,从而能够比Adam更平衡有效地学习重尾分布中的尾部类别。
🔬 方法详解
问题定义:现有的大型语言模型训练中,Adam优化器被广泛使用,但在某些情况下,例如处理长尾数据时,其性能会受到限制。Muon优化器在实践中表现出优于Adam的性能,尤其是在训练大型语言模型时,但其内在机制尚不明确。因此,需要深入理解Muon优化器的优势来源,并解释其在特定场景下的优越性。
核心思路:论文的核心思路是从关联记忆的角度来分析Muon优化器的优势。关联记忆是神经网络中的一种重要机制,它允许网络存储和检索模式。论文认为,Muon优化器在优化大型语言模型中的关联记忆参数(如Value/Output权重和前馈网络)时表现更好,从而导致其整体性能优于Adam。此外,论文还关注长尾数据,即某些类别的样本数量远少于其他类别。论文认为,Muon优化器在处理长尾数据时能够更有效地学习尾部类别,从而实现更平衡的学习效果。
技术框架:论文的技术框架主要包括以下几个部分:首先,通过消融实验,确定Muon优化器在优化Transformer模型中的哪些组件时表现出优势。其次,通过分析Muon和Adam优化器的更新规则,解释其在处理长尾数据时的不同行为。然后,通过理论分析,证明Muon优化器在单层关联记忆模型中能够实现跨类别的平衡学习。最后,通过实验验证理论分析的结论。
关键创新:论文的关键创新在于从关联记忆的角度解释了Muon优化器的优势,并揭示了其在处理长尾数据时的优越性。具体来说,论文证明了Muon优化器的更新规则与线性关联记忆的外积结构对齐,从而能够更有效地学习尾部类别。此外,论文还通过理论分析证明了Muon优化器在单层关联记忆模型中能够实现跨类别的平衡学习,而Adam优化器则可能导致学习误差的巨大差异。
关键设计:论文的关键设计包括:(1) 使用消融实验来确定Muon优化器在优化Transformer模型中的哪些组件时表现出优势;(2) 分析Muon和Adam优化器的更新规则,并比较其在处理长尾数据时的不同行为;(3) 建立单层关联记忆模型,并对其进行理论分析,以证明Muon优化器能够实现跨类别的平衡学习;(4) 使用真实数据集进行实验,验证理论分析的结论。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Muon优化器在长尾数据集上显著优于Adam。理论分析表明,Muon的更新规则能够产生更各向同性的奇异谱,从而更有效地优化尾部类别。在单层关联记忆模型中,Muon始终实现跨类别的平衡学习,而Adam可能导致学习误差的巨大差异。这些结果为Muon优化器的优势提供了有力的证据。
🎯 应用场景
该研究成果可应用于各种需要处理长尾数据的机器学习任务,例如自然语言处理、图像识别、推荐系统等。通过使用Muon优化器,可以更有效地学习尾部类别,提高模型的整体性能和泛化能力。尤其是在医疗诊断、金融风控等领域,尾部类别的准确识别至关重要,该研究具有重要的实际应用价值。
📄 摘要(原文)
The Muon optimizer is consistently faster than Adam in training Large Language Models (LLMs), yet the mechanism underlying its success remains unclear. This paper demystifies this mechanism through the lens of associative memory. By ablating the transformer components optimized by Muon, we reveal that the associative memory parameters of LLMs, namely the Value and Output (VO) attention weights and Feed-Forward Networks (FFNs), are the primary contributors to Muon's superiority. Motivated by this associative memory view, we then explain Muon's superiority on real-world corpora, which are intrinsically heavy-tailed: a few classes (tail classes) appear far less frequently than others. The superiority is explained through two key properties: (i) its update rule consistently yields a more isotropic singular spectrum than Adam; and as a result, (ii) on heavy-tailed data, it optimizes tail classes more effectively than Adam. Beyond empirical evidence, we theoretically confirm these findings by analyzing a one-layer associative memory model under class-imbalanced data. We prove that Muon consistently achieves balanced learning across classes regardless of feature embeddings, whereas Adam can induce large disparities in learning errors depending on embedding properties. In summary, our empirical observations and theoretical analyses reveal Muon's core advantage: its update rule aligns with the outer-product structure of linear associative memories, enabling more balanced and effective learning of tail classes in heavy-tailed distributions than Adam.