Distillation of Large Language Models via Concrete Score Matching
作者: Yeongmin Kim, Donghyeok Shin, Mina Kang, Byeonghu Na, Il-Chul Moon
分类: cs.LG, cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出Concrete Score Distillation,解决LLM蒸馏中logit信息损失和解空间限制问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 Concrete Score Matching 模型压缩 logit蒸馏
📋 核心要点
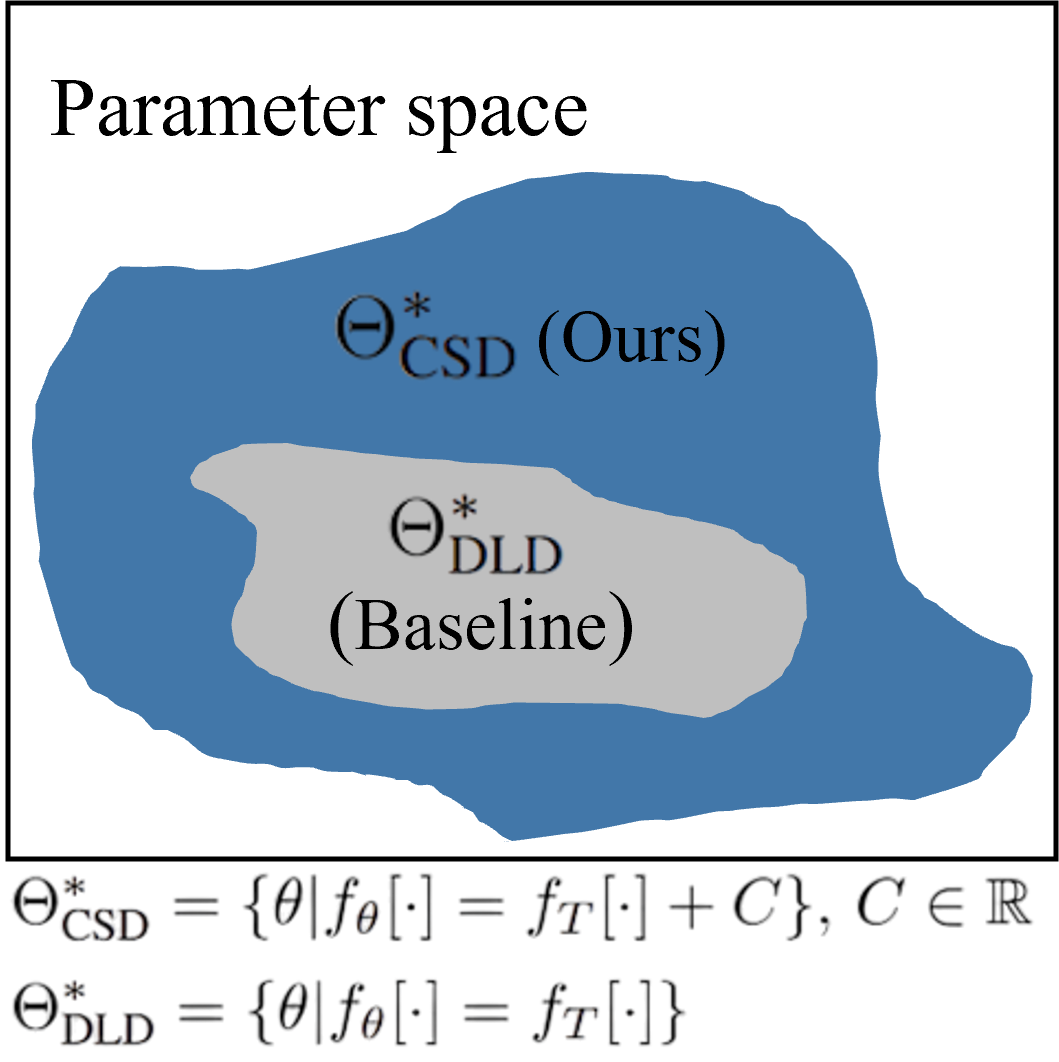
- 现有知识蒸馏方法依赖softmax匹配概率,损失了logit中的关键信息,而直接logit蒸馏忽略了logit平移不变性,限制了解空间。
- 论文提出Concrete Score Distillation (CSD),通过离散分数匹配对齐学生和教师模型间的相对logit差异,克服了现有方法的局限性。
- 实验表明,CSD在指令跟随和任务特定蒸馏上均优于现有方法,实现了更好的保真度-多样性平衡,并可与on-policy方法结合。
📝 摘要(中文)
大型语言模型(LLM)性能卓越但部署成本高昂,因此知识蒸馏(KD)对于高效推理至关重要。现有的KD目标通常通过softmax匹配学生和教师的概率,这模糊了宝贵的logit信息。虽然直接logit蒸馏(DLD)缓解了softmax平滑,但它未能考虑logit平移不变性,从而限制了解空间。我们提出Concrete Score Distillation(CSD),这是一种离散分数匹配目标,克服了softmax引起的平滑以及对最优解集的限制。我们解决了自回归LLM中离散分数匹配的训练不稳定性和二次复杂度问题,由此产生的CSD目标以灵活的权重对齐学生和教师之间所有词汇对的相对logit差异。我们在任务无关的指令跟随和使用GPT-2-1.5B、OpenLLaMA-7B和GEMMA-7B-IT的任务特定蒸馏上评估CSD。实验表明,CSD始终优于最近的KD目标,实现了良好的保真度-多样性权衡,并且在与on-policy技术结合使用时产生互补的增益,证明了其LLM蒸馏的可扩展性和有效性。
🔬 方法详解
问题定义:现有的大型语言模型知识蒸馏方法主要存在两个痛点。一是基于softmax的蒸馏方法会平滑logit信息,导致学生模型无法充分学习教师模型的细粒度知识。二是直接logit蒸馏虽然避免了softmax平滑,但忽略了logit平移不变性,限制了学生模型的解空间,影响了蒸馏效果。
核心思路:论文的核心思路是使用Concrete Score Matching来对齐学生模型和教师模型的logit差异。具体来说,CSD旨在最小化学生模型和教师模型在所有词汇对上的相对logit差异,从而保留了logit的细粒度信息,并允许学生模型在更大的解空间中进行学习。这种方法通过直接匹配logit的梯度(即score)来避免softmax带来的信息损失。
技术框架:CSD方法主要包含以下几个步骤:首先,计算教师模型和学生模型在给定输入下的logit输出。然后,计算所有词汇对之间的相对logit差异。接着,使用Concrete Score Matching目标函数来对齐学生模型和教师模型的相对logit差异。最后,通过优化该目标函数来训练学生模型。该框架的关键在于Concrete Score Matching目标函数的设计,它能够有效地对齐logit差异,并解决训练不稳定性和计算复杂度问题。
关键创新:论文最重要的技术创新点在于提出了Concrete Score Distillation (CSD) 方法,这是一种基于离散分数匹配的知识蒸馏方法。与传统的基于softmax的蒸馏方法相比,CSD能够更好地保留logit的细粒度信息,并允许学生模型在更大的解空间中进行学习。此外,论文还解决了离散分数匹配在自回归LLM中训练不稳定和计算复杂度高的问题。
关键设计:CSD的关键设计包括:1) 使用Concrete relaxation来近似离散变量,从而实现可微的优化。2) 设计了一种灵活的权重方案,可以根据不同的任务和模型来调整不同词汇对的重要性。3) 采用了一种高效的计算方法,降低了离散分数匹配的计算复杂度。4) 目标函数的设计允许灵活地选择mode-seeking或mode-covering的蒸馏策略。
🖼️ 关键图片
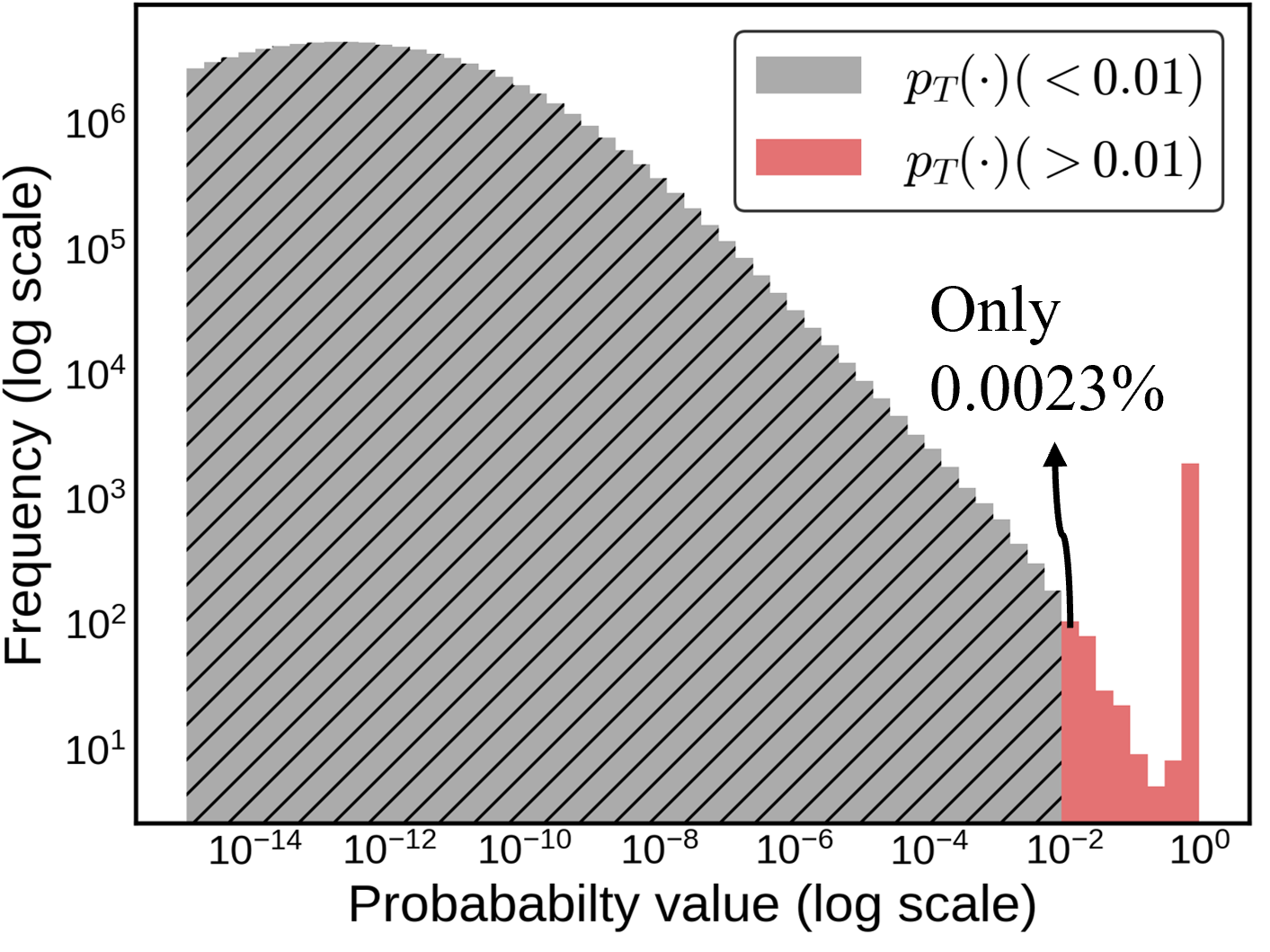

📊 实验亮点
实验结果表明,CSD在多个任务上均优于现有的知识蒸馏方法。例如,在使用GPT-2-1.5B作为教师模型时,CSD在指令跟随任务上取得了显著的性能提升。此外,CSD在OpenLLaMA-7B和GEMMA-7B-IT上的实验也表明,该方法具有良好的可扩展性和泛化能力。更重要的是,CSD可以与on-policy技术结合使用,进一步提升蒸馏效果。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的压缩和加速,降低LLM的部署成本,使其能够在资源受限的设备上运行。例如,可以将大型预训练模型蒸馏成更小的模型,部署在移动设备或边缘服务器上,从而实现高效的自然语言处理应用。此外,该方法还可以用于个性化模型的训练,通过蒸馏用户特定的数据来定制模型。
📄 摘要(原文)
Large language models (LLMs) deliver remarkable performance but are costly to deploy, motivating knowledge distillation (KD) for efficient inference. Existing KD objectives typically match student and teacher probabilities via softmax, which blurs valuable logit information. While direct logit distillation (DLD) mitigates softmax smoothing, it fails to account for logit shift invariance, thereby restricting the solution space. We propose Concrete Score Distillation (CSD), a discrete score-matching objective that overcomes both softmax-induced smoothing and restrictions on the optimal solution set. We resolve the training instability and quadratic complexity of discrete score-matching in autoregressive LLMs, and the resulting CSD objective aligns relative logit differences across all vocabulary pairs between student and teacher with flexible weighting. We provide both mode-seeking and mode-covering instances within our framework and evaluate CSD on task-agnostic instruction-following and task-specific distillation using GPT-2-1.5B, OpenLLaMA-7B, and GEMMA-7B-IT. Experiments show that CSD consistently surpasses recent KD objectives, achieves favorable fidelity-diversity trade-offs, and yields complementary gains when combined with on-policy techniques, demonstrating its scalability and effectiveness for LLM distillation.