MemMamba: Rethinking Memory Patterns in State Space Model
作者: Youjin Wang, Yangjingyi Chen, Jiahao Yan, Jiaxuan Lu, Xiao Sun
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-28
💡 一句话要点
MemMamba:通过状态总结和跨层注意力,改进状态空间模型的长序列记忆能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 长序列建模 记忆增强 注意力机制 状态总结 线性复杂度 远距离依赖
📋 核心要点
- 现有长序列建模方法在效率和记忆能力之间存在权衡,Mamba虽然高效,但远距离记忆衰减严重。
- MemMamba通过状态总结机制和跨层、跨token注意力,在保持线性复杂度的同时,缓解长距离遗忘问题。
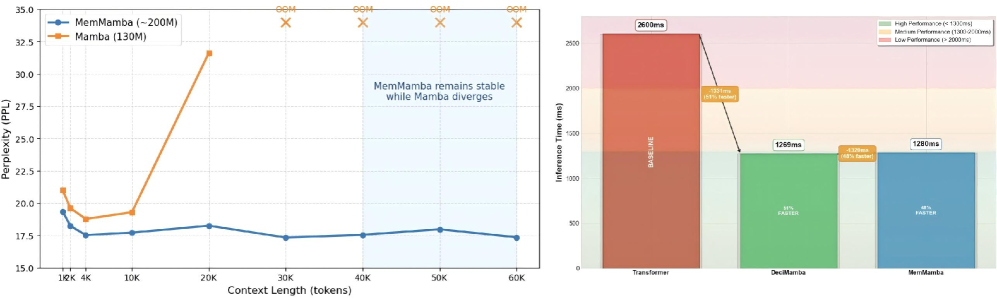
- MemMamba在长序列基准测试中优于现有Mamba变体和Transformer,推理效率提升48%,实现了复杂度-记忆的突破。
📝 摘要(中文)
随着数据爆炸式增长,长序列建模在自然语言处理和生物信息学等任务中变得越来越重要。然而,现有方法在效率和记忆之间存在固有的权衡。循环神经网络存在梯度消失和爆炸问题,难以扩展。Transformer可以建模全局依赖关系,但受到二次复杂度的限制。最近,像Mamba这样的选择性状态空间模型以O(n)的时间复杂度和O(1)的循环推理展示了高效率,但它们的远距离记忆呈指数衰减。本文通过数学推导和信息论分析,系统地揭示了Mamba的记忆衰减机制,回答了一个基本问题:Mamba的远距离记忆的本质是什么,以及它是如何保留信息的?为了量化关键信息损失,我们进一步引入了水平-垂直记忆保真度指标,以捕捉层内和跨层的退化。受到人类在阅读长文档时如何提取和保留显著信息的启发,我们提出了MemMamba,一种新颖的架构框架,它集成了状态总结机制以及跨层和跨token的注意力,从而减轻了远距离遗忘,同时保持了线性复杂度。MemMamba在PG19和Passkey Retrieval等长序列基准测试中,相对于现有的Mamba变体和Transformer,取得了显著的改进,同时在推理效率方面提高了48%。理论分析和实验结果都表明,MemMamba在复杂度-记忆权衡方面取得了突破,为超长序列建模提供了一种新的范例。
🔬 方法详解
问题定义:Mamba等状态空间模型在长序列建模中表现出高效性,但其远距离记忆能力存在指数衰减的问题。这限制了它们在需要长期依赖关系的任务中的应用。现有方法难以在效率和记忆能力之间取得平衡,需要一种既能保持线性复杂度,又能有效保留长距离信息的模型。
核心思路:MemMamba的核心思路是模拟人类阅读长文档时提取和保留关键信息的过程。通过引入状态总结机制,将序列中的关键信息进行提炼和压缩,并利用跨层和跨token的注意力机制,在不同层和不同token之间传递和增强这些关键信息,从而缓解长距离遗忘问题。
技术框架:MemMamba的整体架构包括以下几个主要模块:1) Mamba状态空间模型:作为基础的序列建模模块,负责处理输入序列并生成状态向量。2) 状态总结模块:对Mamba生成的状态向量进行总结,提取关键信息并压缩状态表示。3) 跨层注意力模块:允许不同层的状态向量之间进行信息交互,增强全局上下文理解。4) 跨token注意力模块:允许不同token的状态向量之间进行信息交互,捕捉局部依赖关系。整个流程是:输入序列首先通过Mamba模型,然后通过状态总结模块提取关键信息,最后通过跨层和跨token注意力模块进行信息增强和传递。
关键创新:MemMamba的关键创新在于将状态总结机制和跨层、跨token注意力机制集成到状态空间模型中。状态总结机制能够有效地提取和压缩序列中的关键信息,减少信息损失。跨层和跨token注意力机制能够增强全局上下文理解和局部依赖关系捕捉,从而提高模型的记忆能力。与现有Mamba变体相比,MemMamba能够更好地保留长距离信息,同时保持线性复杂度。
关键设计:状态总结模块的具体实现方式未知,论文中可能使用了某种池化或者自注意力机制来提取关键信息。跨层和跨token注意力模块的具体实现方式也未知,可能采用了Transformer中的多头注意力机制。损失函数的设计可能包括了对长距离依赖关系的建模,例如使用对比学习或者其他正则化方法来鼓励模型保留长距离信息。
🖼️ 关键图片


📊 实验亮点
MemMamba在PG19和Passkey Retrieval等长序列基准测试中取得了显著的改进。与现有Mamba变体和Transformer相比,MemMamba在保持线性复杂度的同时,能够更好地保留长距离信息。实验结果表明,MemMamba在推理效率方面提高了48%,证明了其在复杂度-记忆权衡方面的突破。
🎯 应用场景
MemMamba在需要处理超长序列的任务中具有广泛的应用前景,例如长文本理解、基因组序列分析、长时间序列预测等。它可以应用于自然语言处理、生物信息学、金融分析等领域,帮助人们更好地理解和利用海量数据,从而提高决策效率和准确性。未来,MemMamba有望成为超长序列建模的重要工具。
📄 摘要(原文)
With the explosive growth of data, long-sequence modeling has become increasingly important in tasks such as natural language processing and bioinformatics. However, existing methods face inherent trade-offs between efficiency and memory. Recurrent neural networks suffer from gradient vanishing and explosion, making them hard to scale. Transformers can model global dependencies but are constrained by quadratic complexity. Recently, selective state-space models such as Mamba have demonstrated high efficiency with O(n) time and O(1) recurrent inference, yet their long-range memory decays exponentially. In this work, we conduct mathematical derivations and information-theoretic analysis to systematically uncover the memory decay mechanism of Mamba, answering a fundamental question: what is the nature of Mamba's long-range memory and how does it retain information? To quantify key information loss, we further introduce horizontal-vertical memory fidelity metrics that capture degradation both within and across layers. Inspired by how humans distill and retain salient information when reading long documents, we propose MemMamba, a novel architectural framework that integrates state summarization mechanism together with cross-layer and cross-token attention, which alleviates long-range forgetting while preserving linear complexity. MemMamba achieves significant improvements over existing Mamba variants and Transformers on long-sequence benchmarks such as PG19 and Passkey Retrieval, while delivering a 48% speedup in inference efficiency. Both theoretical analysis and empirical results demonstrate that MemMamba achieves a breakthrough in the complexity-memory trade-off, offering a new paradigm for ultra-long sequence modeling.