Stable Forgetting: Bounded Parameter-Efficient Unlearning in LLMs
作者: Arpit Garg, Hemanth Saratchandran, Ravi Garg, Simon Lucey
分类: cs.LG, cs.AI
发布日期: 2025-09-29
备注: In Submission
💡 一句话要点
提出有界参数高效遗忘方法,解决LLM中不稳定的遗忘问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 机器遗忘 参数高效微调 梯度差分 LoRA
📋 核心要点
- 现有LLM遗忘方法(如梯度差分法)在交叉熵损失下会导致权重和梯度无界增长,造成训练不稳定。
- 论文提出有界参数高效遗忘方法,通过对MLP适配器应用有界函数来稳定LoRA微调,控制权重动态。
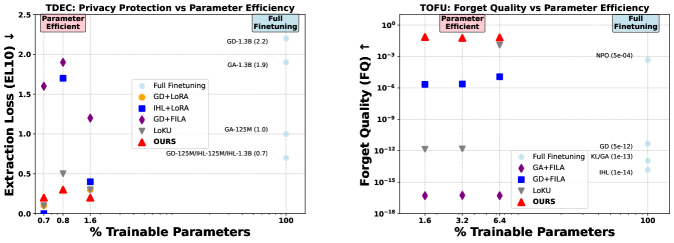
- 实验表明,该方法在多个基准测试和不同规模的模型上,显著提升了遗忘性能,同时保持了保留性能。
📝 摘要(中文)
大型语言模型(LLM)中的机器遗忘对于隐私和安全至关重要;然而,现有方法仍然不稳定且不可靠。一种广泛使用的策略,即梯度差分法,在保留数据上应用梯度下降,同时在遗忘数据(即应该移除其影响的数据)上执行梯度上升。然而,当与交叉熵损失结合使用时,此过程会导致权重和梯度的无界增长,从而导致训练不稳定并降低遗忘和保留性能。我们提供了一个理论框架来解释这种失败,明确展示了在LLM的前馈MLP层中,对遗忘集进行梯度上升如何破坏优化。基于此洞察,我们提出有界参数高效遗忘,这是一种参数高效的方法,通过将有界函数应用于MLP适配器来稳定基于LoRA的微调。这种简单的修改控制了梯度上升期间的权重动态,使梯度差分法能够可靠地收敛。在TOFU、TDEC和MUSE基准测试中,以及在从125M到8B参数的架构和规模上,我们的方法在保持保留性能的同时,实现了遗忘性能的显著提升,从而建立了一个新颖的、具有理论基础和实际可扩展性的LLM遗忘框架。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中机器遗忘的不稳定性和不可靠性问题。现有的梯度差分方法在与交叉熵损失结合使用时,会导致模型权重和梯度的无界增长,从而破坏训练过程,降低遗忘效果,并损害模型对保留数据的记忆能力。
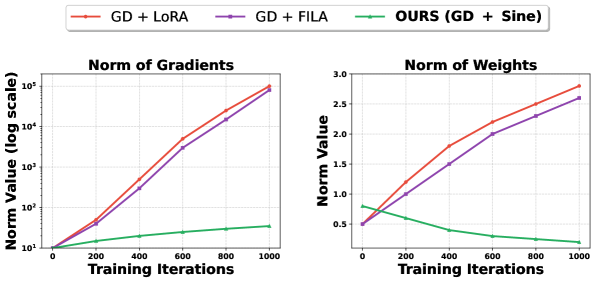
核心思路:论文的核心思路是通过限制模型参数的更新幅度来稳定遗忘过程。具体来说,通过对MLP适配器应用有界函数,控制梯度上升期间的权重动态,从而避免权重和梯度的无界增长。这种方法旨在使梯度差分法能够更可靠地收敛,从而实现更有效的遗忘。
技术框架:论文提出的有界参数高效遗忘方法主要基于LoRA(Low-Rank Adaptation)微调框架。该方法在LoRA适配器的基础上,对MLP层的权重更新施加约束。整体流程包括:首先,使用梯度差分法计算遗忘数据和保留数据的梯度;然后,将这些梯度应用于LoRA适配器,但在应用之前,使用有界函数对梯度进行裁剪或缩放,以限制权重更新的幅度;最后,使用更新后的LoRA适配器对LLM进行微调。
关键创新:论文的关键创新在于提出了使用有界函数来稳定LLM遗忘过程。与现有方法相比,该方法能够有效地控制权重动态,避免梯度爆炸和训练不稳定,从而提高遗忘的可靠性和有效性。此外,该方法是参数高效的,因为它只修改LoRA适配器的权重,而不需要修改整个LLM的参数。
关键设计:论文的关键设计包括:1) 使用LoRA进行参数高效的微调;2) 选择合适的有界函数,例如sigmoid函数或tanh函数,对MLP适配器的权重更新进行约束;3) 调整有界函数的参数,例如缩放因子或裁剪阈值,以控制权重更新的幅度。此外,论文还可能涉及对损失函数的调整,以进一步优化遗忘过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在TOFU、TDEC和MUSE等多个基准测试中,以及在不同规模(125M到8B参数)的LLM上,均实现了显著的遗忘性能提升,同时保持了良好的保留性能。具体提升幅度取决于具体的基准测试和模型规模,但总体而言,该方法能够有效地提高LLM的遗忘能力,使其能够更可靠地移除特定信息的影响。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私和数据安全的场景,例如:从LLM中移除不准确或有害的信息,遵守数据隐私法规(如GDPR),以及防止LLM泄露敏感信息。此外,该方法还可以用于模型修复,即从模型中移除已知的漏洞或缺陷。
📄 摘要(原文)
Machine unlearning in large language models (LLMs) is essential for privacy and safety; however, existing approaches remain unstable and unreliable. A widely used strategy, the gradient difference method, applies gradient descent on retained data while performing gradient ascent on forget data, the data whose influence should be removed. However, when combined with cross-entropy loss, this procedure causes unbounded growth of weights and gradients, leading to training instability and degrading both forgetting and retention. We provide a theoretical framework that explains this failure, explicitly showing how ascent on the forget set destabilizes optimization in the feedforward MLP layers of LLMs. Guided by this insight, we propose Bounded Parameter-Efficient Unlearning, a parameter-efficient approach that stabilizes LoRA-based fine-tuning by applying bounded functions to MLP adapters. This simple modification controls the weight dynamics during ascent, enabling the gradient difference method to converge reliably. Across the TOFU, TDEC, and MUSE benchmarks, and across architectures and scales from 125M to 8B parameters, our method achieves substantial improvements in forgetting while preserving retention, establishing a novel theoretically grounded and practically scalable framework for unlearning in LLMs.