Learning to Reason as Action Abstractions with Scalable Mid-Training RL
作者: Shenao Zhang, Donghan Yu, Yihao Feng, Bowen Jin, Zhaoran Wang, John Peebles, Zirui Wang
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-09-30 (更新: 2025-10-11)
💡 一句话要点
提出RA3算法,通过可扩展的中期训练强化学习提升代码生成任务性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 动作抽象 代码生成 中期训练 大型语言模型
📋 核心要点
- 现有方法难以充分利用大型语言模型在强化学习中的潜力,尤其是在代码生成等复杂任务中。
- RA3算法通过引入中期训练阶段,学习紧凑的动作抽象空间,从而提升强化学习的效率和性能。
- 实验表明,RA3在代码生成任务上显著优于现有方法,并在多个基准测试中实现了更快的收敛和更高的性能。
📝 摘要(中文)
大型语言模型在强化学习中表现出色,但要充分发挥其潜力,需要一个中期训练阶段。有效的中期训练阶段应识别出一组紧凑且有用的动作,并通过在线强化学习实现它们之间的快速选择。本文通过理论结果形式化了这种直觉,该结果描述了一个动作子空间,该子空间可以最大限度地减少修剪带来的值近似误差以及后续规划期间的强化学习误差。分析表明,中期训练效果的两个关键决定因素是:修剪效率,它塑造了初始强化学习策略的先验;以及它对强化学习收敛的影响,它决定了该策略可以通过在线交互改进的程度。这些结果表明,当决策空间紧凑且有效范围较短时,中期训练最有效,突出了在动作抽象空间而不是原始动作空间中操作的重要性。基于这些见解,我们提出了一种可扩展的中期训练算法,即推理即动作抽象(RA3)。具体来说,我们推导出一个顺序变分下界,并通过迭代地发现时间一致的潜在结构(通过强化学习)来优化它,然后在引导数据上进行微调。在代码生成任务上的实验证明了我们方法的有效性。在多个基础模型中,RA3在HumanEval和MBPP上的平均性能比基础模型和下一个token预测基线提高了8和4个点。此外,RA3在HumanEval+、MBPP+、LiveCodeBench和Codeforces上的RLVR中实现了更快的收敛速度和更高的渐近性能。
🔬 方法详解
问题定义:现有方法在利用大型语言模型进行强化学习时,面临着动作空间巨大、探索效率低下的问题,尤其是在代码生成等复杂任务中。直接在原始动作(例如,单个token)上进行强化学习会导致训练困难,收敛速度慢,最终性能不佳。因此,如何有效地利用大型语言模型的能力,学习有意义的动作抽象,并加速强化学习过程,是一个亟待解决的问题。
核心思路:RA3的核心思路是通过中期训练阶段,学习一个紧凑的动作抽象空间。这个动作抽象空间将原始动作组合成更高级别的、具有时间一致性的动作,从而降低了决策空间的维度,提高了探索效率。通过在抽象动作空间上进行强化学习,可以更快地找到最优策略,并获得更高的性能。这种设计借鉴了分层强化学习的思想,但更侧重于利用大型语言模型的先验知识来指导动作抽象的学习。
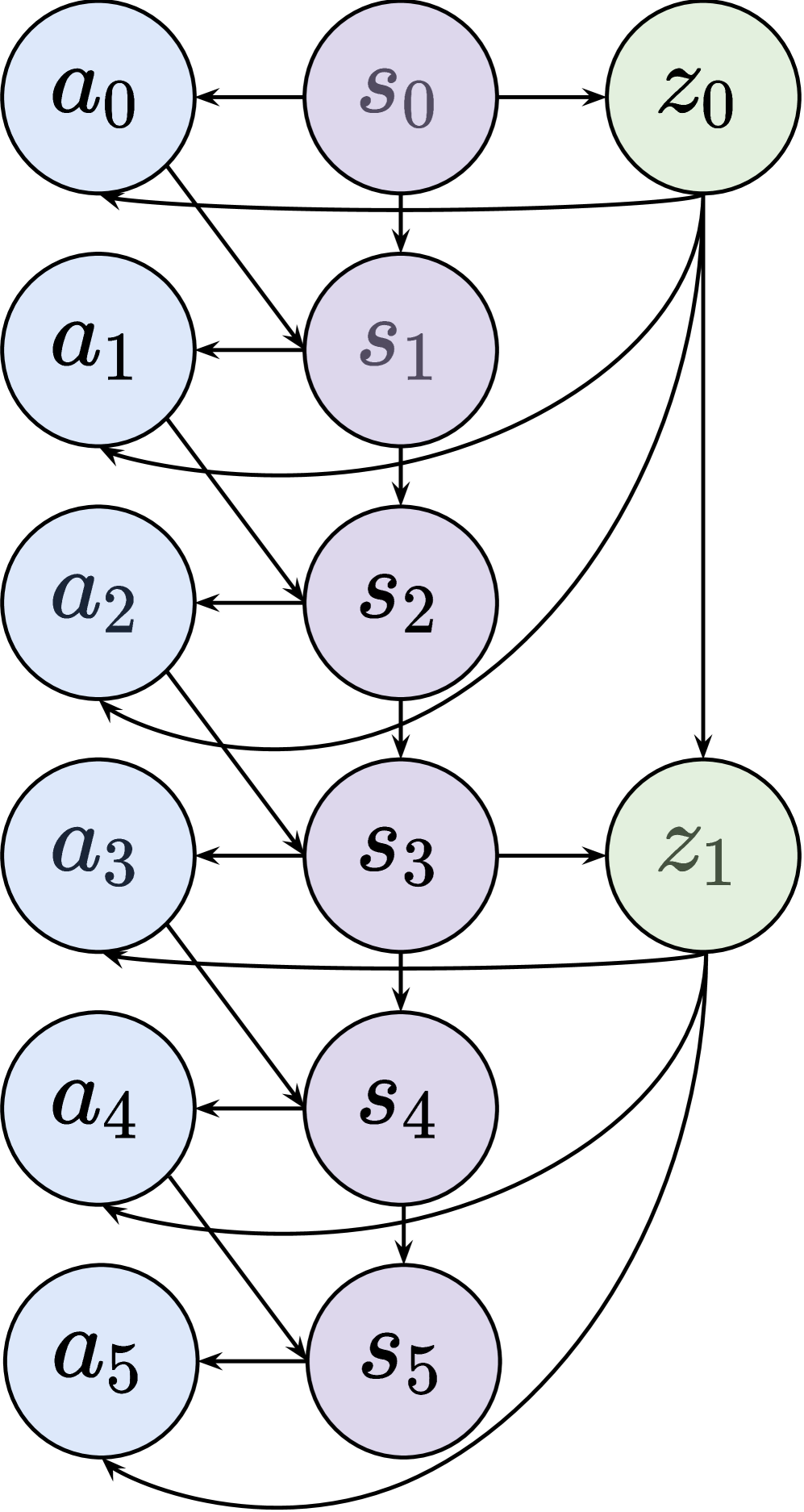
技术框架:RA3算法包含两个主要阶段:动作抽象学习阶段和策略优化阶段。在动作抽象学习阶段,RA3通过迭代地发现时间一致的潜在结构来学习动作抽象。具体来说,RA3首先使用强化学习来探索环境,然后利用探索数据来学习一个变分自编码器,该自编码器将原始动作序列映射到潜在的动作抽象空间。在策略优化阶段,RA3在学习到的动作抽象空间上进行强化学习,以优化策略。
关键创新:RA3的关键创新在于提出了一种可扩展的中期训练算法,该算法能够有效地学习时间一致的动作抽象。与传统的动作抽象方法相比,RA3能够利用大型语言模型的先验知识来指导动作抽象的学习,从而提高了学习效率和性能。此外,RA3还推导出了一个顺序变分下界,并使用该下界来优化动作抽象的学习过程。
关键设计:RA3的关键设计包括:1) 使用变分自编码器来学习动作抽象空间;2) 使用强化学习来探索环境并收集数据;3) 使用顺序变分下界来优化动作抽象的学习过程;4) 在学习到的动作抽象空间上进行强化学习以优化策略。具体的参数设置和网络结构取决于具体的任务和数据集,但通常会使用Transformer等常用的神经网络结构。
🖼️ 关键图片

📊 实验亮点
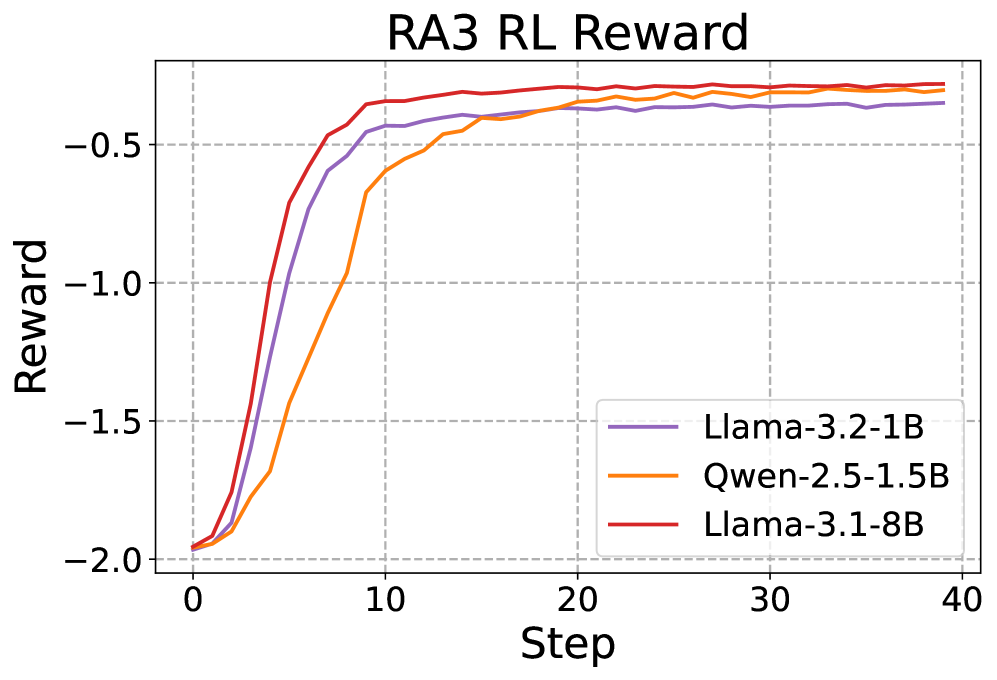
RA3算法在HumanEval和MBPP代码生成任务上,相比基础模型和next-token预测基线,平均性能分别提升了8和4个点。在HumanEval+、MBPP+、LiveCodeBench和Codeforces等基准测试中,RA3在强化学习过程中实现了更快的收敛速度和更高的渐近性能,证明了其在复杂代码生成任务上的有效性。
🎯 应用场景
RA3算法在代码生成、机器人控制、游戏AI等领域具有广泛的应用前景。通过学习有效的动作抽象,RA3可以帮助智能体更高效地解决复杂任务,并提高其泛化能力。此外,RA3还可以用于开发更智能的自动化工具和更强大的AI助手。
📄 摘要(原文)
Large language models excel with reinforcement learning (RL), but fully unlocking this potential requires a mid-training stage. An effective mid-training phase should identify a compact set of useful actions and enable fast selection among them through online RL. We formalize this intuition by presenting the first theoretical result on how mid-training shapes post-training: it characterizes an action subspace that minimizes both the value approximation error from pruning and the RL error during subsequent planning. Our analysis reveals two key determinants of mid-training effectiveness: pruning efficiency, which shapes the prior of the initial RL policy, and its impact on RL convergence, which governs the extent to which that policy can be improved via online interactions. These results suggest that mid-training is most effective when the decision space is compact and the effective horizon is short, highlighting the importance of operating in the space of action abstractions rather than primitive actions. Building on these insights, we propose Reasoning as Action Abstractions (RA3), a scalable mid-training algorithm. Specifically, we derive a sequential variational lower bound and optimize it by iteratively discovering temporally-consistent latent structures via RL, followed by fine-tuning on the bootstrapped data. Experiments on code generation tasks demonstrate the effectiveness of our approach. Across multiple base models, RA3 improves the average performance on HumanEval and MBPP by 8 and 4 points over the base model and the next-token prediction baseline. Furthermore, RA3 achieves faster convergence and higher asymptotic performance in RLVR on HumanEval+, MBPP+, LiveCodeBench, and Codeforces.