Informed Asymmetric Actor-Critic: Leveraging Privileged Signals Beyond Full-State Access
作者: Daniel Ebi, Gaspard Lambrechts, Damien Ernst, Klemens Böhm
分类: cs.LG, stat.ML
发布日期: 2025-09-30
备注: 15 pages, 21 pages total
💡 一句话要点
提出Informed Asymmetric Actor-Critic,利用特权信号提升部分可观测环境下的强化学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 非对称Actor-Critic 部分可观测环境 特权信息 策略梯度
📋 核心要点
- 现有非对称Actor-Critic方法通常假设训练时可访问完整状态,限制了其在实际部分可观测环境中的应用。
- 提出Informed Asymmetric Actor-Critic框架,允许Critic以任意特权信号为条件,无需访问完整状态,扩展了非对称方法的理论基础。
- 实验表明,该方法在基准导航任务和合成部分可观测环境中,提高了学习效率和价值估计,验证了其有效性。
📝 摘要(中文)
在部分可观测环境中,强化学习智能体需要在噪声和不完整观测的不确定性下行动。非对称Actor-Critic方法利用训练期间的特权信息来改善这种情况下的学习。然而,现有方法通常假设训练期间可以访问完整状态。本文挑战了这一假设,提出了一种新的Actor-Critic框架,称为Informed Asymmetric Actor-Critic,它允许Critic以任意特权信号为条件,而无需访问完整状态。我们证明了在这种公式下,策略梯度仍然是无偏的,从而将非对称方法的理论基础扩展到更一般的特权部分信息的情况。为了量化这些信号的影响,我们提出了基于核方法和回报预测误差的信息性度量,为评估训练时信号提供了实用工具。我们在基准导航任务和合成部分可观测环境中验证了我们的方法,表明当存在信息丰富的特权输入时,我们的Informed Asymmetric方法提高了学习效率和价值估计。我们的发现挑战了完整状态访问的必要性,并为设计既实用又理论上合理的非对称强化学习方法开辟了新的方向。
🔬 方法详解
问题定义:现有非对称Actor-Critic方法依赖于在训练期间访问完整状态信息,这在许多实际应用中是不现实的,因为智能体通常只能获得部分观测。这种对完整状态的依赖限制了这些方法在更广泛的部分可观测环境中的应用,并且没有充分利用可能存在的其他有用的特权信息。
核心思路:本文的核心思路是允许Critic网络利用任意的特权信号,而无需访问完整状态。通过将Critic的输入扩展到包含这些特权信号,智能体可以学习更准确的价值函数,从而改进策略学习。关键在于证明即使在Critic使用部分特权信息的情况下,策略梯度仍然是无偏的,从而保证了算法的收敛性。
技术框架:Informed Asymmetric Actor-Critic框架包含一个Actor网络和一个Critic网络。Actor网络基于部分观测生成动作,而Critic网络则基于部分观测和特权信号来评估Actor生成的动作的价值。该框架使用标准的Actor-Critic更新规则,但Critic的输入包括额外的特权信息。此外,论文还提出了基于核方法和回报预测误差的信息性度量,用于评估不同特权信号的有效性。
关键创新:最重要的技术创新点在于扩展了非对称Actor-Critic方法的理论基础,使其能够处理任意的特权信号,而不仅仅是完整状态。这使得该方法能够利用更广泛的信息来源来改进学习,并且更加适用于实际的部分可观测环境。此外,提出的信息性度量为选择合适的特权信号提供了指导。
关键设计:Critic网络的设计是关键。Critic的输入包括部分观测和特权信号,这些信号可以是任何与环境状态相关的额外信息。论文没有对特权信号的类型或格式做出任何限制,这使得该方法非常灵活。损失函数采用标准的时序差分误差,策略梯度更新规则也与标准的Actor-Critic方法相同。关键在于证明了在这种情况下,策略梯度仍然是无偏的。
🖼️ 关键图片
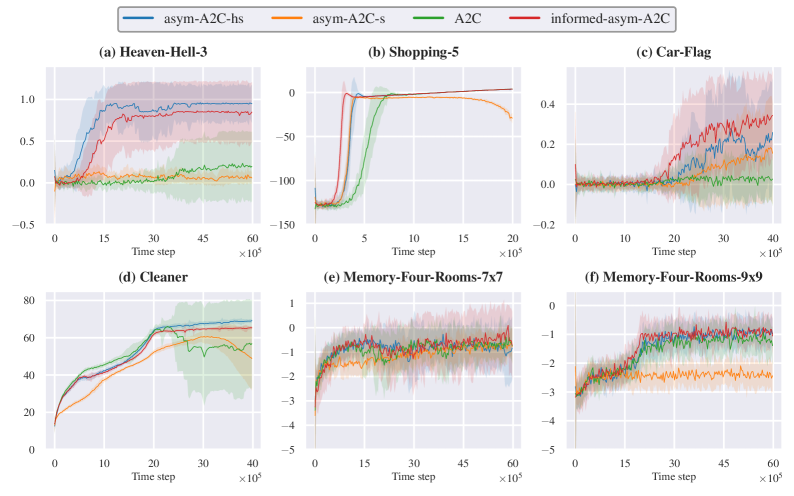
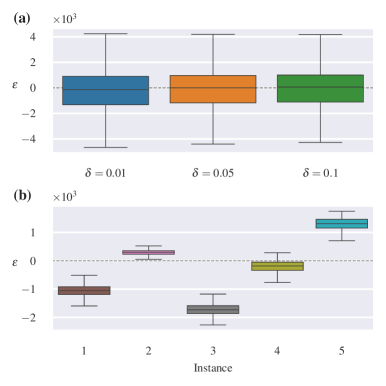
📊 实验亮点
实验结果表明,Informed Asymmetric Actor-Critic方法在基准导航任务和合成部分可观测环境中,显著提高了学习效率和价值估计的准确性。与传统的Actor-Critic方法相比,该方法能够更快地收敛到最优策略,并且在部分可观测环境中表现出更强的鲁棒性。通过使用信息性度量选择合适的特权信号,可以进一步提高性能。
🎯 应用场景
该研究成果可应用于机器人导航、游戏AI、自动驾驶等领域,尤其是在环境信息不完整或存在噪声的情况下。通过利用额外的传感器数据或专家知识作为特权信号,可以显著提高智能体的学习效率和性能。该方法为设计更智能、更鲁棒的强化学习系统提供了新的思路。
📄 摘要(原文)
Reinforcement learning in partially observable environments requires agents to act under uncertainty from noisy, incomplete observations. Asymmetric actor-critic methods leverage privileged information during training to improve learning under these conditions. However, existing approaches typically assume full-state access during training. In this work, we challenge this assumption by proposing a novel actor-critic framework, called informed asymmetric actor-critic, that enables conditioning the critic on arbitrary privileged signals without requiring access to the full state. We show that policy gradients remain unbiased under this formulation, extending the theoretical foundation of asymmetric methods to the more general case of privileged partial information. To quantify the impact of such signals, we propose informativeness measures based on kernel methods and return prediction error, providing practical tools for evaluating training-time signals. We validate our approach empirically on benchmark navigation tasks and synthetic partially observable environments, showing that our informed asymmetric method improves learning efficiency and value estimation when informative privileged inputs are available. Our findings challenge the necessity of full-state access and open new directions for designing asymmetric reinforcement learning methods that are both practical and theoretically sound.