MAESTRO : Adaptive Sparse Attention and Robust Learning for Multimodal Dynamic Time Series
作者: Payal Mohapatra, Yueyuan Sui, Akash Pandey, Stephen Xia, Qi Zhu
分类: cs.LG, stat.ML
发布日期: 2025-09-29
备注: Accepted to Neurips 2025 (Spotlight)
💡 一句话要点
MAESTRO:自适应稀疏注意力与鲁棒学习用于多模态动态时间序列分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 时间序列分析 稀疏注意力 混合专家模型 动态建模 鲁棒学习 模态缺失
📋 核心要点
- 现有方法依赖单一主模态对齐、两两建模模态以及假设模态完整,限制了其在实际多模态时间序列场景中的应用。
- MAESTRO通过动态模态交互、符号化tokenization和自适应注意力预算构建长序列,并利用稀疏跨模态注意力和混合专家机制。
- 实验表明,MAESTRO在完整观测下优于现有方法,在模态缺失情况下性能提升显著,验证了其鲁棒性和效率。
📝 摘要(中文)
本文提出了一种名为MAESTRO的新框架,旨在克服现有多模态学习方法在处理实际多模态时间序列数据时存在的局限性,包括依赖单一主模态进行对齐、模态间的两两建模以及假设模态观测完整性。MAESTRO通过基于任务相关性的动态模态内和跨模态交互,并利用符号化tokenization和自适应注意力预算来构建长多模态序列,并通过稀疏跨模态注意力进行处理。生成的跨模态tokens通过稀疏的混合专家(MoE)机制进行路由,从而在不同的模态组合下实现黑盒专业化。在三个应用领域的四个数据集上,MAESTRO与10个基线模型进行了比较,在完整观测下,相对于现有的最佳多模态和多元方法,平均相对改进分别为4%和8%。在部分观测(高达40%的模态缺失)下,MAESTRO实现了平均9%的改进。进一步的分析表明了MAESTRO的稀疏性、模态感知设计在动态时间序列学习中的鲁棒性和效率。
🔬 方法详解
问题定义:现有的多模态时间序列学习方法通常依赖于单一的主模态进行对齐,这在主模态不明确的情况下会失效。此外,许多方法采用模态间的两两建模,当模态数量较大时,计算复杂度会急剧增加。更重要的是,这些方法通常假设模态观测是完整的,但在实际应用中,传感器故障等原因会导致任意模态数据的缺失,严重影响模型的性能。
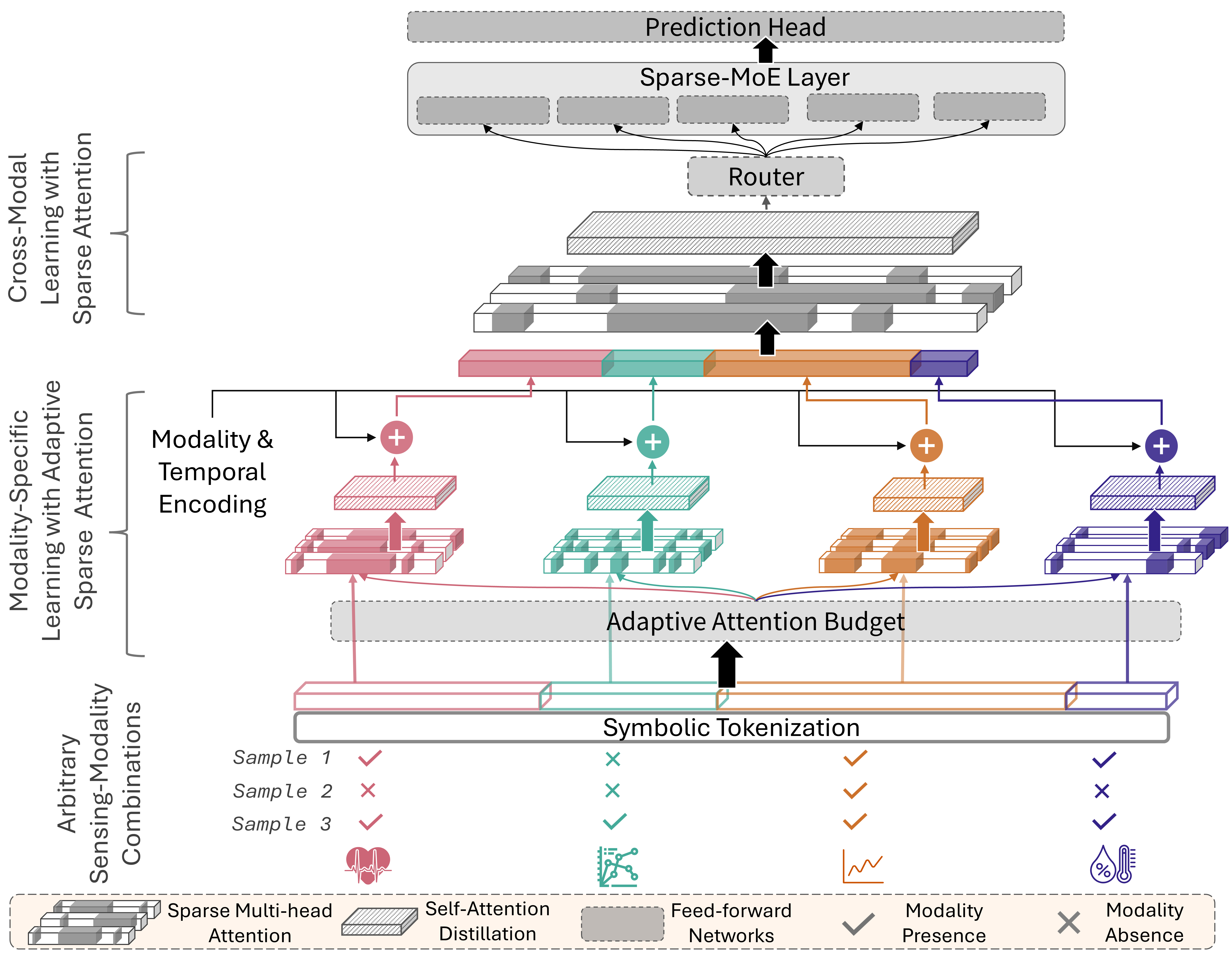
核心思路:MAESTRO的核心思路是动态地学习模态之间的关系,而不是预先设定主模态或进行两两建模。它通过自适应的注意力机制,根据任务的相关性动态地调整模态间的交互强度。同时,利用稀疏注意力机制和混合专家模型,降低计算复杂度,并提高模型在模态缺失情况下的鲁棒性。这种设计允许模型在不同的模态组合下进行专业化学习,从而更好地适应实际应用场景。
技术框架:MAESTRO的整体框架包括以下几个主要模块:1) 符号化Tokenization:将连续的时间序列数据转换为离散的符号表示,以便于后续的注意力机制处理。2) 自适应注意力预算:根据任务相关性动态地分配注意力资源,从而更好地捕捉模态间的交互关系。3) 稀疏跨模态注意力:利用稀疏注意力机制降低计算复杂度,并提高模型在模态缺失情况下的鲁棒性。4) 混合专家(MoE)机制:将跨模态tokens路由到不同的专家模型,从而在不同的模态组合下实现专业化学习。
关键创新:MAESTRO的关键创新在于其动态的、稀疏的、模态感知的学习方式。与现有方法相比,MAESTRO不需要预先设定主模态,能够动态地学习模态间的关系,并且能够有效地处理模态缺失的情况。此外,MAESTRO利用稀疏注意力机制和混合专家模型,降低了计算复杂度,提高了模型的效率。
关键设计:MAESTRO的关键设计包括:1) 自适应注意力预算的计算方式:根据每个模态对任务的贡献程度,动态地调整其注意力权重。2) 稀疏注意力机制的具体实现:例如,可以使用Top-K注意力或局部敏感哈希(LSH)注意力等方法来实现稀疏注意力。3) 混合专家模型的路由策略:例如,可以使用门控网络来决定将每个跨模态token路由到哪个专家模型。4) 损失函数的设计:除了传统的分类或回归损失外,还可以加入正则化项,以鼓励模型的稀疏性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在完整观测条件下,MAESTRO相对于最佳多模态和多元基线模型,平均相对改进分别为4%和8%。更重要的是,在高达40%的模态缺失情况下,MAESTRO仍然实现了平均9%的性能提升,显著优于其他基线模型。这些结果验证了MAESTRO在处理实际多模态时间序列数据时的鲁棒性和有效性。
🎯 应用场景
MAESTRO具有广泛的应用前景,包括临床医疗健康、智能家居、工业监控等领域。在临床医疗中,它可以用于分析多模态生理信号,辅助医生进行疾病诊断和预后评估。在智能家居中,它可以用于理解用户的行为模式,提供个性化的服务。在工业监控中,它可以用于检测设备的异常状态,预防故障发生。MAESTRO的鲁棒性和效率使其能够适应各种实际应用场景,并为智能决策提供有力的支持。
📄 摘要(原文)
From clinical healthcare to daily living, continuous sensor monitoring across multiple modalities has shown great promise for real-world intelligent decision-making but also faces various challenges. In this work, we introduce MAESTRO, a novel framework that overcomes key limitations of existing multimodal learning approaches: (1) reliance on a single primary modality for alignment, (2) pairwise modeling of modalities, and (3) assumption of complete modality observations. These limitations hinder the applicability of these approaches in real-world multimodal time-series settings, where primary modality priors are often unclear, the number of modalities can be large (making pairwise modeling impractical), and sensor failures often result in arbitrary missing observations. At its core, MAESTRO facilitates dynamic intra- and cross-modal interactions based on task relevance, and leverages symbolic tokenization and adaptive attention budgeting to construct long multimodal sequences, which are processed via sparse cross-modal attention. The resulting cross-modal tokens are routed through a sparse Mixture-of-Experts (MoE) mechanism, enabling black-box specialization under varying modality combinations. We evaluate MAESTRO against 10 baselines on four diverse datasets spanning three applications, and observe average relative improvements of 4% and 8% over the best existing multimodal and multivariate approaches, respectively, under complete observations. Under partial observations -- with up to 40% of missing modalities -- MAESTRO achieves an average 9% improvement. Further analysis also demonstrates the robustness and efficiency of MAESTRO's sparse, modality-aware design for learning from dynamic time series.