Dynamic Orthogonal Continual Fine-tuning for Mitigating Catastrophic Forgettings
作者: Zhixin Zhang, Zeming Wei, Meng Sun
分类: cs.LG, cs.AI, cs.CL, cs.CR, math.OC
发布日期: 2025-09-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出动态正交持续微调(DOC)以缓解LLM持续学习中的灾难性遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 灾难性遗忘 大型语言模型 微调 正交约束
📋 核心要点
- 现有基于正则化的持续学习方法在LLM长期持续学习中失效,主要原因是微调过程中功能方向的漂移。
- DOC方法通过跟踪功能方向的漂移并动态更新,同时使新任务梯度与历史功能方向正交,从而缓解新旧任务间的干扰。
- 在多个LLM持续学习基准测试中,DOC方法显著优于现有方法,有效降低了灾难性遗忘现象。
📝 摘要(中文)
灾难性遗忘仍然是大型语言模型(LLM)持续学习中的一个关键挑战,当模型在新的顺序数据上进行微调时,在无法访问过去数据集的情况下,模型难以保持在历史任务上的性能。本文首先揭示了微调过程中功能方向的漂移是现有基于正则化方法在长期LLM持续学习中失败的关键原因。为了解决这个问题,我们提出了一种新的动态正交持续(DOC)微调方法,该方法跟踪这些功能方向的漂移,并在微调过程中动态更新它们。此外,通过调整新任务参数的梯度,使其与跟踪的历史功能方向正交,我们的方法减轻了新旧任务之间的干扰。在各种LLM持续学习基准上的大量实验表明,该方法优于现有方法,有效地减少了灾难性遗忘,并为持续LLM微调提供了一个强大的工具。代码可在https://github.com/meloxxxxxx/DOC 获取。
🔬 方法详解
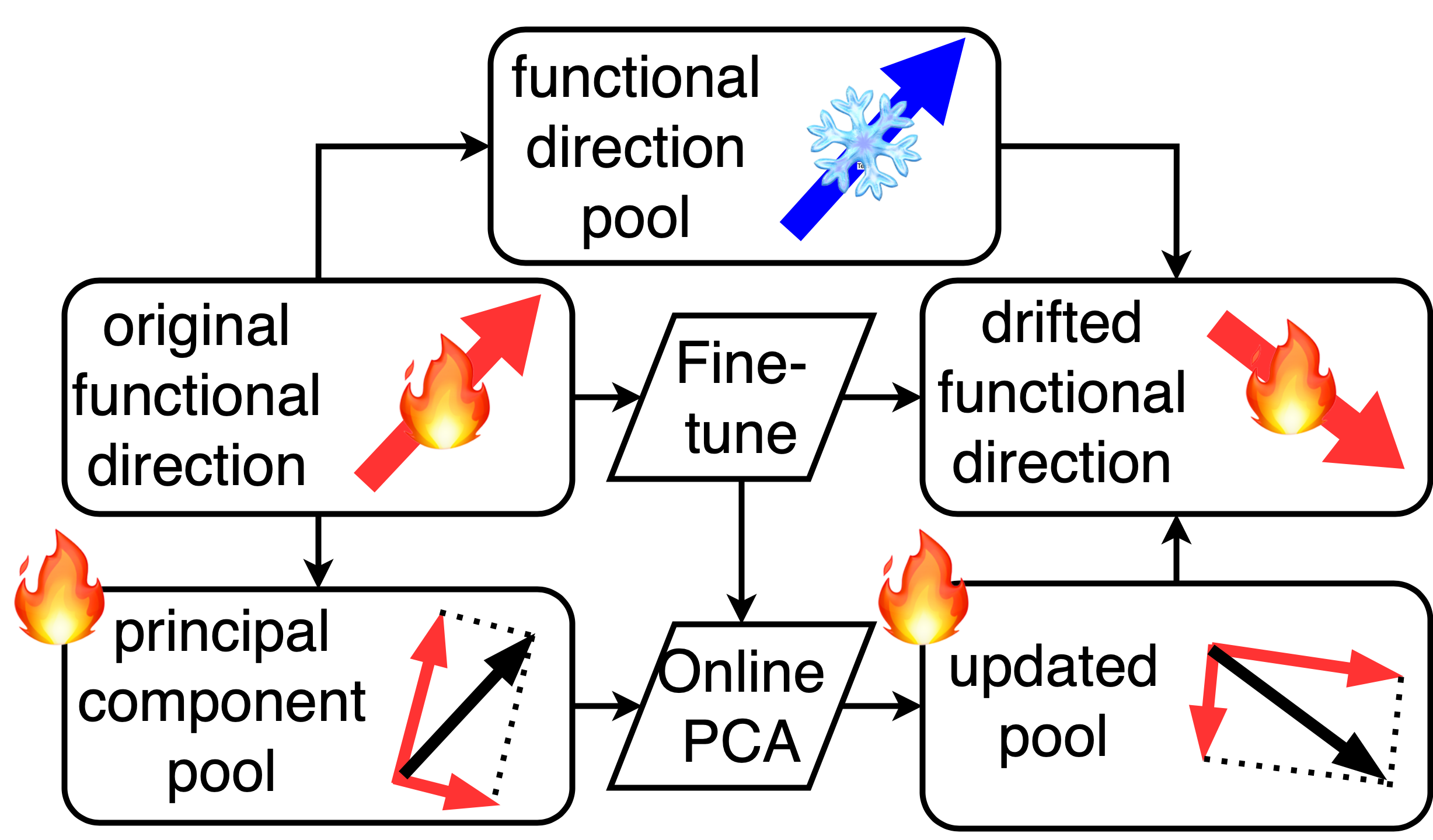
问题定义:论文旨在解决大型语言模型(LLM)在持续学习过程中遇到的灾难性遗忘问题。现有方法,特别是基于正则化的方法,在长期持续学习中表现不佳,无法有效保持模型在先前任务上的性能。这些方法未能充分考虑微调过程中功能方向的漂移,导致新任务的学习干扰了旧任务的知识。
核心思路:论文的核心思路是跟踪并动态更新微调过程中功能方向的漂移,并使新任务的梯度与历史功能方向保持正交。通过这种方式,可以减少新任务对旧任务的干扰,从而缓解灾难性遗忘。正交性约束确保新任务的学习不会显著改变模型在先前任务上学习到的功能。
技术框架:DOC方法主要包含两个关键步骤:1) 动态跟踪功能方向的漂移:在微调过程中,持续监控并更新代表历史任务功能方向的向量。2) 正交梯度调整:在计算新任务的梯度时,将其投影到与历史功能方向正交的子空间中,从而避免对历史知识的破坏。整体流程是,在每个新任务到来时,先利用历史任务的信息初始化功能方向,然后在微调过程中动态更新这些方向,并利用正交约束调整梯度。
关键创新:DOC方法的关键创新在于动态地跟踪和更新功能方向,并利用正交约束来调整梯度。与现有方法相比,DOC方法能够更准确地捕捉微调过程中知识的演变,并更有效地防止新旧任务之间的干扰。现有方法通常采用固定的正则化项,无法适应功能方向的动态变化。
关键设计:DOC方法的关键设计包括:1) 功能方向的表示:可以使用模型参数的梯度或激活值的方向来表示功能方向。2) 漂移跟踪机制:可以使用滑动平均或其他方法来平滑功能方向的更新。3) 正交投影的计算:可以使用Gram-Schmidt正交化或其他方法将梯度投影到正交子空间中。4) 超参数的选择:需要仔细调整控制正交约束强度的超参数,以平衡新任务的学习和旧任务的保持。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DOC方法在多个LLM持续学习基准测试中显著优于现有方法。例如,在某个基准测试中,DOC方法相比最佳基线方法,在所有任务上的平均性能提升了5%以上,并且在长期持续学习场景下,性能优势更加明显。这些结果验证了DOC方法在缓解灾难性遗忘方面的有效性。
🎯 应用场景
该研究成果可应用于需要持续学习新知识的LLM应用场景,例如智能客服、对话系统、信息检索等。通过缓解灾难性遗忘,模型可以不断适应新的用户需求和数据分布,提高长期性能和用户体验。此外,该方法还可以用于训练资源受限的场景,避免每次学习新任务时都需要从头开始训练模型。
📄 摘要(原文)
Catastrophic forgetting remains a critical challenge in continual learning for large language models (LLMs), where models struggle to retain performance on historical tasks when fine-tuning on new sequential data without access to past datasets. In this paper, we first reveal that the drift of functional directions during the fine-tuning process is a key reason why existing regularization-based methods fail in long-term LLM continual learning. To address this, we propose Dynamic Orthogonal Continual (DOC) fine-tuning, a novel approach that tracks the drift of these functional directions and dynamically updates them during the fine-tuning process. Furthermore, by adjusting the gradients of new task parameters to be orthogonal to the tracked historical function directions, our method mitigates interference between new and old tasks. Extensive experiments on various LLM continual learning benchmarks demonstrate that this approach outperforms prior methods, effectively reducing catastrophic forgetting and providing a robust tool for continuous LLM fine-tuning. Our code is available at https://github.com/meloxxxxxx/DOC.