Efficient Multi-turn RL for GUI Agents via Decoupled Training and Adaptive Data Curation
作者: Pengxiang Li, Zechen Hu, Zirui Shang, Jingrong Wu, Yang Liu, Hui Liu, Zhi Gao, Chenrui Shi, Bofei Zhang, Zihao Zhang, Xiaochuan Shi, Zedong YU, Yuwei Wu, Xinxiao Wu, Yunde Jia, Liuyu Xiang, Zhaofeng He, Qing Li
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-09-28
💡 一句话要点
DART:解耦训练与自适应数据管理,提升GUI智能体多轮强化学习效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: GUI智能体 强化学习 解耦训练 自适应数据管理 视觉-语言模型 异步训练 任务自动化
📋 核心要点
- 现有基于VLM的GUI智能体在强化学习中面临交互速度慢和高质量数据不足的挑战,限制了其在复杂任务中的应用。
- DART框架通过解耦训练系统为四个异步模块,实现了高效的非阻塞通信和异步训练,显著提升了系统资源利用率。
- 自适应数据管理方案通过预收集成功轨迹、动态调整rollout参数和选择性训练等策略,有效提升了学习效率和任务成功率。
📝 摘要(中文)
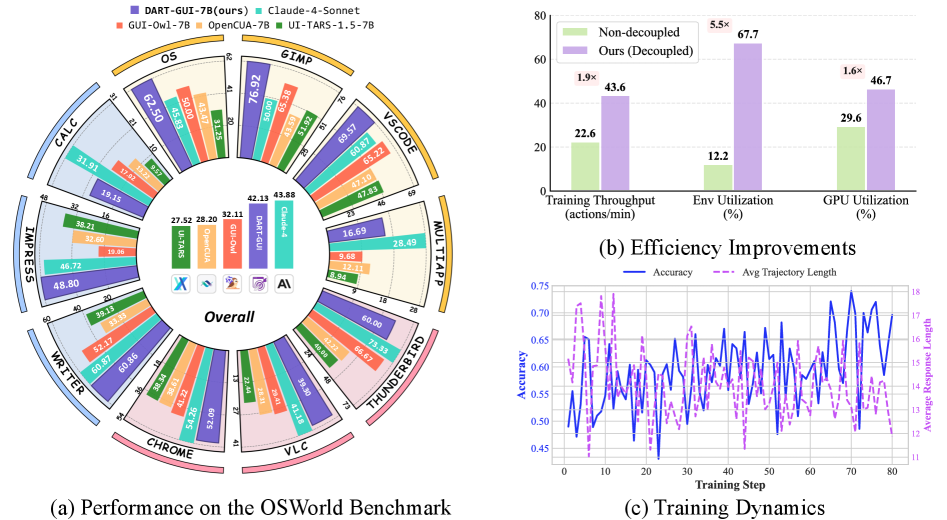
基于视觉-语言模型(VLM)的GUI智能体在自动化复杂的桌面和移动任务方面展现出潜力,但在应用强化学习(RL)时面临重大挑战:(1)与GUI环境进行策略rollout的多轮交互速度慢,(2)用于策略学习的高质量智能体-环境交互不足。为了解决这些挑战,我们提出了DART,一个用于GUI智能体的解耦Agentic RL训练框架,它以高度解耦的方式协调异构模块。DART将训练系统分离为四个异步模块:环境集群、rollout服务、数据管理器和训练器。这种设计实现了非阻塞通信、异步训练、rollout-wise轨迹采样和per-worker模型同步,显著提高了系统效率:rollout的GPU利用率提高1.6倍,训练吞吐量提高1.9倍,环境利用率提高5.5倍。为了促进从丰富样本中进行有效学习,我们引入了一种自适应数据管理方案:(1)预先收集具有挑战性任务的成功轨迹,以补充在线采样的稀疏成功;(2)基于任务难度动态调整rollout数量和轨迹长度;(3)选择性地训练高熵步骤,以优先考虑关键决策;(4)通过截断重要性采样来稳定学习,以解决策略rollout和更新之间的策略不匹配。在OSWorld基准测试中,DART-GUI-7B实现了42.13%的任务成功率,比基础模型绝对提升14.61%,比开源SOTA高7.34%。我们将通过computer-use-agents.github.io/dart-gui完全开源我们的训练框架、数据和模型检查点,我们相信这是对agentic RL训练开源社区的及时贡献。
🔬 方法详解
问题定义:论文旨在解决基于视觉-语言模型的GUI智能体在强化学习训练中效率低下的问题。现有方法在与GUI环境交互进行策略rollout时速度慢,且难以获得足够的高质量智能体-环境交互数据,导致策略学习效果不佳。
核心思路:论文的核心思路是将强化学习训练过程解耦为多个异步模块,并引入自适应数据管理方案。通过解耦,可以充分利用计算资源,提高训练效率;通过自适应数据管理,可以更有效地利用数据,提升学习效果。
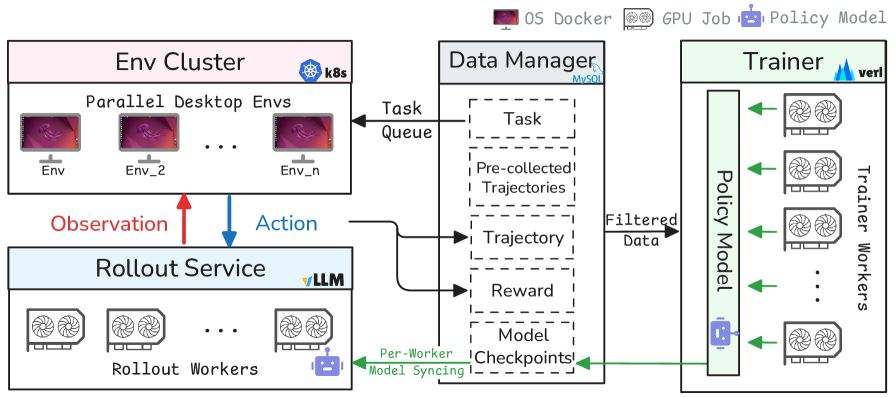
技术框架:DART框架包含四个主要模块:环境集群、rollout服务、数据管理器和训练器。环境集群负责提供GUI环境进行交互;rollout服务负责执行策略rollout,生成轨迹数据;数据管理器负责存储、筛选和管理轨迹数据;训练器负责使用轨迹数据训练策略模型。这些模块之间采用异步通信方式,互不阻塞,从而提高整体效率。
关键创新:DART的关键创新在于其解耦的训练框架和自适应数据管理方案。解耦框架允许各个模块独立运行和扩展,提高了系统灵活性和可扩展性。自适应数据管理方案能够根据任务难度和策略学习情况动态调整数据采样和训练策略,从而更有效地利用数据。
关键设计:自适应数据管理方案包含以下关键设计:(1)预收集成功轨迹,用于补充在线采样中的稀疏成功样本;(2)动态调整rollout数量和轨迹长度,以适应不同难度的任务;(3)选择性地训练高熵步骤,以优先考虑关键决策;(4)使用截断重要性采样,以稳定学习过程,缓解策略rollout和更新之间的策略不匹配问题。具体参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
DART框架在OSWorld基准测试中取得了显著成果。DART-GUI-7B模型实现了42.13%的任务成功率,相比基础模型提升了14.61%,并且比开源SOTA模型高7.34%。此外,DART框架还显著提高了系统效率,rollout的GPU利用率提高1.6倍,训练吞吐量提高1.9倍,环境利用率提高5.5倍。
🎯 应用场景
该研究成果可广泛应用于自动化桌面和移动应用任务,例如自动执行软件安装、数据录入、网页浏览等。通过提高GUI智能体的训练效率和任务成功率,可以降低人工成本,提升工作效率,并为用户提供更智能、便捷的自动化服务。未来,该技术有望应用于更复杂的交互式任务,例如智能客服、自动化测试等。
📄 摘要(原文)
Vision-language model (VLM) based GUI agents show promise for automating complex desktop and mobile tasks, but face significant challenges in applying reinforcement learning (RL): (1) slow multi-turn interactions with GUI environments for policy rollout, and (2) insufficient high-quality agent-environment interactions for policy learning. To address these challenges, we propose DART, a Decoupled Agentic RL Training framework for GUI agents, which coordinates heterogeneous modules in a highly decoupled manner. DART separates the training system into four asynchronous modules: environment cluster, rollout service, data manager, and trainer. This design enables non-blocking communication, asynchronous training, rollout-wise trajectory sampling, and per-worker model synchronization, significantly improving the system efficiency: 1.6GPU utilization for rollout, 1.9 training throughput, and 5.5* environment utilization. To facilitate effective learning from abundant samples, we introduce an adaptive data curation scheme: (1) pre-collecting successful trajectories for challenging tasks to supplement sparse success in online sampling; (2) dynamically adjusting rollout numbers and trajectory lengths based on task difficulty; (3) training selectively on high-entropy steps to prioritize critical decisions; (4) stabilizing learning via truncated importance sampling for policy mismatch between policy rollout and updating. On the OSWorld benchmark, DART-GUI-7B achieves a 42.13% task success rate, a 14.61% absolute gain over the base model, and 7.34% higher than open-source SOTA. We will fully open-source our training framework, data, and model checkpoints via computer-use-agents.github.io/dart-gui, which we believe is a timely contribution to the open-source community of agentic RL training.