Boundary-to-Region Supervision for Offline Safe Reinforcement Learning
作者: Huikang Su, Dengyun Peng, Zifeng Zhuang, YuHan Liu, Qiguang Chen, Donglin Wang, Qinghe Liu
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-09-30
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出B2R框架,通过非对称条件反射解决离线安全强化学习中的安全约束问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线安全强化学习 安全约束 序列模型 非对称调节 成本信号重alignment
📋 核心要点
- 现有离线安全强化学习方法在处理返回-成本和成本-成本时采用对称调节,忽略了两者本质上的不对称性,导致安全约束不可靠。
- B2R框架通过成本信号重alignment实现非对称调节,将成本-成本重新定义为安全预算下的边界约束,统一成本分布并保留奖励结构。
- 实验结果表明,B2R在多个安全关键任务中显著提升了安全约束的满足程度,并获得了更好的奖励性能。
📝 摘要(中文)
离线安全强化学习旨在从静态数据集中学习满足预定义安全约束的策略。现有的基于序列模型的方法对返回-成本 (return-to-go, RTG) 和成本-成本 (cost-to-go, CTG) 使用对称的输入 tokens 来调节动作生成,忽略了它们内在的不对称性:RTG 作为一个灵活的性能目标,而 CTG 应该代表一个严格的安全边界。这种对称调节导致不可靠的约束满足,尤其是在遇到分布外的成本轨迹时。为了解决这个问题,我们提出了边界到区域 (Boundary-to-Region, B2R) 框架,该框架通过成本信号重alignment实现非对称调节。B2R 将 CTG 重新定义为固定安全预算下的边界约束,统一了所有可行轨迹的成本分布,同时保留了奖励结构。结合旋转位置嵌入,它增强了安全区域内的探索。实验结果表明,B2R 在 38 个安全关键任务中的 35 个中满足了安全约束,同时实现了优于基线方法的奖励性能。这项工作突出了对称 token 调节的局限性,并为将序列模型应用于安全强化学习建立了一种新的理论和实践方法。
🔬 方法详解
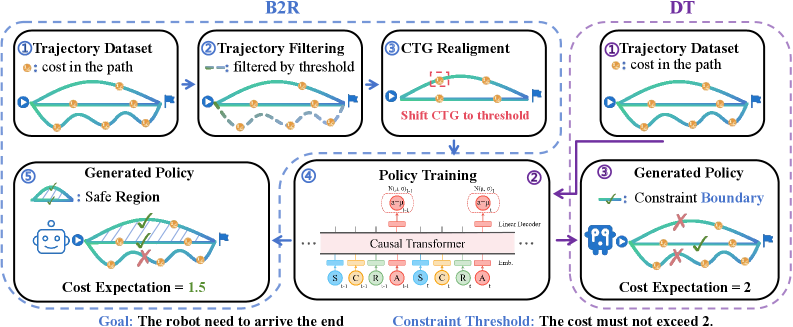
问题定义:离线安全强化学习旨在从静态数据集中学习满足预定义安全约束的策略。现有方法,特别是基于序列模型的方法,在处理返回-成本 (RTG) 和成本-成本 (CTG) 时,采用对称的输入 tokens 来调节动作生成。这种对称性忽略了 RTG 和 CTG 本质上的不对称性:RTG 是一个灵活的性能目标,而 CTG 应该代表一个严格的安全边界。这种对称调节导致不可靠的约束满足,尤其是在遇到分布外的成本轨迹时。现有方法难以保证策略的安全性,尤其是在面对未知的成本轨迹时。
核心思路:论文的核心思路是通过非对称调节来区分 RTG 和 CTG 的作用。具体来说,论文将 CTG 重新定义为固定安全预算下的边界约束,从而统一所有可行轨迹的成本分布,同时保留奖励结构。通过这种方式,模型可以更准确地学习到安全边界,从而提高策略的安全性。这种设计旨在使模型能够更可靠地满足安全约束,即使在面对分布外的成本轨迹时也能保持安全。
技术框架:B2R 框架主要包含以下几个关键步骤:1) 成本信号重alignment:将 CTG 重新定义为固定安全预算下的边界约束。2) 非对称调节:使用不同的方式处理 RTG 和 CTG,以反映它们不同的作用。3) 旋转位置嵌入:增强安全区域内的探索。整体流程是,首先对离线数据集进行预处理,将 CTG 转换为边界约束。然后,使用序列模型学习策略,其中 RTG 和 CTG 的处理方式不同。最后,使用学习到的策略进行决策,确保满足安全约束。
关键创新:该论文最重要的技术创新点在于提出了 Boundary-to-Region (B2R) 框架,该框架通过成本信号重alignment实现非对称调节。与现有方法的本质区别在于,B2R 明确区分了 RTG 和 CTG 的作用,并将 CTG 视为一个严格的安全边界,从而提高了策略的安全性。现有方法通常将 RTG 和 CTG 对待为对称的输入,忽略了它们在安全强化学习中的不同作用。
关键设计:B2R 的关键设计包括:1) 将 CTG 重新定义为固定安全预算下的边界约束,这需要选择合适的安全预算值。2) 使用旋转位置嵌入来增强安全区域内的探索,这需要调整旋转位置嵌入的参数。3) 使用序列模型(例如 Transformer)来学习策略,这需要选择合适的网络结构和训练参数。论文中可能还涉及特定的损失函数设计,以鼓励模型学习到安全策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,B2R 框架在 38 个安全关键任务中的 35 个中满足了安全约束,显著优于基线方法。同时,B2R 在满足安全约束的前提下,实现了更高的奖励性能。这些结果表明,B2R 框架能够有效地提高离线安全强化学习的性能,使其能够更好地应用于实际场景。
🎯 应用场景
该研究成果可应用于各种安全攸关的强化学习任务中,例如自动驾驶、机器人控制、医疗决策等。在这些领域,确保策略的安全性至关重要,B2R框架能够有效地提高策略的安全性,从而降低事故发生的风险。此外,该研究还可以促进离线安全强化学习的发展,使其能够更好地应用于实际场景。
📄 摘要(原文)
Offline safe reinforcement learning aims to learn policies that satisfy predefined safety constraints from static datasets. Existing sequence-model-based methods condition action generation on symmetric input tokens for return-to-go and cost-to-go, neglecting their intrinsic asymmetry: return-to-go (RTG) serves as a flexible performance target, while cost-to-go (CTG) should represent a rigid safety boundary. This symmetric conditioning leads to unreliable constraint satisfaction, especially when encountering out-of-distribution cost trajectories. To address this, we propose Boundary-to-Region (B2R), a framework that enables asymmetric conditioning through cost signal realignment . B2R redefines CTG as a boundary constraint under a fixed safety budget, unifying the cost distribution of all feasible trajectories while preserving reward structures. Combined with rotary positional embeddings , it enhances exploration within the safe region. Experimental results show that B2R satisfies safety constraints in 35 out of 38 safety-critical tasks while achieving superior reward performance over baseline methods. This work highlights the limitations of symmetric token conditioning and establishes a new theoretical and practical approach for applying sequence models to safe RL. Our code is available at https://github.com/HuikangSu/B2R.