Expert Merging: Model Merging with Unsupervised Expert Alignment and Importance-Guided Layer Chunking
作者: Dengming Zhang, Xiaowen Ma, Zhenliang Ni, Zhenkai Wu, Han Shu, Xin Jiang, Xinghao Chen
分类: cs.LG
发布日期: 2025-09-30
🔗 代码/项目: GITHUB
💡 一句话要点
提出Expert Merging,通过无监督专家对齐和重要性引导的分层分块实现模型合并。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型合并 专家模型 无监督学习 多模态学习 大语言模型 参数高效 领域知识集成
📋 核心要点
- 现有模型合并方法或依赖手动调整,或忽略层间差异,导致性能受限且效率不高。
- Expert Merging通过学习层级系数对齐模型状态和logits,并引入重要性引导分块来优化参数分配。
- 实验表明,Expert Merging在多种LLM和MLLM上超越现有基线,甚至媲美监督混合训练。
📝 摘要(中文)
模型合并是一种将多个领域专家模型组合成单个模型的方法,它为大型语言模型(LLM)和多模态大型语言模型(MLLM)提供了扩展能力的可行途径,而无需联合训练或服务多个模型。然而,免训练方法依赖于手动调整的系数,而基于训练的方法主要对齐参数而不是下游任务行为,并且通常统一对待所有层,忽略了层间的异质性。我们引入了Expert Merging,这是一种轻量级训练方法,仅使用未标记的校准数据来学习一小组逐层系数。优化这些系数,以显式地将合并模型的隐藏状态和logits与相应专家的隐藏状态和logits对齐,并使用系数正则化器来保证稳定性,以及使用任务加权损失来实现可控的权衡。为了捕捉层间变化,Expert Merging++通过重要性引导的分块来增强此设计:一种归一化的层重要性度量,从学习的系数、任务向量幅度和参数计数中导出,将更多的分块系数分配给高重要性层,同时保持低重要性层的轻量级。结果是一种无标签、参数高效且可扩展的多专家模型合并方法,适用于LLM和MLLM。在MLLM骨干网络(InternVL和Qwen2-VL)和LLM骨干网络(Mistral)上,我们的方法超越了强大的免训练和基于训练的合并基线,Expert Merging++提供了进一步的增益,在某些情况下甚至超过了监督混合训练。
🔬 方法详解
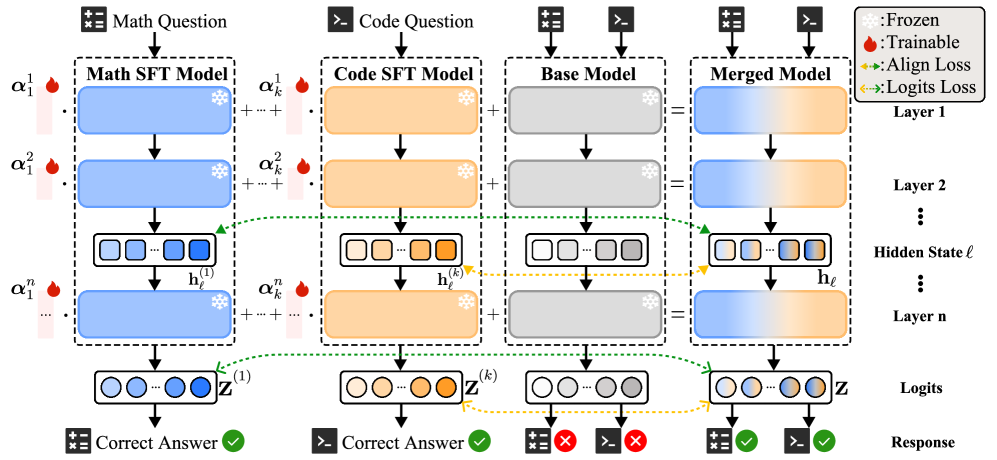
问题定义:模型合并旨在将多个在特定领域训练过的专家模型整合为一个通用模型,从而避免联合训练或同时部署多个模型的成本。现有方法的痛点在于:免训练方法依赖于手工调整的权重,缺乏灵活性;基于训练的方法通常直接对齐模型参数,忽略了模型在下游任务中的行为,并且对所有层一视同仁,未能充分利用层间异质性。
核心思路:Expert Merging的核心思路是通过学习一组逐层的系数,来显式地对齐合并后模型的隐藏状态和logits与各个专家模型的对应状态。这种方法关注的是模型在任务中的实际行为,而非仅仅是参数的对齐。同时,引入重要性引导的分块机制,根据各层的重要性动态分配参数,从而提高参数利用率。
技术框架:Expert Merging包含以下主要阶段:1) 专家模型准备:选择或训练多个领域专家模型。2) 校准数据准备:准备少量未标记的校准数据集。3) 系数学习:使用校准数据,通过优化损失函数学习逐层系数,损失函数包括状态对齐损失、logits对齐损失和系数正则化项。4) 模型合并:根据学习到的系数,将专家模型的参数进行加权合并。Expert Merging++在此基础上增加了重要性引导的分块机制。
关键创新:Expert Merging的关键创新在于:1) 基于行为对齐的模型合并:直接对齐隐藏状态和logits,而非仅仅对齐参数,更关注模型在任务中的实际表现。2) 重要性引导的分块:根据层的重要性动态分配参数,提高参数利用率和模型性能。3) 轻量级训练:仅需少量未标记数据即可完成系数学习,降低了训练成本。
关键设计:1) 状态对齐损失:衡量合并模型和专家模型在隐藏状态上的差异,鼓励合并模型学习专家的行为。2) Logits对齐损失:衡量合并模型和专家模型在logits上的差异,确保合并模型能够正确分类。3) 系数正则化:防止系数过大或过小,保证模型合并的稳定性。4) 重要性度量:综合考虑学习到的系数、任务向量幅度和参数计数,计算每一层的重要性。5) 分块策略:根据层的重要性,将模型分成不同大小的块,并为每个块分配独立的系数。
🖼️ 关键图片


📊 实验亮点
在MLLM(InternVL和Qwen2-VL)和LLM(Mistral)上进行的实验表明,Expert Merging显著优于现有的免训练和基于训练的模型合并方法。Expert Merging++进一步提升了性能,在某些情况下甚至超过了监督混合训练的效果,证明了其在模型合并方面的有效性和优越性。
🎯 应用场景
Expert Merging可应用于各种需要集成多个领域知识的场景,例如多语言翻译、多模态信息处理、以及需要快速适应新任务的机器人控制等。它能够以较低的成本将多个专家模型的优势结合起来,构建更强大、更通用的AI系统,并加速AI技术的落地应用。
📄 摘要(原文)
Model merging, which combines multiple domain-specialized experts into a single model, offers a practical path to endow Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) with broad capabilities without the cost of joint training or serving many models. However, training-free methods rely on hand-tuned coefficients, whereas training-based methods primarily align parameters rather than downstream task behavior and typically treat all layers uniformly, ignoring inter-layer heterogeneity. We introduce Expert Merging, a training-light method that learns a small set of layer-wise coefficients using only unlabeled calibration data. The coefficients are optimized to explicitly align the merged model's hidden states and logits with those of the corresponding experts, with a coefficient regularizer for stability and task-weighted losses for controllable trade-offs. To capture inter-layer variation, Expert Merging++ augments this design with importance-guided chunking: a normalized layer-importance metric, derived from learned coefficients, task-vector magnitudes, and parameter counts, allocates more chunk-wise coefficients to high-importance layers while keeping low-importance layers lightweight. The result is a label-free, parameter-efficient, and scalable approach to multi-expert model merging across LLMs and MLLMs. Across MLLM backbones (InternVL and Qwen2-VL) and the LLM backbone (Mistral), our method surpasses strong training-free and training-based merging baselines, with Expert Merging++ delivering further gains and, in some cases, even exceeding supervised Mixture Training. The source code is available at https://github.com/Littleor/ExpertMerging.