A TRIANGLE Enables Multimodal Alignment Beyond Cosine Similarity
作者: Giordano Cicchetti, Eleonora Grassucci, Danilo Comminiello
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-09-29
备注: NeurIPS 2025
💡 一句话要点
提出TRIANGLE,通过三角形面积相似度提升多模态对齐效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 多模态对齐 对比学习 三角形面积相似度 视频理解
📋 核心要点
- 现有方法在多模态对齐方面存在不足,缺乏有效指标来保证所有模态的有效对齐,导致模型性能下降。
- TRIANGLE通过计算模态嵌入高维空间中的三角形面积相似度,直接优化三个模态的联合对齐,无需额外的融合层。
- 实验表明,TRIANGLE在视频-文本、音频-文本检索和音频-视频分类等任务中显著提升性能,Recall@1指标最高提升9个百分点。
📝 摘要(中文)
多模态学习在人工智能系统中发挥着关键作用,它通过整合来自多个模态的信息来构建更全面的表示。尽管其重要性,当前最先进的模型仍然存在严重的局限性,阻碍了完全多模态模型的成功开发。这些方法可能无法提供所有相关模态都有效对齐的指标。因此,某些模态可能未对齐,从而削弱了模型在下游任务中的有效性,在这些任务中,多个模态应提供模型未能利用的额外信息。在本文中,我们提出了TRIANGLE:TRI-modAl Neural Geometric LEarning,这是一种新的相似性度量,直接在高维空间中计算,该空间由模态嵌入跨越。TRIANGLE通过三角形面积相似性改进了三个模态的联合对齐,避免了额外的融合层或成对相似性。当TRIANGLE被纳入对比损失中以取代余弦相似性时,它显着提高了多模态建模的性能,同时产生了可解释的对齐理由。在视频-文本和音频-文本检索或音频-视频分类等三模态任务中的广泛评估表明,TRIANGLE在不同的数据集上实现了最先进的结果,将基于余弦的方法的Recall@1性能提高了高达9个百分点。
🔬 方法详解
问题定义:现有的多模态学习方法,特别是那些依赖于余弦相似度的方法,在确保所有模态有效对齐方面存在困难。这意味着模型可能无法充分利用所有模态的信息,导致在需要多模态信息融合的任务中表现不佳。核心问题在于缺乏一种能够直接在高维嵌入空间中衡量多模态联合对齐程度的有效方法。
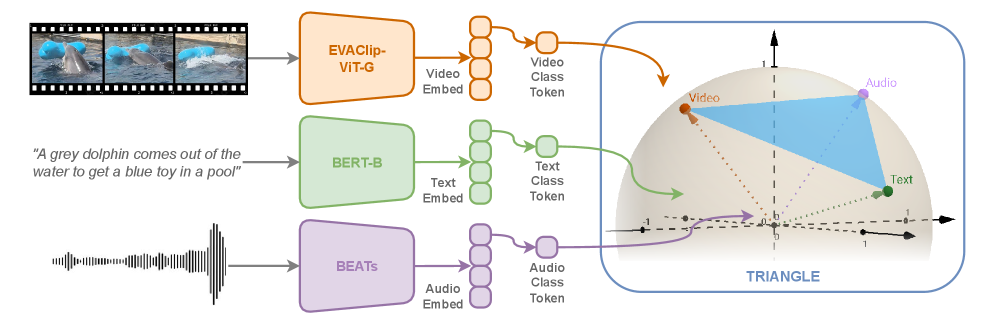
核心思路:TRIANGLE的核心思路是利用三角形面积作为多模态相似性的度量。具体来说,对于三个模态的嵌入向量,将它们视为一个三角形的三个顶点,然后计算该三角形的面积。面积越大,表示三个模态的嵌入向量越不相似,反之亦然。这种方法能够直接在高维空间中衡量多模态的联合对齐程度,避免了传统方法中需要额外的融合层或两两计算相似度的步骤。
技术框架:TRIANGLE方法主要包含以下几个步骤:1) 首先,使用预训练的单模态编码器将每个模态的数据编码成高维嵌入向量。2) 然后,将三个模态的嵌入向量作为三角形的顶点,计算三角形的面积。3) 最后,将计算得到的三角形面积作为相似性度量,用于对比学习损失函数的计算。整体流程简单清晰,易于实现。
关键创新:TRIANGLE最重要的技术创新点在于提出了使用三角形面积作为多模态相似性度量的方法。与传统的余弦相似度相比,TRIANGLE能够更好地捕捉多模态之间的联合关系,并且避免了额外的融合层或两两计算相似度的步骤。此外,TRIANGLE还能够提供可解释的对齐理由,有助于理解模型是如何进行多模态融合的。
关键设计:TRIANGLE的关键设计在于三角形面积的计算公式。假设三个模态的嵌入向量分别为a, b, c,则三角形的面积可以表示为:Area = 0.5 * ||(b - a) x (c - a)||, 其中x表示向量的叉积,|| ||表示向量的模。在实际应用中,可以将三角形面积进行归一化,使其取值范围在0到1之间。此外,TRIANGLE可以很容易地集成到现有的对比学习框架中,只需要将余弦相似度替换为三角形面积即可。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TRIANGLE在多个三模态任务中取得了显著的性能提升。例如,在视频-文本检索任务中,TRIANGLE的Recall@1指标比基于余弦相似度的方法提高了高达9个百分点。在音频-视频分类任务中,TRIANGLE也取得了类似的性能提升。这些结果表明,TRIANGLE是一种有效的多模态对齐方法,能够显著提高多模态模型的性能。
🎯 应用场景
TRIANGLE方法具有广泛的应用前景,可应用于视频理解、跨模态检索、多模态情感分析等领域。例如,在视频理解中,可以利用TRIANGLE来对齐视频、音频和文本信息,从而提高视频内容理解的准确性。在跨模态检索中,可以利用TRIANGLE来衡量不同模态数据之间的相似性,从而实现更准确的检索结果。该研究有助于推动多模态学习的发展,提升人工智能系统的感知和理解能力。
📄 摘要(原文)
Multimodal learning plays a pivotal role in advancing artificial intelligence systems by incorporating information from multiple modalities to build a more comprehensive representation. Despite its importance, current state-of-the-art models still suffer from severe limitations that prevent the successful development of a fully multimodal model. Such methods may not provide indicators that all the involved modalities are effectively aligned. As a result, some modalities may not be aligned, undermining the effectiveness of the model in downstream tasks where multiple modalities should provide additional information that the model fails to exploit. In this paper, we present TRIANGLE: TRI-modAl Neural Geometric LEarning, the novel proposed similarity measure that is directly computed in the higher-dimensional space spanned by the modality embeddings. TRIANGLE improves the joint alignment of three modalities via a triangle-area similarity, avoiding additional fusion layers or pairwise similarities. When incorporated in contrastive losses replacing cosine similarity, TRIANGLE significantly boosts the performance of multimodal modeling, while yielding interpretable alignment rationales. Extensive evaluation in three-modal tasks such as video-text and audio-text retrieval or audio-video classification, demonstrates that TRIANGLE achieves state-of-the-art results across different datasets improving the performance of cosine-based methods up to 9 points of Recall@1.