Efficient On-Policy Reinforcement Learning via Exploration of Sparse Parameter Space
作者: Xinyu Zhang, Aishik Deb, Klaus Mueller
分类: cs.LG, cs.AI
发布日期: 2025-09-30
备注: 16 pages; 7 figures
💡 一句话要点
提出ExploRLer,通过探索稀疏参数空间提升On-Policy强化学习效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: On-Policy强化学习 参数空间探索 策略梯度 近端策略优化 连续控制 迭代级别优化
📋 核心要点
- 传统On-Policy方法仅沿单一梯度方向更新,忽略参数空间中潜在的更优解。
- ExploRLer通过系统探索On-Policy梯度更新的邻域,寻找更高性能的策略。
- ExploRLer在复杂连续控制环境中显著提升性能,无需增加梯度更新次数。
📝 摘要(中文)
近端策略优化(PPO)等策略梯度方法通常沿单一随机梯度方向更新,忽略了参数空间丰富的局部结构。以往研究表明,替代梯度与真实奖励landscape的相关性较差。基于此,我们可视化迭代中策略检查点所跨越的参数空间,发现更高性能的解通常位于附近未探索的区域。为了利用这一机会,我们引入ExploRLer,一个可无缝集成到PPO和TRPO等on-policy算法中的插件式pipeline,系统地探测替代on-policy梯度更新的未探索邻域。在不增加梯度更新次数的情况下,ExploRLer在复杂的连续控制环境中实现了显著改进。我们的结果表明,迭代级探索提供了一种实用有效的方法来加强on-policy强化学习,并为替代目标的局限性提供了新的视角。
🔬 方法详解
问题定义:现有的On-Policy强化学习方法,如PPO和TRPO,在更新策略时通常只沿着一个随机梯度方向进行。这种做法忽略了参数空间中可能存在的更优解,尤其是在替代梯度与真实奖励landscape相关性较差的情况下。因此,如何更有效地利用每次迭代中获得的策略信息,探索参数空间,找到更好的策略,是本文要解决的问题。
核心思路:本文的核心思路是,在每次策略迭代中,不仅仅使用单一的梯度更新方向,而是通过系统地探索当前策略参数附近的区域,寻找性能更优的策略。作者观察到,在参数空间中,更高性能的解往往位于当前策略附近的未探索区域。因此,通过对这些区域进行采样和评估,可以找到比单一梯度更新更好的策略。
技术框架:ExploRLer是一个插件式的pipeline,可以无缝集成到现有的On-Policy算法中,如PPO和TRPO。其主要流程如下:1) 在每次策略迭代中,首先使用标准的On-Policy算法进行梯度更新,得到一个初步的策略更新方向。2) 然后,ExploRLer会在该更新方向的邻域内进行采样,生成多个候选策略。3) 对这些候选策略进行评估,选择性能最佳的策略作为最终的更新结果。
关键创新:ExploRLer的关键创新在于其迭代级别的参数空间探索机制。与传统的On-Policy方法只使用单一梯度更新不同,ExploRLer通过系统地探索参数空间,寻找更优的策略。这种探索机制可以有效地克服替代梯度与真实奖励landscape相关性较差的问题,从而提高学习效率和性能。
关键设计:ExploRLer的关键设计包括:1) 邻域采样策略:如何有效地在参数空间中进行采样,以保证能够覆盖到潜在的更优解。2) 策略评估方法:如何快速准确地评估候选策略的性能,以便选择最佳策略。3) 集成方式:如何将ExploRLer无缝集成到现有的On-Policy算法中,而不会引入过多的计算开销。
🖼️ 关键图片
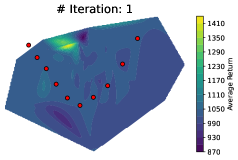
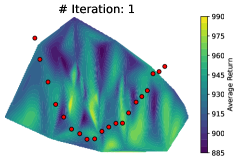
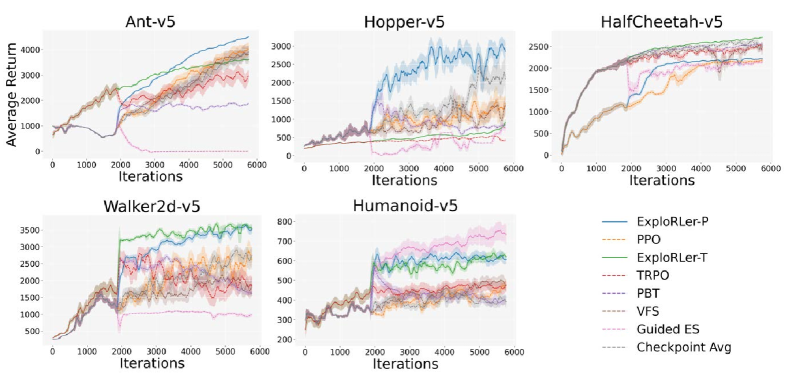
📊 实验亮点
ExploRLer在多个复杂连续控制环境中取得了显著的性能提升,例如在MuJoCo benchmark中,ExploRLer在多个任务上超越了PPO和TRPO等基线算法。实验结果表明,ExploRLer能够在不增加梯度更新次数的情况下,有效地提高On-Policy强化学习的效率和性能,验证了迭代级别参数空间探索的有效性。
🎯 应用场景
ExploRLer可应用于各种需要高效On-Policy强化学习的场景,例如机器人控制、游戏AI、自动驾驶等。通过更有效地探索参数空间,ExploRLer可以帮助智能体更快地学习到最优策略,提高任务完成效率和性能。该方法尤其适用于奖励函数稀疏或难以建模的复杂环境。
📄 摘要(原文)
Policy-gradient methods such as Proximal Policy Optimization (PPO) are typically updated along a single stochastic gradient direction, leaving the rich local structure of the parameter space unexplored. Previous work has shown that the surrogate gradient is often poorly correlated with the true reward landscape. Building on this insight, we visualize the parameter space spanned by policy checkpoints within an iteration and reveal that higher performing solutions often lie in nearby unexplored regions. To exploit this opportunity, we introduce ExploRLer, a pluggable pipeline that seamlessly integrates with on-policy algorithms such as PPO and TRPO, systematically probing the unexplored neighborhoods of surrogate on-policy gradient updates. Without increasing the number of gradient updates, ExploRLer achieves significant improvements over baselines in complex continuous control environments. Our results demonstrate that iteration-level exploration provides a practical and effective way to strengthen on-policy reinforcement learning and offer a fresh perspective on the limitations of the surrogate objective.