In-Context Compositional Q-Learning for Offline Reinforcement Learning
作者: Qiushui Xu, Yuhao Huang, Yushu Jiang, Lei Song, Jinyu Wang, Wenliang Zheng, Jiang Bian
分类: cs.LG, cs.AI
发布日期: 2025-09-28
💡 一句话要点
提出ICQL,利用上下文学习进行离线强化学习中的组合Q函数估计
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 Q学习 上下文学习 Transformer 组合性 价值估计 机器人控制
📋 核心要点
- 现有离线强化学习方法依赖单一全局Q函数,难以处理包含多个子任务的复杂任务。
- ICQL将Q学习建模为上下文推理,利用线性Transformer从检索到的经验中推断局部Q函数。
- 实验表明,ICQL在厨房、Gym和Adroit等任务中显著提升了性能,验证了其有效性。
📝 摘要(中文)
精确估计Q函数是离线强化学习中的核心挑战。然而,现有方法通常依赖于单一的全局Q函数,难以捕捉涉及多样化子任务的任务的组合特性。我们提出了上下文组合Q学习(ICQL),这是第一个将Q学习公式化为上下文推理问题的离线强化学习框架,它使用线性Transformer从检索到的转换中自适应地推断局部Q函数,而无需显式的子任务标签。理论上,我们证明了在两个假设下——局部Q函数的线性可近似性和从检索到的上下文中准确的权重推断——ICQL实现了有界的Q函数近似误差,并支持近乎最优的策略提取。实验结果表明,ICQL显著提高了离线环境下的性能:在厨房任务中提高了高达16.4%,在Gym和Adroit任务中分别提高了高达8.6%和6.3%。这些结果突出了上下文学习在鲁棒和组合价值估计方面未被充分探索的潜力,并将ICQL定位为离线强化学习的一个有原则且有效的框架。
🔬 方法详解
问题定义:离线强化学习中,精确估计Q函数是一个关键挑战。现有方法主要依赖于单一的全局Q函数,这在处理具有组合性质的任务(即任务可以分解为多个子任务)时表现不佳,因为全局Q函数难以捕捉不同子任务之间的差异和联系。因此,如何有效地学习组合式的Q函数,从而提升离线强化学习的性能,是本文要解决的问题。
核心思路:ICQL的核心思路是将Q学习过程视为一个上下文推理问题。具体来说,对于给定的状态,ICQL不是直接使用一个全局Q函数来估计Q值,而是首先从离线数据集中检索与当前状态相关的经验(即上下文),然后基于这些上下文信息,自适应地推断出一个局部的Q函数。这种局部Q函数能够更好地捕捉当前状态下特定子任务的价值,从而提高Q函数估计的准确性。
技术框架:ICQL的整体框架主要包括以下几个模块:1) 上下文检索模块:负责从离线数据集中检索与当前状态相关的经验。2) 权重推断模块:使用线性Transformer网络,根据检索到的上下文信息,推断出每个经验的权重。3) 局部Q函数构建模块:根据推断出的权重,将检索到的经验进行加权组合,构建一个局部的Q函数。4) Q值估计模块:使用构建的局部Q函数,估计当前状态的Q值。
关键创新:ICQL的关键创新在于它将Q学习过程建模为一个上下文推理问题,并利用线性Transformer网络自适应地推断局部Q函数。与现有方法相比,ICQL不需要显式的子任务标签,而是通过检索和组合相关的经验,自动地学习到组合式的Q函数。此外,ICQL的理论分析表明,在一定的假设下,它可以实现有界的Q函数近似误差,并支持近乎最优的策略提取。
关键设计:ICQL的关键设计包括:1) 使用线性Transformer网络进行权重推断,这可以降低计算复杂度,并提高泛化能力。2) 使用余弦相似度作为上下文检索的度量标准,这可以有效地捕捉状态之间的相似性。3) 损失函数的设计,旨在最小化Q函数的近似误差,并鼓励策略的探索。
🖼️ 关键图片
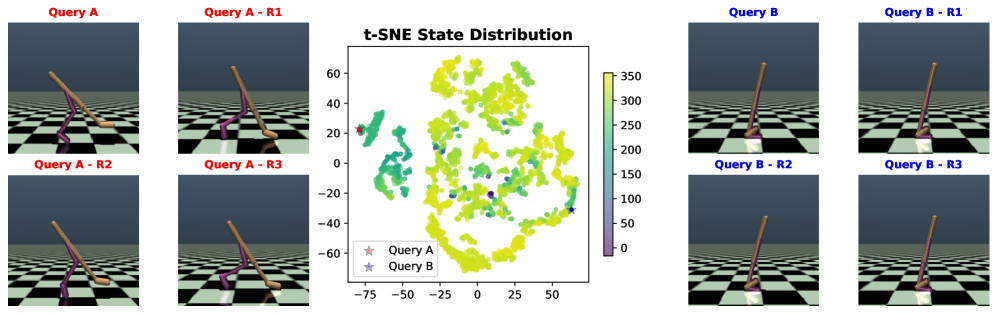

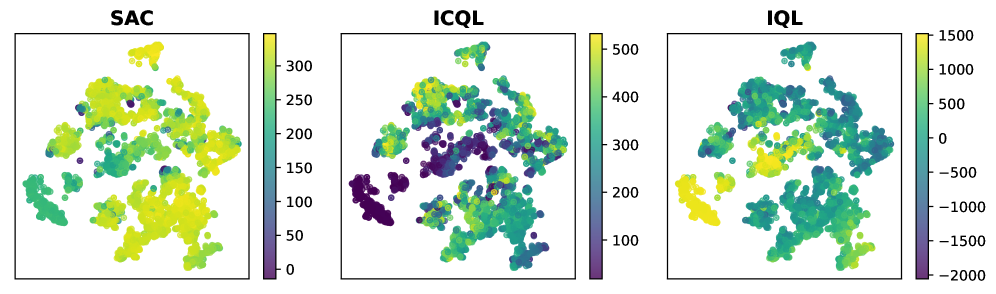
📊 实验亮点
ICQL在多个离线强化学习任务中取得了显著的性能提升。在厨房任务中,ICQL相比于基线方法提高了高达16.4%的性能。在Gym和Adroit任务中,ICQL分别提高了高达8.6%和6.3%的性能。这些结果表明,ICQL能够有效地学习组合式的Q函数,并提高离线强化学习的性能。
🎯 应用场景
ICQL在机器人控制、游戏AI、推荐系统等领域具有广泛的应用前景。例如,在机器人控制中,ICQL可以用于学习复杂的操作技能,如烹饪、装配等。在游戏AI中,ICQL可以用于训练更智能的游戏角色,使其能够更好地适应不同的游戏环境。在推荐系统中,ICQL可以用于个性化推荐,根据用户的历史行为,推荐更符合用户兴趣的商品或服务。ICQL的未来发展方向包括探索更有效的上下文检索方法、更强大的权重推断模型,以及更广泛的应用场景。
📄 摘要(原文)
Accurately estimating the Q-function is a central challenge in offline reinforcement learning. However, existing approaches often rely on a single global Q-function, which struggles to capture the compositional nature of tasks involving diverse subtasks. We propose In-context Compositional Q-Learning (\texttt{ICQL}), the first offline RL framework that formulates Q-learning as a contextual inference problem, using linear Transformers to adaptively infer local Q-functions from retrieved transitions without explicit subtask labels. Theoretically, we show that under two assumptions--linear approximability of the local Q-function and accurate weight inference from retrieved context--\texttt{ICQL} achieves bounded Q-function approximation error, and supports near-optimal policy extraction. Empirically, \texttt{ICQL} substantially improves performance in offline settings: improving performance in kitchen tasks by up to 16.4\%, and in Gym and Adroit tasks by up to 8.6\% and 6.3\%. These results highlight the underexplored potential of in-context learning for robust and compositional value estimation, positioning \texttt{ICQL} as a principled and effective framework for offline RL.