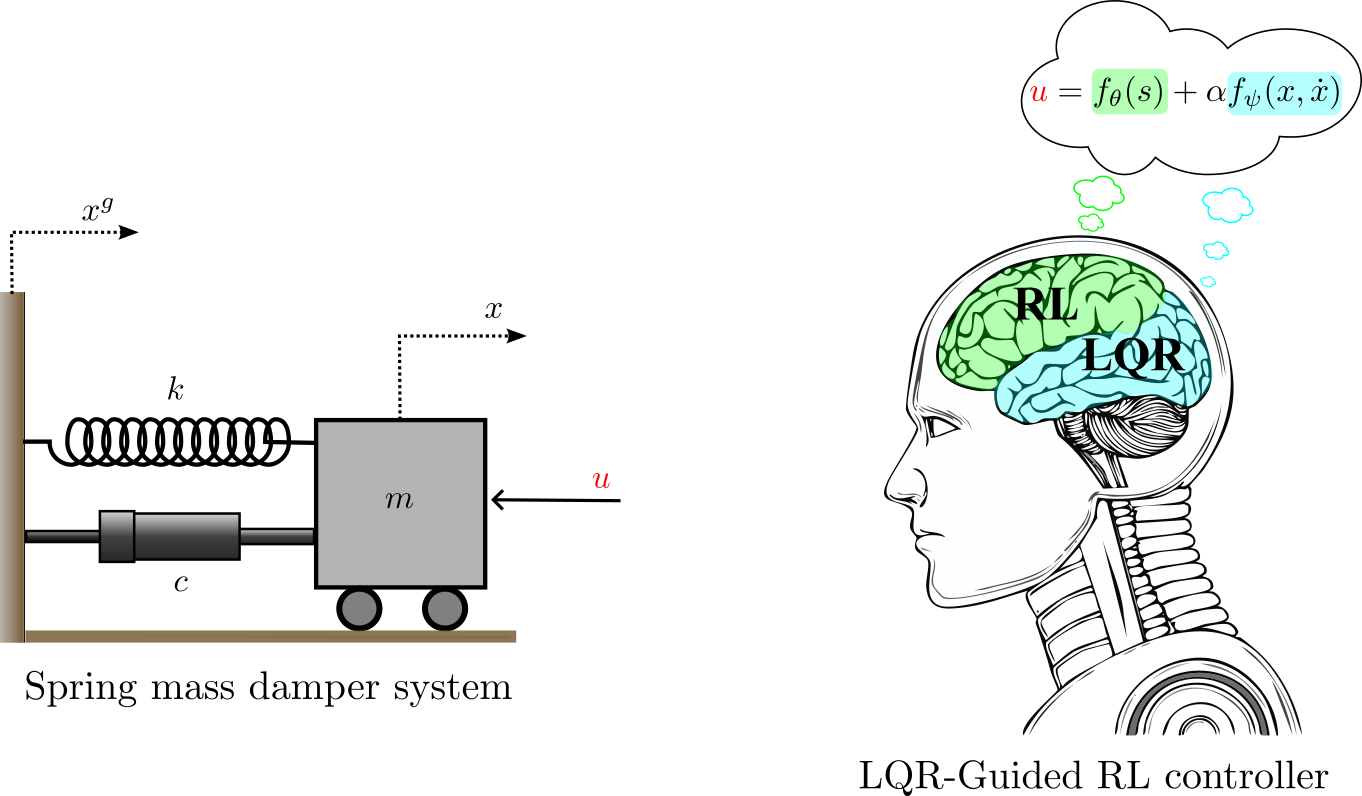
Safe Reinforcement Learning-Based Vibration Control: Overcoming Training Risks with LQR Guidance
作者: Rohan Vitthal Thorat, Juhi Singh, Rajdip Nayek
分类: cs.LG, eess.SY, stat.ML
发布日期: 2025-09-29
备注: Paper accepted for presentation at ICCMS 2025. The submission includes 10 pages and 6 figures
💡 一句话要点
提出基于LQR引导的安全强化学习振动控制方法,解决训练过程中的安全风险。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 振动控制 安全强化学习 线性二次调节器 混合控制 无模型控制 结构健康监测
📋 核心要点
- 传统振动控制方法依赖精确系统模型,系统辨识过程繁琐,而直接在真实系统上训练强化学习控制器存在安全风险。
- 提出一种混合控制框架,利用基于随机模型的LQR控制器引导强化学习控制器,降低训练过程中的探索风险,实现安全控制。
- 该方法无需精确系统模型,在实际物理系统上进行训练,有效解决了强化学习振动控制中的安全问题,并提供了验证方案。
📝 摘要(中文)
外部激励引起的结构振动会带来显著风险,包括人员安全隐患、结构损坏和维护成本增加。传统的基于模型的控制策略,如线性二次调节器(LQR),能有效抑制振动,但依赖于精确的系统模型,需要繁琐的系统辨识。强化学习(RL)方法无需模型,仅从观测到的结构行为中学习策略,避免了显式结构模型的需求。然而,为了使RL控制器真正实现无模型,必须在实际物理系统上进行训练,这会带来安全风险,因为RL控制器在训练初期缺乏先验知识,可能对结构施加随机控制力。为降低这种风险,本文提出使用LQR控制器引导RL控制器。即使基于完全不正确的模型的LQR控制器也优于无控制状态。受此启发,本文提出了一种集成LQR和RL控制器的混合控制框架。LQR策略从随机选择的模型及其参数中导出。这种混合方法消除了对显式系统模型的依赖,同时最大限度地降低了原生RL实现中固有的探索风险。据我们所知,这是第一个解决基于RL的振动控制的关键训练安全挑战并提供验证解决方案的研究。
🔬 方法详解
问题定义:论文旨在解决在实际物理结构上训练强化学习(RL)振动控制器时存在的安全风险。传统的基于模型的控制方法,如LQR,需要精确的系统模型,而系统辨识过程耗时且复杂。直接在真实系统上训练RL控制器虽然可以避免模型辨识,但由于RL控制器在训练初期缺乏先验知识,其随机探索可能导致结构损坏。
核心思路:论文的核心思路是利用一个基于不精确模型的LQR控制器来引导RL控制器的训练过程。作者观察到,即使LQR控制器基于完全错误的模型,其性能也优于无控制状态。因此,LQR控制器可以在RL控制器训练初期提供一定的安全保障,限制其探索范围,避免对结构造成过大的冲击。
技术框架:该混合控制框架包含两个主要部分:一个LQR控制器和一个RL控制器。LQR控制器基于一个随机选择的模型参数进行设计,提供初始的控制策略。RL控制器则通过与真实环境交互,不断学习和优化控制策略。在训练过程中,LQR控制器起到安全保障的作用,限制RL控制器的动作空间,避免其进行危险的探索。最终,RL控制器将逐渐学习到最优的控制策略,并在保证安全的前提下,实现更好的振动控制效果。
关键创新:该论文的关键创新在于提出了利用LQR控制器引导RL控制器训练的混合控制框架,解决了RL振动控制中训练安全问题。该方法无需精确的系统模型,可以在实际物理系统上安全地训练RL控制器。
关键设计:LQR控制器的模型参数是随机选择的,这保证了整个框架的无模型特性。RL控制器的具体算法选择是灵活的,可以使用任何合适的RL算法,例如Q-learning、SARSA或Actor-Critic方法。关键在于设计合适的奖励函数,鼓励RL控制器学习到既能有效抑制振动,又能保证安全的控制策略。具体参数设置和网络结构的选择取决于具体的应用场景和RL算法。
🖼️ 关键图片

📊 实验亮点
论文验证了即使基于不准确模型的LQR控制器也能提供比无控制更好的性能,为LQR引导RL提供了理论基础。提出的混合控制框架能够在实际物理系统上安全地训练RL控制器,有效降低了训练过程中的安全风险。具体实验结果(数据未知)表明,该方法能够在保证安全的前提下,实现良好的振动控制效果。
🎯 应用场景
该研究成果可广泛应用于各种需要振动控制的结构,如桥梁、建筑物、飞行器和精密仪器等。通过该方法,可以在无需精确系统模型的情况下,安全有效地训练强化学习振动控制器,提高结构的抗振性能,延长使用寿命,降低维护成本。该方法尤其适用于难以进行精确建模的复杂结构。
📄 摘要(原文)
Structural vibrations induced by external excitations pose significant risks, including safety hazards for occupants, structural damage, and increased maintenance costs. While conventional model-based control strategies, such as Linear Quadratic Regulator (LQR), effectively mitigate vibrations, their reliance on accurate system models necessitates tedious system identification. This tedious system identification process can be avoided by using a model-free Reinforcement learning (RL) method. RL controllers derive their policies solely from observed structural behaviour, eliminating the requirement for an explicit structural model. For an RL controller to be truly model-free, its training must occur on the actual physical system rather than in simulation. However, during this training phase, the RL controller lacks prior knowledge and it exerts control force on the structure randomly, which can potentially harm the structure. To mitigate this risk, we propose guiding the RL controller using a Linear Quadratic Regulator (LQR) controller. While LQR control typically relies on an accurate structural model for optimal performance, our observations indicate that even an LQR controller based on an entirely incorrect model outperforms the uncontrolled scenario. Motivated by this finding, we introduce a hybrid control framework that integrates both LQR and RL controllers. In this approach, the LQR policy is derived from a randomly selected model and its parameters. As this LQR policy does not require knowledge of the true or an approximate structural model the overall framework remains model-free. This hybrid approach eliminates dependency on explicit system models while minimizing exploration risks inherent in naive RL implementations. As per our knowledge, this is the first study to address the critical training safety challenge of RL-based vibration control and provide a validated solution.