Explore-Execute Chain: Towards an Efficient Structured Reasoning Paradigm
作者: Kaisen Yang, Lixuan He, Rushi Shah, Kaicheng Yang, Qinwei Ma, Dianbo Liu, Alex Lamb
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-09-28 (更新: 2025-09-30)
🔗 代码/项目: GITHUB
💡 一句话要点
提出Explore-Execute Chain框架,解耦规划与执行,提升LLM推理效率与可解释性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理 探索-执行链 强化学习 监督微调 可解释性 效率优化
📋 核心要点
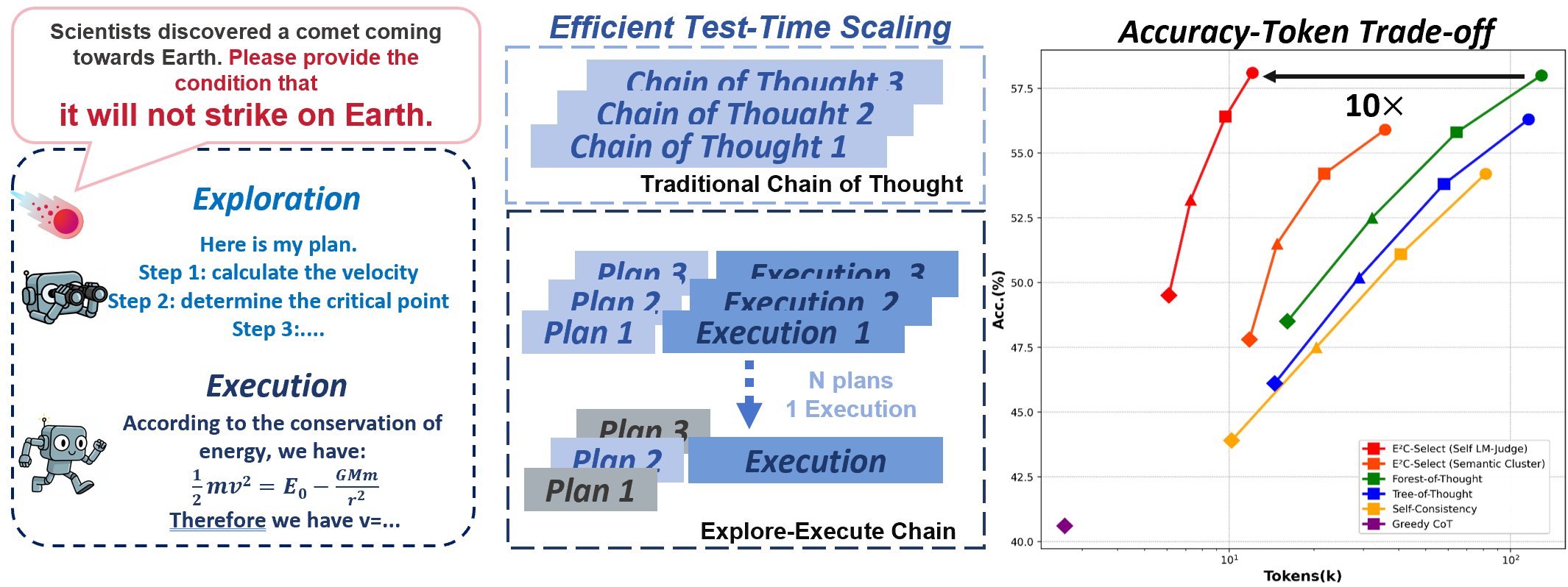
- 现有CoT方法将高层规划与低层执行混淆,导致计算效率低、推理路径探索受限、可解释性差。
- 提出Explore-Execute Chain框架,将推理过程解耦为探索和执行两个阶段,分别负责规划和执行。
- 实验表明,$E^2C$在推理效率、准确率和跨领域泛化能力上均优于现有方法,并提升了可解释性。
📝 摘要(中文)
本文提出Explore-Execute Chain ($E^2C$),一种结构化推理框架,旨在解决大型语言模型(LLM)在推理过程中高层战略规划与低层逐步执行相混淆的问题,从而提高计算效率、扩展推理路径探索并增强可解释性。$E^2C$将推理过程解耦为两个阶段:探索阶段随机生成简洁的高层计划,执行阶段确定性地执行所选计划。该方法采用两阶段训练策略,结合监督微调(SFT)——通过一种强制计划严格执行的新型数据生成算法增强——以及强化学习(RL)阶段,利用探索的信息性并强化执行的确定性。在AIME'2024上,$E^2C$测试时扩展策略仅使用同类方法(如Forest-of-Thought)不到10%的解码token,准确率达到58.1%,显著降低了自洽性开销。对于跨领域适应,我们的探索聚焦SFT(EF-SFT)仅使用标准SFT 3.5%的token进行微调,在医疗基准测试中,准确率比标准SFT高出14.5%,实现了最先进的性能、强大的泛化能力,并通过分离规划和执行提高了可解释性。项目代码和预训练模型已在https://github.com/yks23/Explore-Execute-Chain.git上发布。
🔬 方法详解
问题定义:现有Chain-of-Thought (CoT)及其变体在提升大型语言模型(LLM)的推理能力方面取得了显著进展。然而,它们采用的单片式自回归架构将高层战略规划与低层逐步执行混为一谈。这种耦合导致计算效率低下,推理路径探索受限,并且降低了模型的可解释性。具体来说,模型在每一步都需要进行复杂的决策,既要考虑全局规划,又要执行具体步骤,这增加了计算负担,限制了模型探索不同推理路径的能力,并且难以理解模型的推理过程。
核心思路:Explore-Execute Chain ($E^2C$) 的核心思路是将推理过程解耦为两个独立的阶段:探索阶段和执行阶段。探索阶段负责生成简洁的高层计划,该阶段允许一定的随机性,以便探索不同的计划选项。执行阶段则负责确定性地执行所选的计划。通过这种解耦,模型可以将精力集中在每个阶段的任务上,从而提高效率和可解释性。这种设计模仿了人类解决问题的过程,即先制定一个大致的计划,然后再按照计划逐步执行。
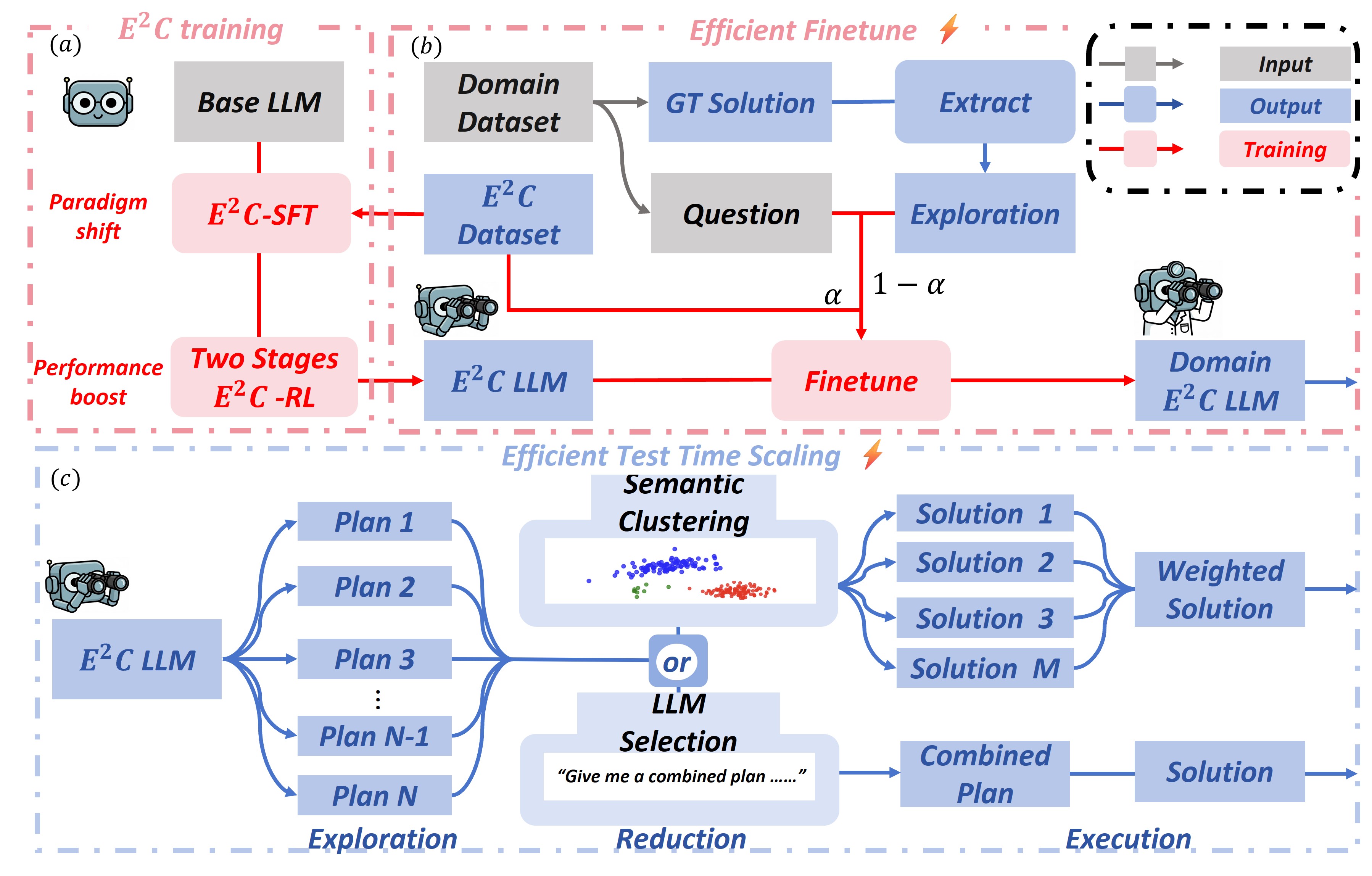
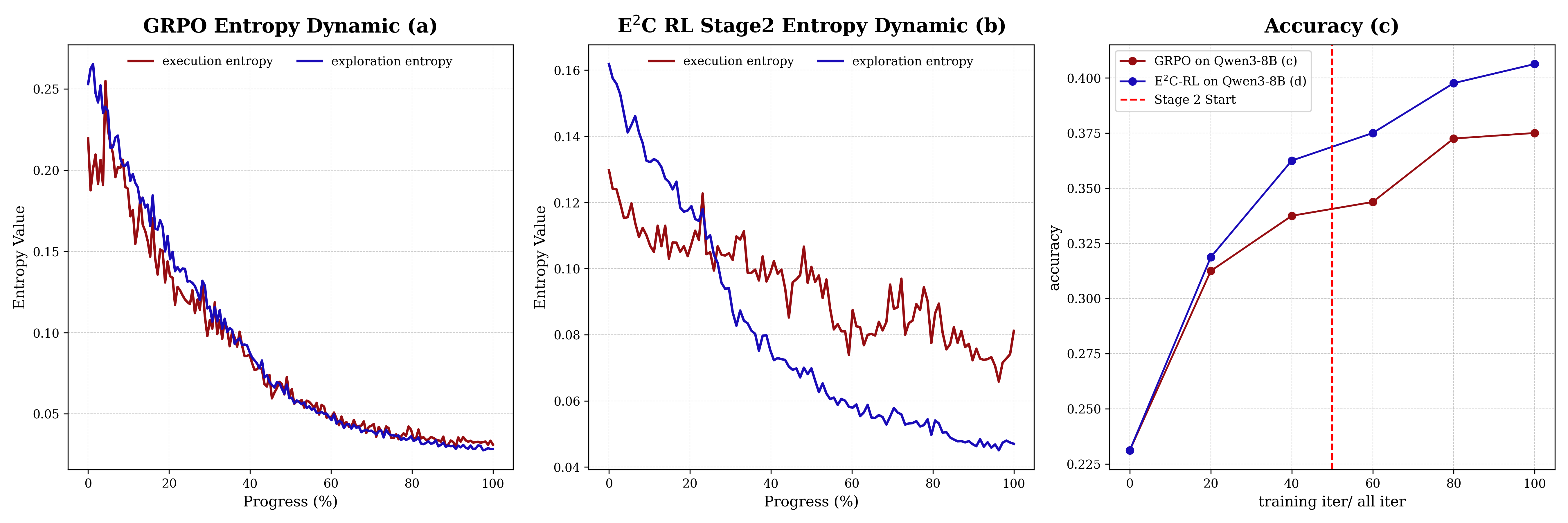
技术框架:$E^2C$ 框架包含两个主要阶段:探索阶段和执行阶段。在探索阶段,模型接收输入问题,并生成一个或多个高层计划。这些计划是对解决问题的步骤的简要描述。在执行阶段,模型选择一个计划,并按照该计划逐步执行,最终得到答案。该框架采用两阶段训练方法:首先,使用监督微调(SFT)训练模型,使其能够生成高质量的计划并准确地执行这些计划。然后,使用强化学习(RL)进一步优化模型,使其能够更好地探索不同的计划选项,并选择最佳的计划。SFT阶段使用了一种新的数据生成算法,该算法强制模型严格遵守计划。RL阶段利用探索的信息性,并强化执行的确定性。
关键创新:$E^2C$ 的最关键创新在于将推理过程解耦为探索和执行两个阶段。这种解耦使得模型能够更有效地利用计算资源,探索更多的推理路径,并提高可解释性。与传统的CoT方法相比,$E^2C$ 能够更好地平衡全局规划和局部执行,从而提高推理的准确性和效率。此外,探索聚焦SFT(EF-SFT)是一种高效的微调方法,它能够以更少的计算资源实现更好的性能。
关键设计:在SFT阶段,使用了一种新的数据生成算法,该算法强制模型严格遵守计划。具体来说,该算法首先生成一个高层计划,然后生成与该计划一致的推理步骤。在训练过程中,模型被要求预测这些推理步骤。这种方法可以有效地提高模型执行计划的能力。在RL阶段,使用了一种奖励函数,该函数鼓励模型探索不同的计划选项,并选择最佳的计划。该奖励函数基于模型的准确性和效率。此外,还使用了特殊的masking策略来保证执行阶段的确定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,$E^2C$ 在 AIME'2024 数据集上,使用不到 Forest-of-Thought 10% 的 token,达到了 58.1% 的准确率,显著降低了计算开销。在跨领域适应方面,EF-SFT 仅使用标准 SFT 3.5% 的 token,在医疗基准测试中,准确率比标准 SFT 提高了 14.5%。这些结果表明,$E^2C$ 具有更高的效率、准确性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的领域,例如数学问题求解、医疗诊断、法律推理等。通过提高LLM的推理效率和可解释性,可以降低计算成本,并增强模型在关键决策场景中的可靠性。未来,该方法有望应用于机器人控制、智能助手等领域,实现更智能、更高效的自动化。
📄 摘要(原文)
Chain-of-Thought (CoT) and its variants have markedly advanced the reasoning abilities of Large Language Models (LLMs), yet their monolithic and auto-regressive architecture inherently conflates high-level strategic planning with low-level step-by-step execution, leading to computational inefficiency, limited exploration of reasoning paths, and reduced interpretability. To overcome these issues, we propose the Explore-Execute Chain ($E^2C$), a structured reasoning framework that decouples reasoning into two distinct phases: an exploratory phase that stochastically generates succinct high-level plans, followed by an execution phase that deterministically carries out the chosen plan. Our approach incorporates a two-stage training methodology, which combines Supervised Fine-Tuning (SFT) - augmented by a novel data generation algorithm enforcing strict plan adherence - with a subsequent Reinforcement Learning (RL) stage that capitalizes on the informativeness of exploration and reinforces the determinism of execution. This decomposition enables an efficient test-time scaling strategy: on AIME'2024, $E^2C$ Test Time Scaling reaches 58.1% accuracy using <10% of the decoding tokens required by comparable methods (e.g., Forest-of-Thought), sharply cutting self-consistency overhead. For cross-domain adaptation, our Exploration-Focused SFT (EF-SFT) fine-tunes with only 3.5% of the tokens used by standard SFT yet yields up to 14.5% higher accuracy than standard SFT on medical benchmarks, delivering state-of-the-art performance, strong generalization, and greater interpretability by separating planning from execution. The code and pre-trained models for the project are available at: https://github.com/yks23/Explore-Execute-Chain.git