MIDAS: Misalignment-based Data Augmentation Strategy for Imbalanced Multimodal Learning
作者: Seong-Hyeon Hwang, Soyoung Choi, Steven Euijong Whang
分类: cs.LG
发布日期: 2025-09-30
备注: Accepted to NeurIPS 2025
💡 一句话要点
提出MIDAS,通过不一致数据增强解决多模态不平衡学习问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 数据增强 模态不平衡 置信度学习 弱模态加权 难样本挖掘 跨模态融合
📋 核心要点
- 多模态学习中,模型易过度依赖优势模态,忽略弱势模态的信息,导致性能瓶颈。
- MIDAS通过生成模态间语义不一致的错位样本,并结合置信度进行标记,迫使模型学习矛盾信息。
- 实验表明,MIDAS在多个多模态分类任务上显著优于现有方法,有效缓解了模态不平衡问题。
📝 摘要(中文)
多模态模型常常过度依赖主导模态,导致性能未达到最优。现有工作主要集中于修改训练目标或优化过程,而以数据为中心的解决方案仍未被充分探索。我们提出了MIDAS,一种新颖的数据增强策略,它生成具有语义不一致跨模态信息的错位样本,并使用单模态置信度分数进行标记,以迫使模型从矛盾信号中学习。然而,这种基于置信度的标记仍然可能偏向于更自信的模态。为了解决这个问题,我们在错位样本中引入了弱模态加权,动态地增加置信度最低的模态的损失权重,从而帮助模型充分利用较弱的模态。此外,当错位特征与对齐特征表现出更大的相似性时,这些错位样本会带来更大的挑战,从而使模型能够更好地区分不同类别。为了利用这一点,我们提出了难样本加权,优先考虑这种语义上模棱两可的错位样本。在多个多模态分类基准上的实验表明,MIDAS在解决模态不平衡问题方面显著优于相关基线。
🔬 方法详解
问题定义:论文旨在解决多模态学习中由于模态间信息量不平衡,导致模型过度依赖优势模态,而忽略弱势模态的问题。现有方法主要集中在修改训练目标或优化过程,缺乏有效的数据增强策略来平衡模态信息。
核心思路:MIDAS的核心思路是通过生成模态间语义不一致的错位样本,并利用单模态置信度进行标记,从而迫使模型从矛盾信号中学习。通过这种方式,模型需要更加关注弱势模态的信息,以区分真实样本和错位样本。
技术框架:MIDAS主要包含以下几个阶段:1) 错位样本生成:通过随机组合不同样本的不同模态特征来生成错位样本。2) 置信度标记:使用单模态模型的置信度作为错位样本的标签,引导模型学习。3) 弱模态加权:动态调整损失函数中弱势模态的权重,促使模型更多地关注弱势模态。4) 难样本加权:对与原始对齐样本更相似的错位样本赋予更高的权重,增加训练难度。
关键创新:MIDAS的关键创新在于其数据增强策略,通过生成模态间语义不一致的错位样本,并结合置信度标记和加权策略,有效地解决了多模态学习中的模态不平衡问题。与现有方法不同,MIDAS从数据层面入手,无需修改训练目标或优化过程。
关键设计:1) 错位样本生成:随机选择两个样本,将一个样本的模态A特征与另一个样本的模态B特征进行组合。2) 置信度标记:使用预训练的单模态模型对错位样本进行预测,并将预测置信度作为标签。3) 弱模态加权:根据每个样本的模态置信度,动态调整损失函数中每个模态的权重。具体来说,置信度低的模态会被赋予更高的权重。4) 难样本加权:计算错位样本与原始对齐样本的特征相似度,相似度越高的样本被赋予更高的权重。
🖼️ 关键图片

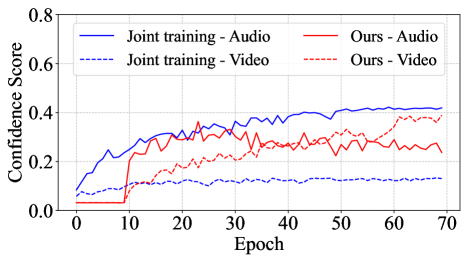

📊 实验亮点
实验结果表明,MIDAS在多个多模态分类基准数据集上显著优于现有方法。例如,在CMU-MOSEI数据集上,MIDAS相比基线方法提升了超过5%。此外,消融实验验证了弱模态加权和难样本加权策略的有效性。
🎯 应用场景
MIDAS可应用于各种多模态学习任务,例如视频理解、情感分析、医学诊断等。通过解决模态不平衡问题,MIDAS可以提高模型的鲁棒性和泛化能力,使其在实际应用中表现更好。未来,该方法可以进一步扩展到更多模态和更复杂的任务中。
📄 摘要(原文)
Multimodal models often over-rely on dominant modalities, failing to achieve optimal performance. While prior work focuses on modifying training objectives or optimization procedures, data-centric solutions remain underexplored. We propose MIDAS, a novel data augmentation strategy that generates misaligned samples with semantically inconsistent cross-modal information, labeled using unimodal confidence scores to compel learning from contradictory signals. However, this confidence-based labeling can still favor the more confident modality. To address this within our misaligned samples, we introduce weak-modality weighting, which dynamically increases the loss weight of the least confident modality, thereby helping the model fully utilize weaker modality. Furthermore, when misaligned features exhibit greater similarity to the aligned features, these misaligned samples pose a greater challenge, thereby enabling the model to better distinguish between classes. To leverage this, we propose hard-sample weighting, which prioritizes such semantically ambiguous misaligned samples. Experiments on multiple multimodal classification benchmarks demonstrate that MIDAS significantly outperforms related baselines in addressing modality imbalance.