Layer-wise dynamic rank for compressing large language models
作者: Zhendong Mi, Bian Sun, Grace Li Zhang, Shaoyi Huang
分类: cs.LG
发布日期: 2025-09-30 (更新: 2025-10-04)
备注: 10 pages, 5 figures
💡 一句话要点
提出D-Rank:一种层间动态秩分配的LLM压缩框架,提升压缩性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 奇异值分解 动态秩分配 模型优化 后训练压缩
📋 核心要点
- 现有LLM压缩方法忽略了层间信息密度差异,对所有层采用统一压缩率,导致压缩性能受限。
- D-Rank通过有效秩度量信息密度,并使用拉格朗日乘数优化,动态分配各层压缩秩,提升压缩效率。
- 实验表明,D-Rank在多种LLM和压缩率下,显著优于现有SVD压缩方法,降低困惑度并提高推理精度。
📝 摘要(中文)
大型语言模型(LLMs)的规模迅速增长,带来了严重的内存和计算挑战,阻碍了它们的部署。基于奇异值分解(SVD)的压缩已成为一种有吸引力的LLMs后训练压缩技术,但大多数现有方法在所有层上应用统一的压缩率,隐含地假设了各层中包含的同质信息。这忽略了LLMs中观察到的显著的层内异质性,其中中间层倾向于编码更丰富的信息,而早期和晚期层则更加冗余。在这项工作中,我们重新审视了现有的基于SVD的压缩方法,并提出了D-Rank,一个具有层间平衡动态秩分配的LLMs压缩框架。我们首先引入有效秩作为一种原则性度量来衡量权重矩阵的信息密度,然后通过基于拉格朗日乘数的优化方案来分配秩,以便在固定的压缩率下自适应地为具有更高信息密度的组分配更多容量。此外,我们重新平衡注意力层之间分配的秩,以考虑它们的不同重要性,并将D-Rank扩展到具有分组查询注意力的最新LLMs。在具有不同规模的各种LLMs上,跨多个压缩率进行的大量实验表明,D-Rank始终优于SVD-LLM、ASVD和Basis Sharing,在C4数据集上以20%的压缩率使用LLaMA-3-8B模型实现了超过15的更低困惑度,并且在40%的压缩率下使用LLaMA-7B模型实现了高达5%的更高零样本推理精度,同时实现了更高的吞吐量。
🔬 方法详解
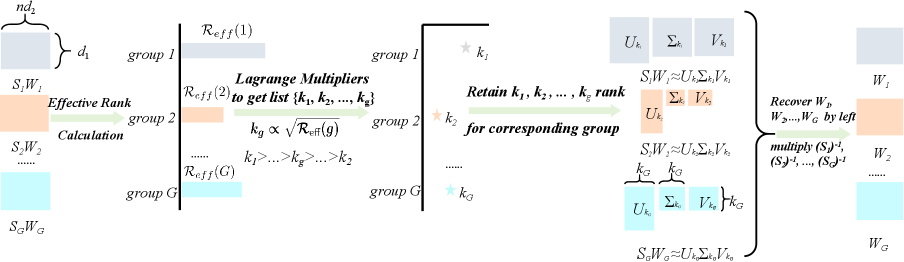
问题定义:现有基于SVD的LLM压缩方法通常采用统一的压缩率,忽略了不同层之间信息密度的差异。这种均匀压缩策略导致信息丰富的层压缩不足,而冗余层过度压缩,最终影响整体模型性能。因此,如何根据各层的信息密度自适应地分配压缩资源是需要解决的关键问题。
核心思路:D-Rank的核心思路是根据每一层权重矩阵的信息密度动态地分配压缩秩。信息密度高的层分配更高的秩,以保留更多信息;信息密度低的层分配较低的秩,以实现更高的压缩率。通过这种方式,D-Rank能够在固定压缩率下,最大化压缩后模型的性能。
技术框架:D-Rank框架主要包含以下几个阶段: 1. 有效秩计算:使用有效秩作为衡量权重矩阵信息密度的指标。 2. 秩分配优化:利用拉格朗日乘数法,在固定压缩率约束下,优化各层的秩分配,使得信息密度高的层获得更高的秩。 3. 注意力层重平衡:考虑到注意力层的重要性差异,对注意力层的秩进行重新平衡。 4. SVD压缩:根据分配的秩,对每一层的权重矩阵进行SVD分解和压缩。 5. 模型微调:对压缩后的模型进行微调,以恢复性能。
关键创新:D-Rank的关键创新在于提出了层间动态秩分配的策略,并引入有效秩作为信息密度的度量标准。与现有方法相比,D-Rank能够更有效地利用压缩资源,从而在相同的压缩率下获得更好的模型性能。此外,针对注意力层的重平衡机制也进一步提升了模型的性能。
关键设计: 1. 有效秩的计算:采用奇异值谱的熵来衡量有效秩,能够更准确地反映权重矩阵的信息密度。 2. 拉格朗日乘数优化:使用拉格朗日乘数法求解秩分配问题,保证在固定压缩率约束下,各层秩分配达到最优。 3. 注意力层重平衡:根据注意力头的数量和重要性,对注意力层的秩进行调整,以提升模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,D-Rank在多个LLM模型上均取得了显著的性能提升。例如,在LLaMA-3-8B模型上,以20%的压缩率在C4数据集上实现了超过15的更低困惑度。在LLaMA-7B模型上,以40%的压缩率实现了高达5%的更高零样本推理精度。同时,D-Rank还提升了模型的吞吐量,使其更适合实际应用。
🎯 应用场景
D-Rank可应用于各种大型语言模型的压缩,尤其适用于资源受限的场景,如移动设备、边缘计算和嵌入式系统。通过降低模型大小和计算复杂度,D-Rank能够帮助LLM在这些平台上高效部署,从而推动LLM在自然语言处理、智能助手、机器翻译等领域的广泛应用。
📄 摘要(原文)
Large language models (LLMs) have rapidly scaled in size, bringing severe memory and computational challenges that hinder their deployment. Singular Value Decomposition (SVD)-based compression has emerged as an appealing post-training compression technique for LLMs, yet most existing methods apply a uniform compression ratio across all layers, implicitly assuming homogeneous information included in various layers. This overlooks the substantial intra-layer heterogeneity observed in LLMs, where middle layers tend to encode richer information while early and late layers are more redundant. In this work, we revisit the existing SVD-based compression method and propose D-Rank, a framework with layer-wise balanced Dynamic Rank allocation for LLMs compression. We first introduce effective rank as a principled metric to measure the information density of weight matrices, and then allocate ranks via a Lagrange multiplier-based optimization scheme to adaptively assign more capacity to groups with higher information density under a fixed compression ratio. Moreover, we rebalance the allocated ranks across attention layers to account for their varying importance and extend D-Rank to latest LLMs with grouped-query attention. Extensive experiments on various LLMs with different scales across multiple compression ratios demonstrate that D-Rank consistently outperforms SVD-LLM, ASVD, and Basis Sharing, achieving more than 15 lower perplexity with LLaMA-3-8B model on C4 datasets at 20% compression ratio and up to 5% higher zero-shot reasoning accuracy with LLaMA-7B model at 40% compression ratio while achieving even higher throughput.