Group-Relative REINFORCE Is Secretly an Off-Policy Algorithm: Demystifying Some Myths About GRPO and Its Friends
作者: Chaorui Yao, Yanxi Chen, Yuchang Sun, Yushuo Chen, Wenhao Zhang, Xuchen Pan, Yaliang Li, Bolin Ding
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
揭示GRPO的Off-Policy本质:为LLM的Off-Policy强化学习提供理论基础与算法指导
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Off-policy强化学习 大规模语言模型 REINFORCE算法 Group Relative Policy Optimization 策略正则化
📋 核心要点
- 现有REINFORCE算法及其变体通常被认为是On-policy算法,难以直接应用于LLM的Off-policy强化学习场景。
- 论文通过理论推导,证明了Group-Relative REINFORCE具有Off-policy的内在性质,并提出了正则化和数据塑造两种适应Off-policy的通用原则。
- 实验验证了提出的理论见解,并为LLM的Off-policy强化学习算法设计提供了新的方向和机会。
📝 摘要(中文)
本文针对大规模语言模型(LLM)的Off-policy强化学习(RL)问题,该问题因实际应用约束、LLM-RL基础设施的复杂性以及RL方法创新的需求而备受关注。尽管传统的REINFORCE及其现代变体(如Group Relative Policy Optimization,GRPO)通常被认为是On-policy算法,对Off-policy的容忍度有限,但本文从第一性原理推导了group-relative REINFORCE,无需假设特定的训练数据分布,表明它具有原生的Off-policy解释。该视角产生了两个通用的原则,用于将REINFORCE适应于Off-policy设置:正则化策略更新和主动塑造数据分布。我们的分析揭示了重要性采样和裁剪在GRPO中的作用,统一并重新解释了最近的两个算法——Online Policy Mirror Descent (OPMD)和Asymmetric REINFORCE (AsymRE)——作为REINFORCE损失的正则化形式,并为看似启发式的数据加权策略提供了理论依据。我们的发现带来了可操作的见解,并通过广泛的实证研究得到了验证,并为LLM的Off-policy RL中的原则性算法设计开辟了新的机会。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型(LLM)在Off-policy强化学习(RL)中面临的挑战。传统的REINFORCE算法及其变体,如GRPO,通常被认为是On-policy算法,对数据分布的改变非常敏感。在实际应用中,由于数据收集的限制和探索的需要,Off-policy学习变得至关重要。因此,如何将REINFORCE算法有效地应用于Off-policy场景,成为了一个亟待解决的问题。现有方法通常依赖于重要性采样或裁剪等技巧,但缺乏理论基础,且效果有限。
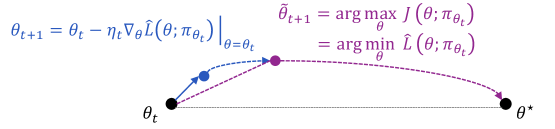
核心思路:论文的核心思路是重新审视Group-Relative REINFORCE (GRPO)算法,并从第一性原理出发,证明其具有内在的Off-policy性质。通过推导GRPO的损失函数,论文发现GRPO可以被解释为一种正则化的REINFORCE算法,其中正则化项可以控制策略更新的幅度,从而提高算法的稳定性。此外,论文还提出了主动塑造数据分布的策略,通过调整训练数据的权重,来优化算法的性能。
技术框架:论文的技术框架主要包括以下几个部分:1) 对Group-Relative REINFORCE进行理论推导,证明其Off-policy性质;2) 提出两种通用的Off-policy适应原则:正则化策略更新和主动塑造数据分布;3) 将OPMD和AsymRE等算法重新解释为正则化的REINFORCE算法;4) 通过实验验证提出的理论见解和算法的有效性。
关键创新:论文最重要的技术创新在于揭示了Group-Relative REINFORCE的Off-policy本质。与以往认为GRPO是On-policy算法的观点不同,论文通过理论推导证明了GRPO可以在一定程度上处理Off-policy数据。此外,论文提出的正则化策略更新和主动塑造数据分布的原则,为设计Off-policy REINFORCE算法提供了新的思路。
关键设计:论文的关键设计包括:1) 推导GRPO的损失函数,并将其分解为REINFORCE损失和正则化项;2) 设计正则化项,以控制策略更新的幅度;3) 提出数据加权策略,以主动塑造数据分布;4) 将OPMD和AsymRE等算法重新解释为正则化的REINFORCE算法,并分析其正则化项的性质。
🖼️ 关键图片

📊 实验亮点
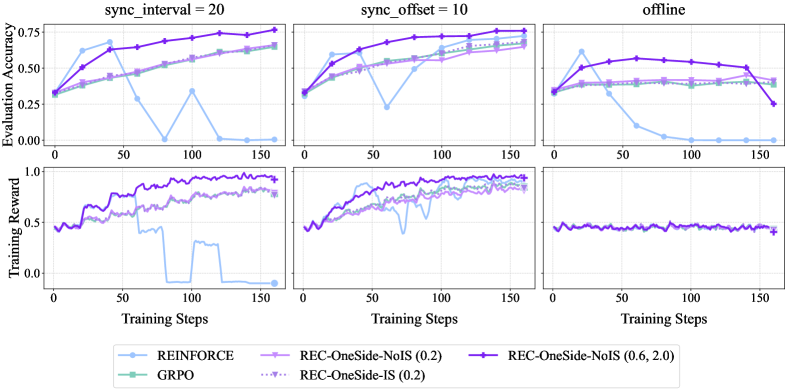
论文通过实验验证了提出的理论见解。实验结果表明,通过正则化策略更新和主动塑造数据分布,可以显著提高REINFORCE算法在Off-policy场景下的性能。此外,论文还验证了将OPMD和AsymRE等算法重新解释为正则化的REINFORCE算法的有效性。具体的性能数据和对比基线在论文中进行了详细的展示。
🎯 应用场景
该研究成果可广泛应用于大规模语言模型的强化学习,尤其是在需要利用离线数据或探索性策略的场景中。例如,可以用于优化对话系统、文本生成模型和推荐系统等。该研究为设计更有效的Off-policy RL算法提供了理论基础,有助于提升LLM在实际应用中的性能和鲁棒性,并降低训练成本。
📄 摘要(原文)
Off-policy reinforcement learning (RL) for large language models (LLMs) is attracting growing interest, driven by practical constraints in real-world applications, the complexity of LLM-RL infrastructure, and the need for further innovations of RL methodologies. While classic REINFORCE and its modern variants like Group Relative Policy Optimization (GRPO) are typically regarded as on-policy algorithms with limited tolerance of off-policyness, we present in this work a first-principles derivation for group-relative REINFORCE without assuming a specific training data distribution, showing that it admits a native off-policy interpretation. This perspective yields two general principles for adapting REINFORCE to off-policy settings: regularizing policy updates, and actively shaping the data distribution. Our analysis demystifies some myths about the roles of importance sampling and clipping in GRPO, unifies and reinterprets two recent algorithms -- Online Policy Mirror Descent (OPMD) and Asymmetric REINFORCE (AsymRE) -- as regularized forms of the REINFORCE loss, and offers theoretical justification for seemingly heuristic data-weighting strategies. Our findings lead to actionable insights that are validated with extensive empirical studies, and open up new opportunities for principled algorithm design in off-policy RL for LLMs. Source code for this work is available at https://github.com/modelscope/Trinity-RFT/tree/main/examples/rec_gsm8k.