OPPO: Accelerating PPO-based RLHF via Pipeline Overlap
作者: Kaizhuo Yan, Yingjie Yu, Yifan Yu, Haizhong Zheng, Fan Lai
分类: cs.LG
发布日期: 2025-09-30
备注: Kaizhuo Yan and Yingjie Yu contributed equally to this work
💡 一句话要点
OPPO:通过流水线重叠加速基于PPO的RLHF训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 近端策略优化 大型语言模型 流水线优化
📋 核心要点
- 现有基于PPO的RLHF训练由于模型间的依赖关系和长尾响应,效率低下,成为对齐LLM的瓶颈。
- OPPO通过步内和步间流水线重叠,使上游模型输出能被下游模型提前利用,并缓解长尾响应带来的延迟。
- 实验表明,OPPO在不影响训练收敛性的前提下,显著加速了PPO-based RLHF训练,并提高了GPU利用率。
📝 摘要(中文)
基于近端策略优化(PPO)的从人类反馈中强化学习(RLHF)是使大型语言模型(LLM)与人类偏好对齐的常用范例。然而,由于顺序多模型依赖关系(例如,奖励模型依赖于actor模型的输出)和长尾响应长度(其中一些长响应拖延了阶段完成),其训练流水线效率低下。我们提出了OPPO,一种新颖、轻量级且模型无关的基于PPO的RLHF框架,通过重叠流水线执行来提高训练效率。OPPO引入了两项新技术:(1)步内重叠,它以适当大小的块流式传输上游模型输出(例如,actor模型),使下游模型(例如,奖励模型)能够在上游继续解码时开始预填充;(2)步间重叠,它自适应地过度提交一些提示,并将长生成推迟到未来的步骤,从而减轻尾部延迟,而不会丢弃部分工作。OPPO可以轻松地与现有的PPO实现集成,只需更改几行代码。广泛的评估表明,OPPO将基于PPO的RLHF训练加速了1.8倍-2.8倍,并将GPU利用率提高了1.4倍-2.1倍,而不会影响训练收敛性。
🔬 方法详解
问题定义:论文旨在解决基于PPO的RLHF训练中存在的效率瓶颈问题。现有方法由于多模型之间的顺序依赖关系,以及生成文本长度的不确定性(长尾效应),导致训练过程中的GPU利用率不高,整体训练时间较长。特别是,奖励模型需要等待Actor模型生成完整文本后才能进行评估,造成了资源浪费。
核心思路:OPPO的核心思路是通过流水线重叠来提高训练效率。具体来说,它将PPO训练过程中的不同阶段(例如,Actor模型生成和Reward模型评估)进行并行化,使得下游模型可以在上游模型完成之前就开始工作。通过这种方式,可以减少空闲时间,提高GPU利用率,并最终加速整个训练过程。
技术框架:OPPO框架主要包含两个关键技术:步内重叠和步间重叠。步内重叠是指在单个PPO训练步骤中,将Actor模型的输出以流式的方式传递给Reward模型,使得Reward模型可以提前开始预填充,而无需等待Actor模型生成完整文本。步间重叠是指自适应地提交多个prompt,并将耗时较长的生成任务延迟到后续步骤中执行,从而缓解长尾效应带来的延迟。
关键创新:OPPO的关键创新在于其流水线重叠的思想,以及步内和步间重叠的具体实现方式。与传统的PPO训练方法相比,OPPO能够更有效地利用GPU资源,减少训练时间。此外,OPPO的设计具有模型无关性,可以方便地集成到现有的PPO实现中。
关键设计:OPPO的关键设计包括:(1) Actor模型输出的流式传输机制,需要合理划分数据块的大小,以平衡通信开销和预填充的效率。(2) 步间重叠中的自适应提交策略,需要根据历史生成时间来预测prompt的生成时间,并动态调整提交数量。(3) 延迟生成任务的处理机制,需要保证延迟任务最终能够完成,并且不会影响训练的收敛性。论文中并未详细说明具体的参数设置和损失函数,但强调了其与现有PPO实现的兼容性。
🖼️ 关键图片


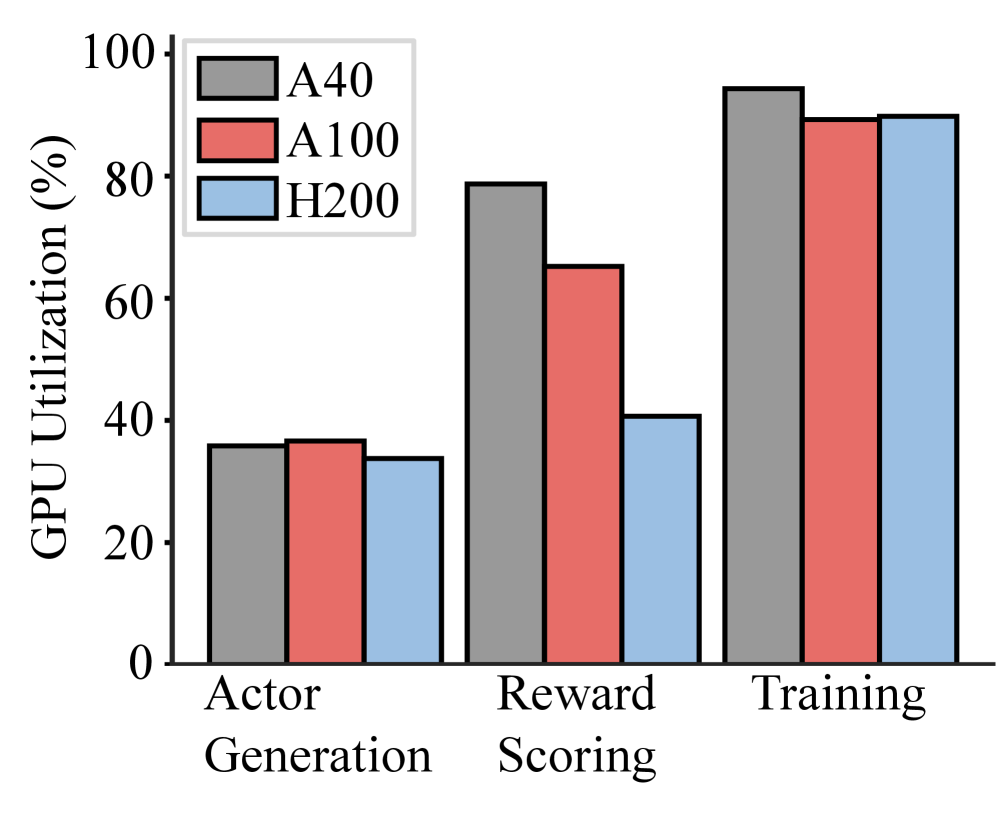
📊 实验亮点
OPPO通过步内和步间流水线重叠,在不影响训练收敛性的前提下,将基于PPO的RLHF训练加速了1.8倍-2.8倍,并将GPU利用率提高了1.4倍-2.1倍。这些结果表明OPPO是一种高效且实用的RLHF训练加速方法。
🎯 应用场景
OPPO框架可广泛应用于各种需要使用RLHF对齐LLM的场景,例如对话系统、文本生成、代码生成等。通过提高训练效率,OPPO可以降低训练成本,加速LLM的开发和部署,并最终提升LLM在实际应用中的性能和用户体验。该研究对于推动LLM的普及和应用具有重要意义。
📄 摘要(原文)
Proximal Policy Optimization (PPO)-based reinforcement learning from human feedback (RLHF) is a widely adopted paradigm for aligning large language models (LLMs) with human preferences. However, its training pipeline suffers from substantial inefficiencies due to sequential multi-model dependencies (e.g., reward model depends on actor outputs) and long-tail response lengths, where a few long responses straggle the stage completion. We present OPPO, a novel, lightweight, and model-agnostic PPO-based RLHF framework that improves training efficiency by overlapping pipeline execution. OPPO introduces two novel techniques: (1) Intra-step overlap, which streams upstream model outputs (e.g., actor model) in right-sized chunks, enabling the downstream model (e.g., reward) to begin prefill while the upstream continues decoding; and (2) Inter-step overlap, which adaptively overcommits a few prompts and defers long generations to future steps, mitigating tail latency without discarding partial work. OPPO integrates easily with existing PPO implementations with a few lines of code change. Extensive evaluations show that OPPO accelerates PPO-based RLHF training by $1.8 \times-2.8 \times$ and improves GPU utilization by $1.4 \times-2.1 \times$ without compromising training convergence.