MACE: A Hybrid LLM Serving System with Colocated SLO-aware Continuous Retraining Alignment
作者: Yufei Li, Yu Fu, Yue Dong, Cong Liu
分类: cs.LG, cs.AI, cs.CL, cs.DC
发布日期: 2025-09-28
备注: 14 pages, 15 figures
💡 一句话要点
MACE:一种混合LLM服务系统,通过协同的SLO感知持续重训练对齐模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 边缘计算 大型语言模型 持续学习 模型重训练 服务质量 混合调度 资源管理 低延迟推理
📋 核心要点
- 边缘LLM部署面临用户数据变化带来的频繁重训练需求,现有方法在延迟、资源利用和模型更新频率之间难以平衡。
- MACE通过协同推理和微调,并结合迭代级别的智能调度,在满足服务级别目标(SLO)的同时,自适应调整重训练频率。
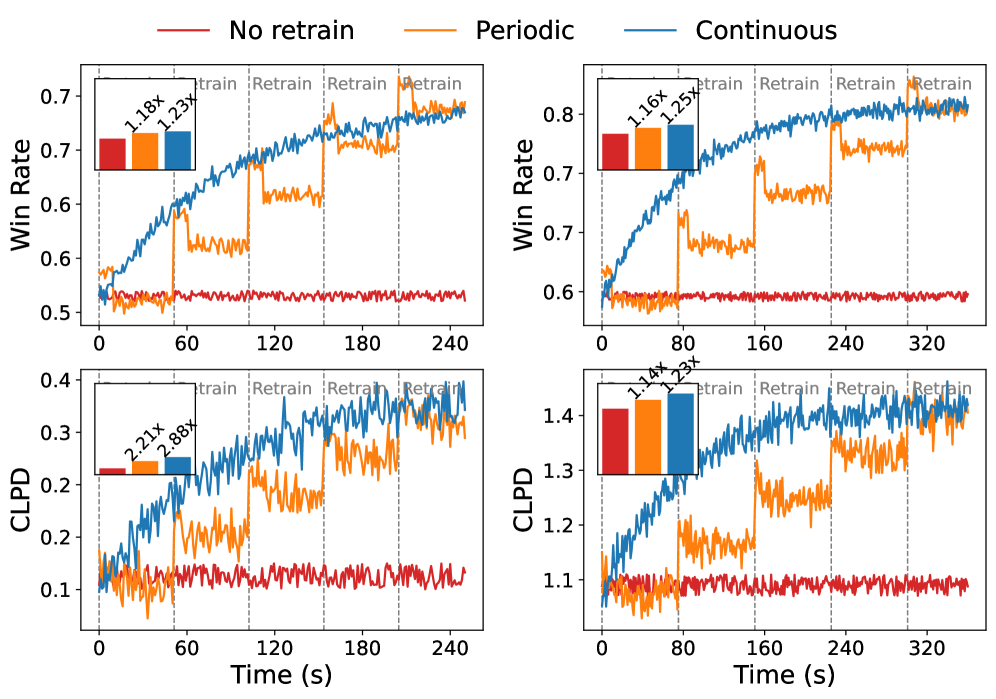
- 实验表明,MACE在降低推理延迟高达63%的同时,保持或超过持续重训练的性能,并有效提升了GPU利用率。
📝 摘要(中文)
本文提出MACE,一种混合LLM服务系统,旨在解决边缘服务器上部署的大型语言模型(LLM)在延迟敏感应用中面临的挑战,即用户数据的不稳定性需要频繁重训练,导致推理延迟和模型精度之间的根本矛盾。MACE通过协同并发的推理(预填充、解码)和微调,并采用智能内存管理来最大化任务性能,同时保证推理吞吐量。MACE的关键在于迭代级别的调度,能够根据模型漂移自适应地调整重训练频率,而不会违反服务级别目标(SLO)。实验结果表明,MACE在资源受限的情况下,能够匹配或超过持续重训练的效果,同时降低高达63%的推理延迟,并保持吞吐量。与周期性重训练相比,MACE改善了预填充、解码和微调阶段的延迟分解,并在NVIDIA AGX Orin上保持超过85%的GPU利用率。这些结果表明,迭代级别的混合调度是边缘平台部署具有持续学习能力的LLM的一个有希望的方向。
🔬 方法详解
问题定义:边缘部署的LLM需要根据不断变化的用户数据进行频繁重训练,以保持模型精度。然而,重训练会消耗大量计算资源,与推理任务竞争GPU资源,导致推理延迟增加。现有方法要么延迟模型更新,要么过度分配资源给重训练,要么忽略了迭代级别的重训练粒度,无法在推理延迟、模型精度和资源利用率之间取得最佳平衡。
核心思路:MACE的核心思路是协同推理(预填充和解码)和微调,并采用迭代级别的调度策略,根据模型漂移情况动态调整重训练频率。通过智能内存管理,MACE能够在有限的GPU资源下最大化任务性能,同时保证推理吞吐量。这种混合调度方法能够更精细地控制重训练过程,避免不必要的资源浪费,并及时更新模型以适应数据变化。
技术框架:MACE是一个混合LLM服务系统,包含以下主要模块:1) 推理引擎:负责执行LLM的推理任务,包括预填充和解码阶段。2) 微调模块:负责根据新数据对LLM进行微调。3) 调度器:根据模型漂移情况和SLO要求,动态调整推理和微调任务的资源分配。4) 内存管理器:负责管理GPU内存,确保推理和微调任务能够高效地共享内存资源。整体流程是:系统持续监控模型性能,当检测到模型漂移时,调度器会启动微调任务,并根据迭代级别的调度策略,动态调整推理和微调任务的资源分配,直到模型性能恢复到可接受的水平。
关键创新:MACE最重要的技术创新点在于迭代级别的混合调度策略。与传统的周期性重训练或持续重训练不同,MACE能够根据模型漂移情况,以迭代为单位动态调整重训练频率。这种精细化的调度策略能够更有效地利用GPU资源,避免不必要的资源浪费,并及时更新模型以适应数据变化。此外,MACE还采用了智能内存管理技术,确保推理和微调任务能够高效地共享GPU内存资源。
关键设计:MACE的关键设计包括:1) 模型漂移检测机制:用于检测模型性能下降情况,触发微调任务。2) 迭代级别的调度策略:根据模型漂移程度和SLO要求,动态调整推理和微调任务的资源分配。3) 智能内存管理策略:用于高效地管理GPU内存,确保推理和微调任务能够共享内存资源。具体的参数设置、损失函数和网络结构等技术细节在论文中可能未详细描述,属于实现层面的优化。
🖼️ 关键图片


📊 实验亮点
MACE的实验结果表明,与传统的持续重训练方法相比,MACE在降低推理延迟高达63%的同时,保持或超过了持续重训练的性能。此外,与周期性重训练相比,MACE改善了预填充、解码和微调阶段的延迟分解,并在NVIDIA AGX Orin上保持了超过85%的GPU利用率。这些结果证明了MACE在边缘LLM部署方面的优越性。
🎯 应用场景
MACE适用于各种需要低延迟和高精度的边缘LLM应用,例如个性化助手、推荐系统和内容审核。通过持续学习和自适应重训练,MACE能够使这些应用更好地适应不断变化的用户数据,提供更准确和个性化的服务。未来,MACE有望推动边缘智能的发展,使更多复杂的AI应用能够在资源受限的边缘设备上高效运行。
📄 摘要(原文)
Large language models (LLMs) deployed on edge servers are increasingly used in latency-sensitive applications such as personalized assistants, recommendation, and content moderation. However, the non-stationary nature of user data necessitates frequent retraining, which introduces a fundamental tension between inference latency and model accuracy under constrained GPU resources. Existing retraining strategies either delay model updates, over-commit resources to retraining, or overlook iteration-level retraining granularity. In this paper, we identify that iteration-level scheduling is crucial for adapting retraining frequency to model drift without violating service-level objectives (SLOs). We propose MACE, a hybrid LLM system that colocates concurrent inference (prefill, decode) and fine-tuning, with intelligent memory management to maximize task performance while promising inference throughput. MACE leverages the insight that not all model updates equally affect output alignment and allocates GPU cycles accordingly to balance throughput, latency, and update freshness. Our trace-driven evaluation shows that MACE matches or exceeds continuous retraining while reducing inference latency by up to 63% and maintaining throughput under resource constraints. Compared to periodic retraining, MACE improves latency breakdown across prefill, decode, and finetune stages, and sustains GPU utilization above 85% in NVIDIA AGX Orin. These results demonstrate that iteration-level hybrid scheduling is a promising direction for deploying LLMs with continual learning capabilities on edge platforms.