Curriculum-Guided Reinforcement Learning for Synthesizing Gas-Efficient Financial Derivatives Contracts
作者: Maruf Ahmed Mridul, Oshani Seneviratne
分类: cs.LG
发布日期: 2025-09-28
备注: 8 pages, 3 figures, 2 tables
💡 一句话要点
提出基于课程学习的强化学习框架,用于合成高 gas 效率的金融衍生品智能合约。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 智能合约 强化学习 金融衍生品 gas优化 课程学习 PPO 代码生成
📋 核心要点
- 现有方法难以将金融规范转化为 gas 高效的可执行代码,阻碍了智能合约在金融衍生品领域的实际应用。
- 论文提出基于课程学习的强化学习框架,通过 PPO 智能体学习选择最优代码片段,实现功能正确性和 gas 优化。
- 实验结果表明,该方法生成的智能合约在 gas 成本上显著降低,与基线相比降低高达 35.59%。
📝 摘要(中文)
本文提出了一种强化学习(RL)框架,用于直接从通用领域模型(CDM)规范生成功能正确且 gas 优化的 Solidity 智能合约。该框架采用近端策略优化(PPO)智能体,学习从预定义的代码片段库中选择最佳代码片段。为了管理复杂的搜索空间,采用两阶段课程学习,首先训练智能体以保证功能正确性,然后将其重点转移到 gas 优化。实验结果表明,该 RL 智能体学会生成具有显著 gas 节省的合约,与未优化的基线相比,在未见测试数据上实现了高达 35.59% 的成本降低。这项工作为自动合成可靠且经济可持续的智能合约提供了一种可行的方法,弥合了高级金融协议和高效链上执行之间的差距。
🔬 方法详解
问题定义:现有方法在将高级金融规范(如 CDM)转换为 gas 效率高的智能合约代码时面临挑战。直接从 CDM 生成既功能正确又经济可行的智能合约非常困难,因为搜索空间巨大,且功能正确性和 gas 效率之间存在权衡。
核心思路:论文的核心思路是利用强化学习自动搜索最优的代码片段组合,从而生成满足 CDM 规范且 gas 消耗最小的智能合约。通过课程学习,逐步引导智能体从关注功能正确性过渡到关注 gas 优化,从而简化学习过程。
技术框架:该框架包含以下主要模块:1) CDM 规范解析器:将 CDM 规范转换为智能体可以理解的状态表示。2) 代码片段库:包含预定义的 Solidity 代码片段,智能体从中选择。3) PPO 智能体:负责根据当前状态选择代码片段,并根据奖励信号进行学习。4) 奖励函数:用于评估生成的合约的功能正确性和 gas 效率。5) 课程学习策略:分阶段训练智能体,先关注功能正确性,后关注 gas 优化。
关键创新:该方法的主要创新在于:1) 将强化学习应用于智能合约的自动生成,克服了传统方法的局限性。2) 采用课程学习策略,有效地管理了复杂的搜索空间,提高了学习效率。3) 设计了合适的奖励函数,平衡了功能正确性和 gas 效率。
关键设计:PPO 智能体使用 Actor-Critic 网络结构,Actor 网络负责选择代码片段,Critic 网络负责评估当前状态的价值。奖励函数由两部分组成:功能正确性奖励和 gas 惩罚。功能正确性奖励基于生成的合约是否满足 CDM 规范,gas 惩罚基于合约的 gas 消耗量。课程学习策略分为两个阶段:第一阶段只考虑功能正确性奖励,第二阶段同时考虑功能正确性奖励和 gas 惩罚。
🖼️ 关键图片

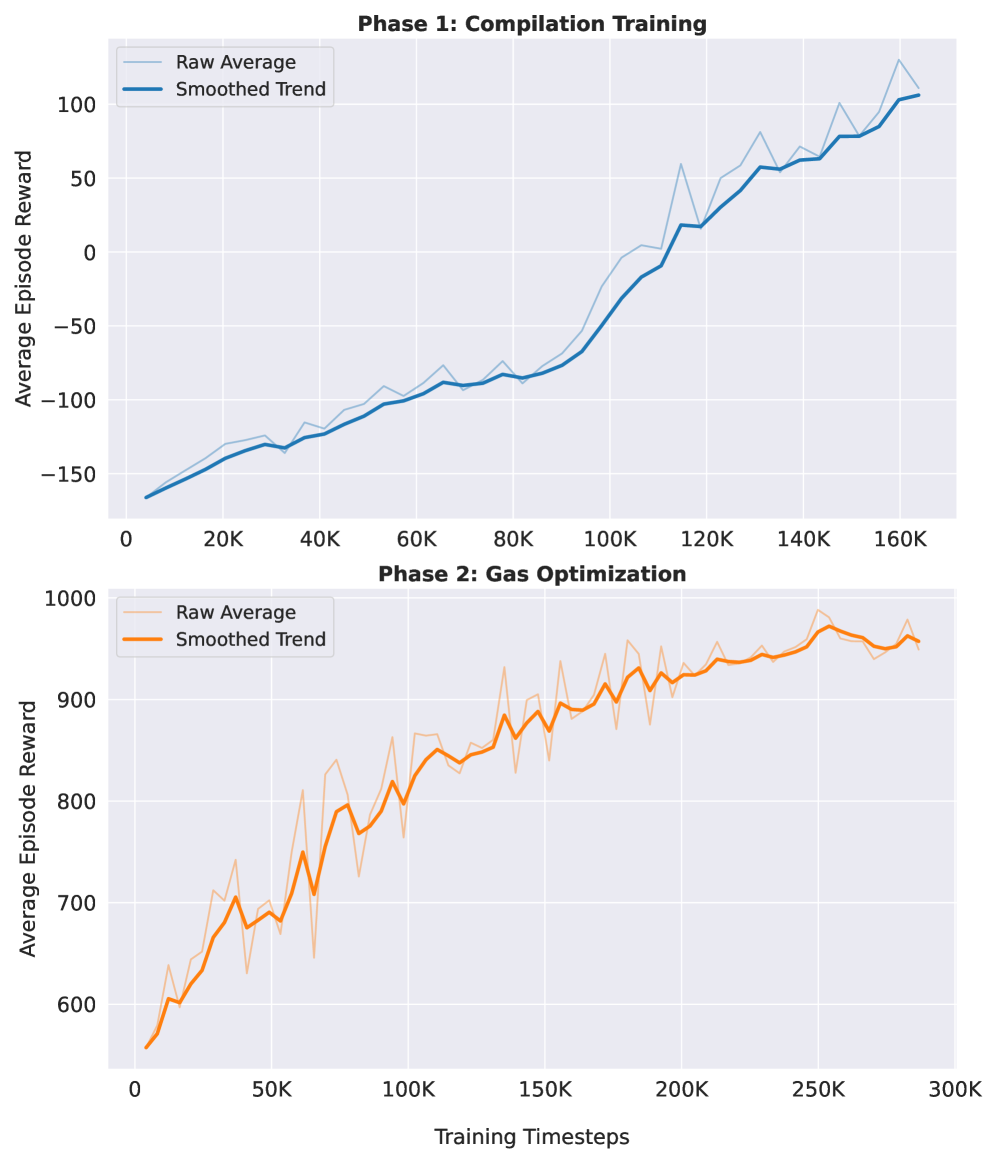

📊 实验亮点
实验结果表明,该方法生成的智能合约在 gas 成本上显著降低,与未优化的基线相比,在未见测试数据上实现了高达 35.59% 的成本降低。这表明该方法能够有效地生成 gas 效率高的智能合约,具有实际应用价值。
🎯 应用场景
该研究成果可应用于金融衍生品智能合约的自动生成,降低开发成本,提高开发效率,并促进智能合约在金融领域的广泛应用。通过自动生成 gas 优化的合约,可以降低交易成本,提高链上交易的经济可行性,从而推动 DeFi 生态系统的发展。
📄 摘要(原文)
Smart contract-based automation of financial derivatives offers substantial efficiency gains, but its real-world adoption is constrained by the complexity of translating financial specifications into gas-efficient executable code. In particular, generating code that is both functionally correct and economically viable from high-level specifications, such as the Common Domain Model (CDM), remains a significant challenge. This paper introduces a Reinforcement Learning (RL) framework to generate functional and gas-optimized Solidity smart contracts directly from CDM specifications. We employ a Proximal Policy Optimization (PPO) agent that learns to select optimal code snippets from a pre-defined library. To manage the complex search space, a two-phase curriculum first trains the agent for functional correctness before shifting its focus to gas optimization. Our empirical results show the RL agent learns to generate contracts with significant gas savings, achieving cost reductions of up to 35.59% on unseen test data compared to unoptimized baselines. This work presents a viable methodology for the automated synthesis of reliable and economically sustainable smart contracts, bridging the gap between high-level financial agreements and efficient on-chain execution.