Guide: Generalized-Prior and Data Encoders for DAG Estimation
作者: Amartya Roy, Devharish N, Shreya Ganguly, Kripabandhu Ghosh
分类: cs.LG, cs.AI
发布日期: 2025-09-28
💡 一句话要点
GUIDE:融合LLM先验与数据编码的DAG估计框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果发现 DAG估计 大型语言模型 强化学习 双编码器 混合数据类型 可扩展性
📋 核心要点
- 现有因果发现方法在节点扩展性、计算效率和混合数据处理上存在瓶颈,限制了其应用。
- GUIDE框架融合LLM先验知识与观测数据,利用双编码器架构优化DAG估计,提升效率和精度。
- 实验表明,GUIDE在运行时间和精度上显著优于现有方法,尤其是在大规模和混合数据场景下。
📝 摘要(中文)
现代因果发现方法在可扩展性、计算效率和混合数据类型适应性方面面临严峻挑战。传统算法如PC、GES和ICA-LiNGAM在高阶节点上计算成本高昂,且超过70个节点时扩展性差。我们提出了GUIDE,一个通过双编码器架构整合大型语言模型(LLM)生成的邻接矩阵和观测数据的框架。GUIDE优化了计算效率,运行时间平均减少约42%(相比RL-BIC和KCRL),精度平均提高约117%(相比NOTEARS和GraN-DAG)。在训练期间,GUIDE的强化学习代理动态平衡奖励最大化(精度)和惩罚避免(DAG约束),从而在混合数据类型和≥70个节点的可扩展性上实现稳健的性能。
🔬 方法详解
问题定义:现有的因果发现方法,如PC、GES和ICA-LiNGAM,在处理大规模数据集(节点数超过70)时,计算复杂度急剧增加,导致运行时间过长和能源消耗过高。此外,这些方法在处理混合数据类型(例如,连续型和离散型数据)时表现不佳,限制了其在实际应用中的适用性。因此,需要一种更高效、可扩展且能处理混合数据类型的因果发现方法。
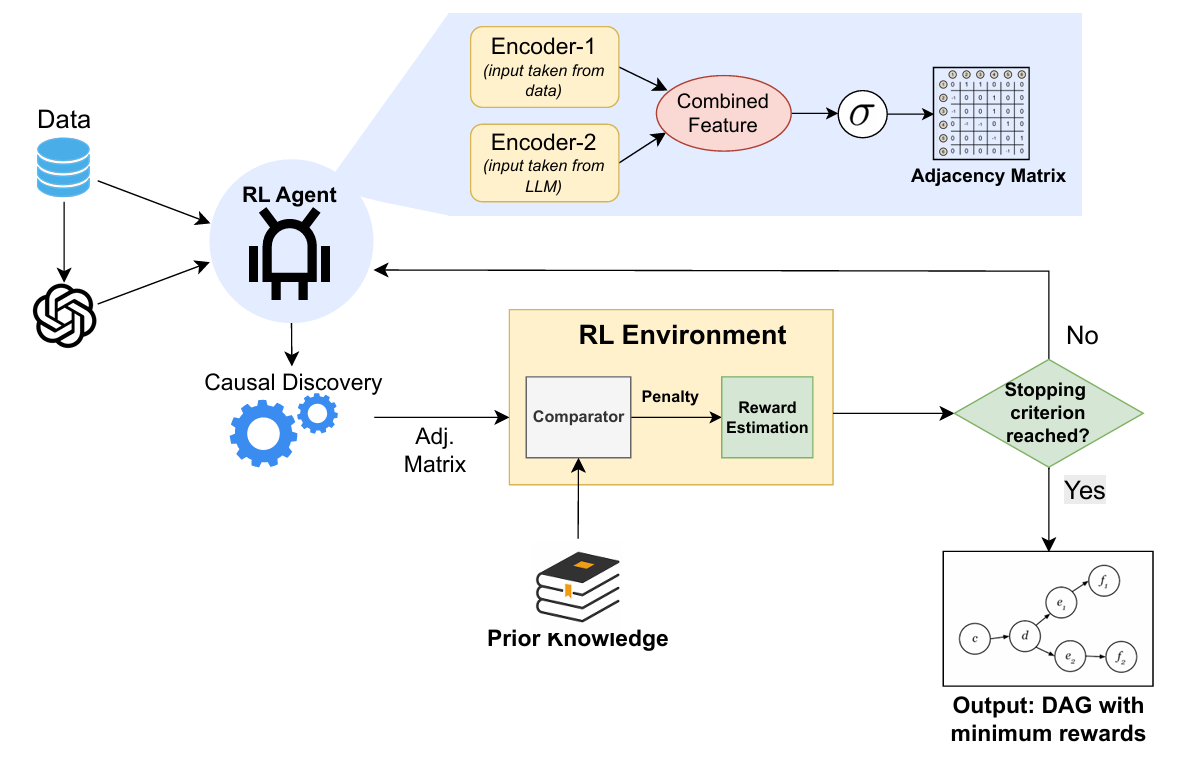
核心思路:GUIDE的核心思路是利用大型语言模型(LLM)生成关于因果结构的先验知识,并将其与观测数据相结合,以指导DAG(有向无环图)的估计过程。通过LLM提供的先验信息可以减少搜索空间,从而提高计算效率。同时,GUIDE采用双编码器架构,分别处理LLM生成的先验知识和观测数据,并通过强化学习动态平衡两者之间的关系,从而实现更准确的DAG估计。
技术框架:GUIDE框架包含以下主要模块:1) LLM先验生成器:利用LLM生成关于因果结构的邻接矩阵,作为先验知识。2) 数据编码器:将观测数据编码成低维表示。3) 先验编码器:将LLM生成的邻接矩阵编码成低维表示。4) 强化学习代理:根据数据编码器和先验编码器的输出,动态调整DAG估计过程,并平衡精度和DAG约束。整个框架通过端到端的方式进行训练,目标是最大化奖励(精度)并避免惩罚(违反DAG约束)。
关键创新:GUIDE的关键创新在于:1) 融合LLM生成的先验知识,减少搜索空间,提高计算效率。2) 采用双编码器架构,分别处理先验知识和观测数据,实现更灵活的融合。3) 使用强化学习动态平衡精度和DAG约束,提高鲁棒性。与现有方法相比,GUIDE能够更好地处理大规模和混合数据类型的因果发现问题。
关键设计:GUIDE的关键设计包括:1) LLM的选择:选择合适的LLM,并设计合适的prompt,以生成高质量的先验知识。2) 编码器结构:设计合适的编码器结构,将数据和先验知识编码成低维表示。3) 强化学习奖励函数:设计合适的奖励函数,以平衡精度和DAG约束。例如,奖励函数可以包括估计DAG的结构得分(例如,BIC)和违反DAG约束的惩罚项。4) 强化学习算法:选择合适的强化学习算法,例如,Policy Gradient或Q-learning,以训练强化学习代理。
🖼️ 关键图片

📊 实验亮点
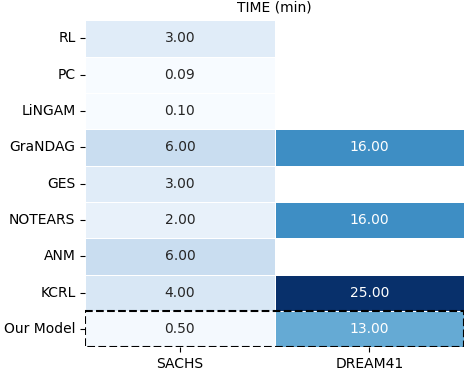
实验结果表明,GUIDE在运行时间和精度上显著优于现有方法。具体而言,GUIDE的运行时间平均减少约42%(相比RL-BIC和KCRL),精度平均提高约117%(相比NOTEARS和GraN-DAG)。此外,GUIDE在处理大规模数据集(节点数≥70)和混合数据类型时表现出更强的鲁棒性,而现有方法在这些场景下往往失效。这些结果表明,GUIDE是一种高效、可扩展且能处理混合数据类型的因果发现方法。
🎯 应用场景
GUIDE框架具有广泛的应用前景,例如:在生物医学领域,可以用于发现基因之间的因果关系,从而帮助理解疾病的发生机制;在金融领域,可以用于分析市场风险因素之间的因果关系,从而帮助制定更有效的风险管理策略;在社交网络分析中,可以用于识别信息传播的影响因素,从而帮助优化信息传播策略。此外,GUIDE还可以应用于智能推荐、自动驾驶等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Modern causal discovery methods face critical limitations in scalability, computational efficiency, and adaptability to mixed data types, as evidenced by benchmarks on node scalability (30, $\le 50$, $\ge 70$ nodes), computational energy demands, and continuous/non-continuous data handling. While traditional algorithms like PC, GES, and ICA-LiNGAM struggle with these challenges, exhibiting prohibitive energy costs for higher-order nodes and poor scalability beyond 70 nodes, we propose \textbf{GUIDE}, a framework that integrates Large Language Model (LLM)-generated adjacency matrices with observational data through a dual-encoder architecture. GUIDE uniquely optimizes computational efficiency, reducing runtime on average by $\approx 42%$ compared to RL-BIC and KCRL methods, while achieving an average $\approx 117%$ improvement in accuracy over both NOTEARS and GraN-DAG individually. During training, GUIDE's reinforcement learning agent dynamically balances reward maximization (accuracy) and penalty avoidance (DAG constraints), enabling robust performance across mixed data types and scalability to $\ge 70$ nodes -- a setting where baseline methods fail.