When Greedy Wins: Emergent Exploitation Bias in Meta-Bandit LLM Training
作者: Sanxing Chen, Xiaoyin Chen, Yukun Huang, Roy Xie, Bhuwan Dhingra
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-29
💡 一句话要点
元-Bandit LLM训练中涌现的贪婪利用偏差研究
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 监督微调 多臂老虎机 探索利用 序贯决策 奖励设计 贪婪利用偏差
📋 核心要点
- 大型语言模型在序贯决策任务中探索不足,现有方法如监督微调和强化学习虽有改进,但探索策略的塑造和泛化能力仍不明确。
- 论文通过监督微调和强化学习训练LLM,并设计了策略性奖励和算法奖励,旨在提升LLM在多臂老虎机任务中的探索能力。
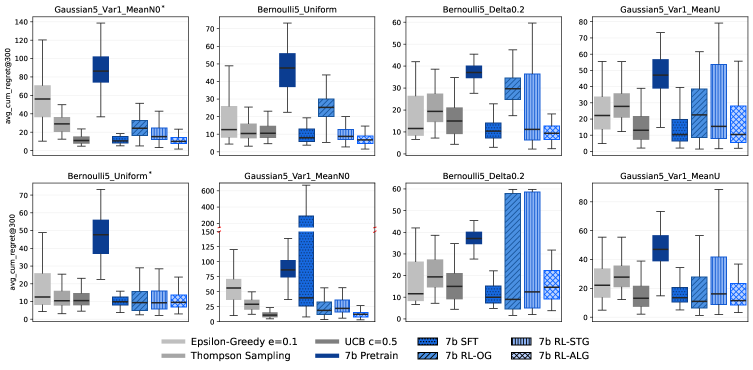
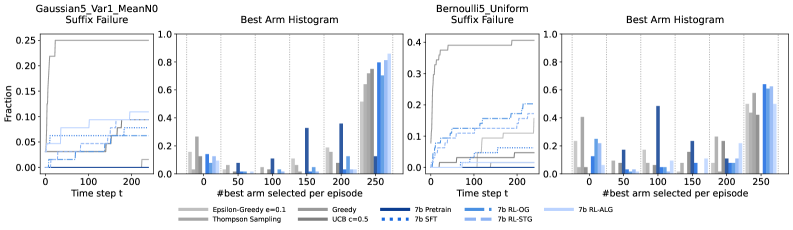
- 实验结果表明,训练后的智能体性能可与UCB和Thompson Sampling媲美,但在更长的horizon和不同老虎机族上表现出更强的贪婪利用倾向。
📝 摘要(中文)
大型语言模型(LLM)有潜力成为自主智能体,但它们在序贯决策中常常进行次优探索。最近的研究试图通过监督微调(SFT)或强化学习(RL)来增强这种能力,从而提高在经典多臂老虎机任务上的遗憾值。然而,这些学习方法如何塑造探索策略以及它们的泛化能力如何仍然不清楚。我们通过使用SFT在专家轨迹上训练LLM以及使用RL和一系列定制的奖励信号(包括用于减少方差的策略性、遗憾塑造的奖励以及支持oracle模仿的算法奖励)来研究这两种范式。由此产生的智能体优于预训练模型,并实现了与上限置信区间(UCB)和汤普森采样相当的性能,并且对6倍更长的horizon和跨老虎机族的泛化具有鲁棒性。行为分析表明,收益通常源于更复杂但更贪婪的利用:RL/SFT智能体比预训练模型更容易出现早期灾难性失败,过早地放弃探索。此外,训练来模仿UCB的智能体通过采用更具利用性的变体来学习超越其教师。我们的发现阐明了每种训练范式何时更可取,并提倡定制的奖励设计和超出平均遗憾的评估,以促进稳健的探索行为。
🔬 方法详解
问题定义:现有的大型语言模型在序贯决策任务中,特别是多臂老虎机问题中,存在探索不足的问题。传统的监督微调和强化学习方法虽然可以提升性能,但对探索策略的影响以及泛化能力尚不明确。现有方法容易陷入局部最优,无法有效地平衡探索和利用。
核心思路:论文的核心思路是通过监督微调和强化学习,结合定制化的奖励函数,来训练LLM在多臂老虎机任务中进行更有效的探索。通过策略性地设计奖励,鼓励模型在早期阶段进行充分的探索,避免过早地陷入贪婪利用。同时,研究不同训练范式对探索策略的影响,并分析其泛化能力。
技术框架:整体框架包括以下几个主要模块:1) 数据生成:生成专家轨迹数据,用于监督微调。2) 模型训练:使用监督微调和强化学习两种范式训练LLM。3) 奖励设计:设计策略性奖励和算法奖励,用于指导强化学习过程。4) 评估:在不同长度的horizon和不同老虎机族上评估模型的性能和泛化能力。具体流程是,首先使用SFT在专家轨迹上训练LLM,然后使用RL和定制的奖励信号进一步优化模型。
关键创新:论文的关键创新在于:1) 提出了策略性奖励和算法奖励,用于指导强化学习过程,鼓励模型进行更有效的探索。2) 深入分析了监督微调和强化学习对LLM探索策略的影响,揭示了贪婪利用偏差的问题。3) 发现通过模仿UCB训练的智能体,可以通过采用更具利用性的变体来超越其教师。
关键设计:在强化学习中,论文设计了两种定制化的奖励函数:策略性奖励(regret-shaped reward)旨在减少方差,鼓励模型进行更稳定的探索;算法奖励(algorithmic reward)则允许模型模仿oracle算法的行为。具体的参数设置和损失函数细节在论文中进行了详细描述,例如,使用了特定的学习率、batch size和优化器等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过监督微调和强化学习训练的LLM在多臂老虎机任务中表现优异,性能可与UCB和Thompson Sampling媲美。在更长的horizon(6倍)和不同老虎机族上的泛化能力也得到了验证。然而,研究也发现,训练后的智能体更容易出现贪婪利用偏差,过早地放弃探索。模仿UCB训练的智能体甚至可以通过采用更具利用性的变体来超越其教师。
🎯 应用场景
该研究成果可应用于开发更智能、更自主的语言模型智能体,使其在需要序贯决策的实际场景中表现更佳,例如:自动驾驶、推荐系统、金融交易、资源分配等。通过优化探索策略,可以提高智能体在复杂环境中的适应性和长期收益。
📄 摘要(原文)
While Large Language Models (LLMs) hold promise to become autonomous agents, they often explore suboptimally in sequential decision-making. Recent work has sought to enhance this capability via supervised fine-tuning (SFT) or reinforcement learning (RL), improving regret on the classic multi-armed bandit task. However, it remains unclear how these learning methods shape exploration strategies and how well they generalize. We investigate both paradigms by training LLMs with SFT on expert trajectories and RL with a range of tailored reward signals including a strategic, regret-shaped reward to reduce variance, and an algorithmic reward that enables oracle imitation. The resulting agents outperform pre-trained models and achieve performance comparable to Upper Confidence Bound (UCB) and Thompson Sampling, with robust generalization to 6x longer horizons and across bandit families. Behavioral analysis reveals that gains often stem from more sophisticated but greedier exploitation: RL/SFT agents are more prone to early catastrophic failure than pre-trained models, prematurely abandoning exploration. Furthermore, agents trained to imitate UCB learn to outperform their teacher by adopting more exploitative variants. Our findings clarify when each training paradigm is preferable and advocate tailored reward design and evaluation beyond average regret to promote robust exploratory behavior.