Negative Pre-activations Differentiate Syntax
作者: Linghao Kong, Angelina Ning, Micah Adler, Nir Shavit
分类: cs.LG
发布日期: 2025-09-29
备注: 10 pages, 7 figures
💡 一句话要点
发现语言模型中负激活区分句法的机制,揭示Wasserstein神经元的关键作用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 句法分析 Wasserstein神经元 负激活 可解释性
📋 核心要点
- 大型语言模型虽然强大,但其内部机制复杂,难以理解,尤其是在句法处理方面。
- 论文提出,语言模型中一小部分被称为Wasserstein神经元的纠缠神经元,通过负激活区分句法成分。
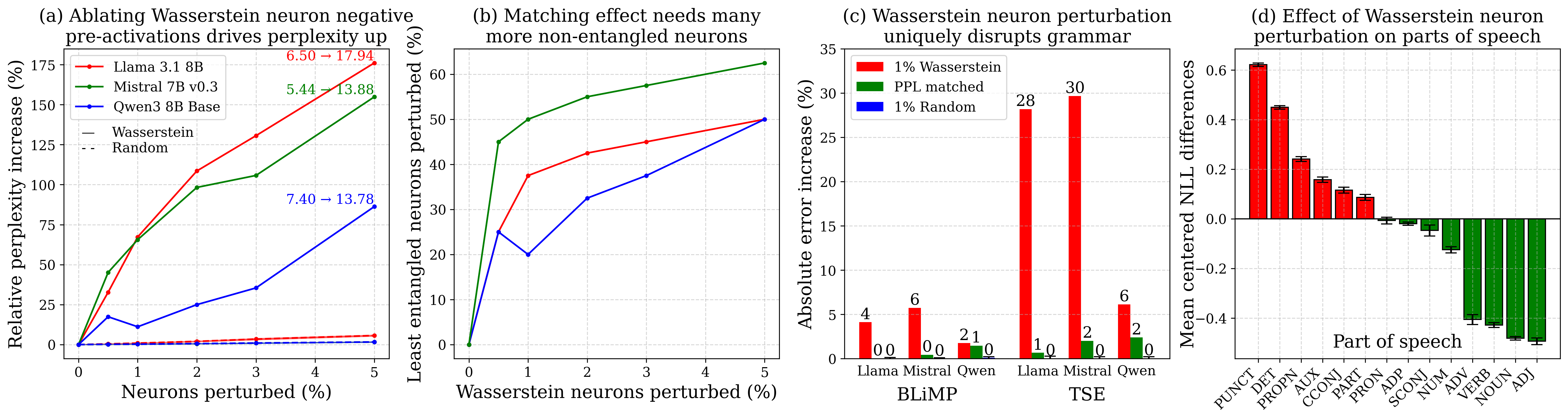
- 实验表明,选择性地消除这些神经元的负激活会显著损害模型的语法能力,证明了其在句法处理中的关键作用。
📝 摘要(中文)
本文发现了一类被称为Wasserstein神经元的纠缠神经元,它们在大型语言模型中占据极小比例,但却至关重要。有针对性地移除这些神经元会导致模型崩溃,表明它们在区分相似输入方面具有独特作用。有趣的是,在平滑激活函数之前的Wasserstein神经元中,这种区分体现在负激活空间中,尤其是在早期层。相似的输入对被驱动到高度不同的负值,这些输入对涉及限定词和介词等句法标记。研究表明,这种负区域是功能性的,而不仅仅是有利于优化。一项最小的、符号特定的干预,即仅将一小部分纠缠神经元的负激活置零,会显著削弱整体模型功能并破坏语法行为,而随机和困惑度匹配的控制则在很大程度上保持了语法性能不变。词性分析将过多的惊奇度定位到句法支架标记,而特定层的干预表明,小的局部退化会随着深度积累。在训练检查点上,相同的消融会随着Wasserstein神经元的出现和稳定而损害语法行为。总之,这些结果表明,稀疏纠缠神经元子集中的负区分是语言模型依赖于句法的关键机制。
🔬 方法详解
问题定义:大型语言模型在处理自然语言时,其内部如何进行句法分析和理解是一个重要的研究问题。现有的方法难以解释模型内部的句法处理机制,并且缺乏对关键神经元作用的深入理解。特别地,如何区分相似但句法功能不同的输入,例如限定词和介词,是一个挑战。
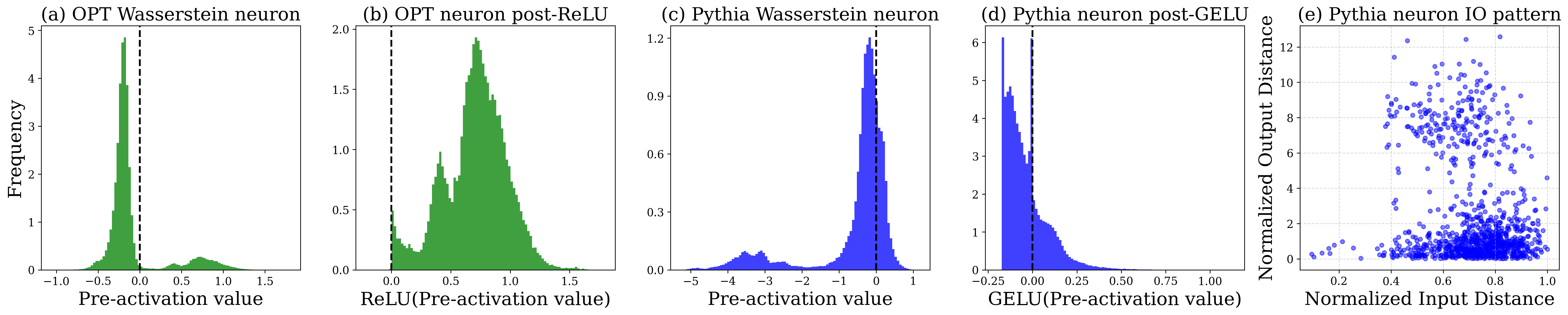
核心思路:论文的核心思路是关注一类特殊的神经元,即Wasserstein神经元,并研究它们在负激活空间中的行为。作者假设这些神经元通过将相似的输入驱动到不同的负激活值,从而实现句法区分。通过选择性地干预这些神经元的负激活,可以验证它们在句法处理中的作用。
技术框架:该研究主要包括以下几个阶段:1) 识别语言模型中的Wasserstein神经元;2) 观察这些神经元在处理相似输入时的激活模式,特别是在负激活空间中的行为;3) 设计选择性的干预实验,即仅将这些神经元的负激活置零,并观察对模型性能的影响;4) 使用词性分析等方法,评估干预对语法行为的具体影响;5) 分析不同层的干预效果,以及训练过程中Wasserstein神经元的作用。
关键创新:该研究最重要的技术创新点在于发现了Wasserstein神经元在负激活空间中进行句法区分的机制。与以往关注正激活的研究不同,该研究揭示了负激活在语言模型中的重要作用。此外,通过选择性的干预实验,作者能够精确地评估这些神经元对语法行为的贡献。
关键设计:关键的设计包括:1) 选择性干预策略,即仅将Wasserstein神经元的负激活置零,以避免对其他神经元造成不必要的影响;2) 使用词性分析来评估干预对语法行为的具体影响,例如,观察对限定词和介词等句法标记的影响;3) 分析不同层的干预效果,以了解句法处理在模型中的层次结构;4) 比较不同训练阶段的干预效果,以了解Wasserstein神经元在训练过程中的作用。
🖼️ 关键图片
📊 实验亮点
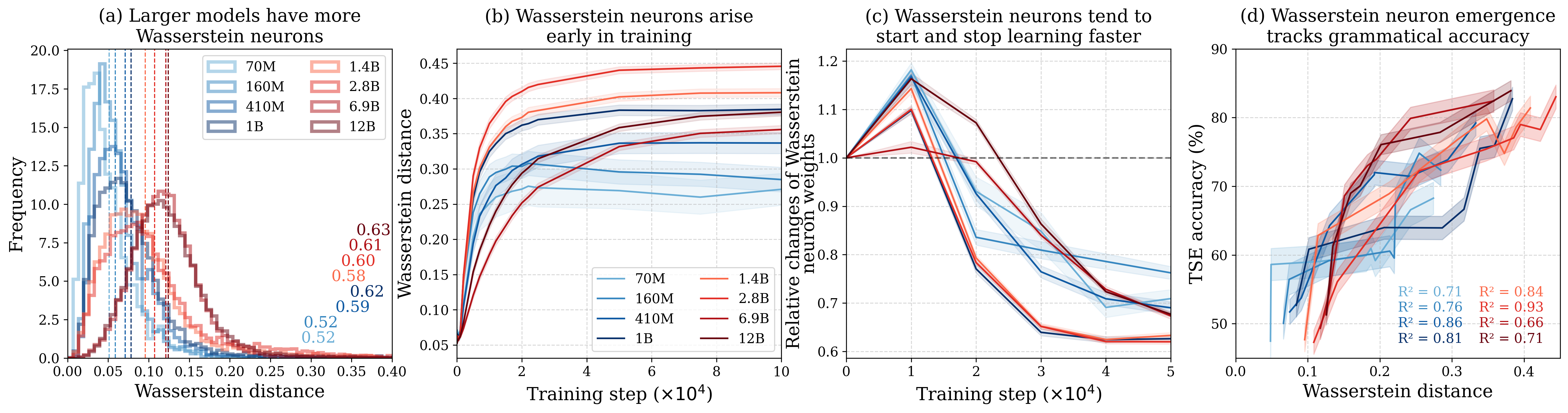
实验结果表明,选择性地消除Wasserstein神经元的负激活会显著损害模型的语法能力,导致语法错误的增加。词性分析显示,这种干预主要影响了限定词和介词等句法标记。此外,实验还发现,这种损害会随着模型深度的增加而累积,并且在Wasserstein神经元出现和稳定后,这种干预的效果更加明显。
🎯 应用场景
该研究成果可应用于提升语言模型的句法理解能力,例如改进机器翻译、文本摘要等任务。通过理解和利用Wasserstein神经元的句法区分机制,可以设计更高效、更可解释的语言模型。此外,该研究也为模型的可解释性研究提供了新的思路,有助于开发更可靠、更安全的AI系统。
📄 摘要(原文)
A recently discovered class of entangled neurons, known as Wasserstein neurons, is disproportionately critical in large language models despite constituting only a very small fraction of the network: their targeted removal collapses the model, consistent with their unique role in differentiating similar inputs. Interestingly, in Wasserstein neurons immediately preceding smooth activation functions, such differentiation manifests in the negative pre-activation space, especially in early layers. Pairs of similar inputs are driven to highly distinct negative values, and these pairs involve syntactic tokens such as determiners and prepositions. We show that this negative region is functional rather than simply favorable for optimization. A minimal, sign-specific intervention that zeroes only the negative pre-activations of a small subset of entangled neurons significantly weakens overall model function and disrupts grammatical behavior, while both random and perplexity-matched controls leave grammatical performance largely unchanged. Part of speech analysis localizes the excess surprisal to syntactic scaffolding tokens, and layer-specific interventions reveal that small local degradations accumulate across depth. Over training checkpoints, the same ablation impairs grammatical behavior as Wasserstein neurons emerge and stabilize. Together, these results identify negative differentiation in a sparse subset of entangled neurons as a crucial mechanism that language models rely on for syntax.