Tequila: Trapping-free Ternary Quantization for Large Language Models
作者: Hong Huang, Decheng Wu, Rui Cen, Guanghua Yu, Zonghang Li, Kai Liu, Jianchen Zhu, Peng Chen, Xue Liu, Dapeng Wu
分类: cs.LG, cs.AI
发布日期: 2025-09-28 (更新: 2025-10-17)
🔗 代码/项目: GITHUB
💡 一句话要点
Tequila:一种无死区陷阱的三元量化方法,用于加速大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 三元量化 模型压缩 边缘计算 死区陷阱 动态偏差 量化感知训练
📋 核心要点
- 现有大语言模型量化方法依赖混合精度乘法,硬件效率低,而三元量化虽硬件友好,但易造成精度显著下降。
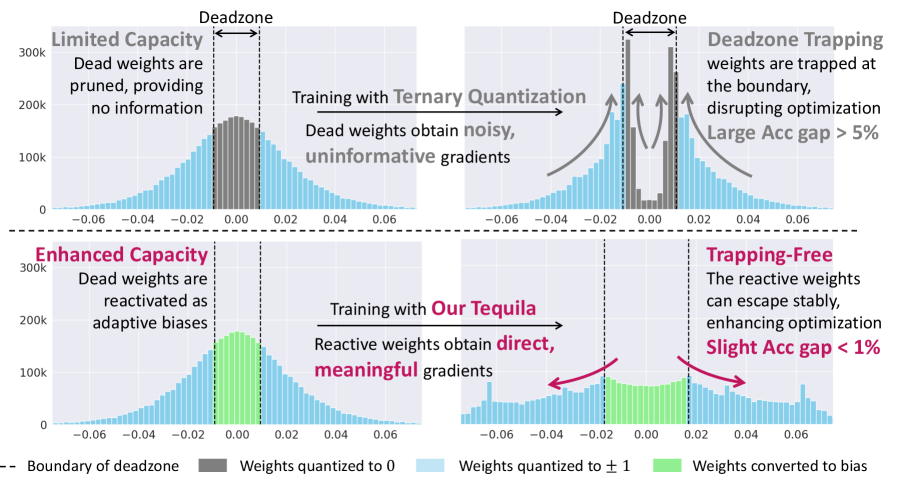
- Tequila通过将死区陷阱中的权重重新用作动态偏差,使其在正向传播中提供连续信号,反向传播中接收有意义的梯度。
- 实验表明,Tequila在多个基准测试中优于现有三元量化方法,在ARC上精度提升超过4%,推理速度提升3倍。
📝 摘要(中文)
量化技术对于在大语言模型(LLMs)在边缘设备上的部署至关重要。然而,目前的方法通常依赖于缺乏高效硬件支持的混合精度乘法,导致其可行性降低。三元权重量化通过将权重约束为{-1, 0, 1}来解决这个问题,用硬件高效的加法代替昂贵的乘法。然而,这种激进的压缩会导致显著的精度下降,即使在使用大量数据进行代价高昂的量化感知训练后也是如此。我们发现核心问题是死区陷阱:大量权重被困在死区边界。这是因为这些权重仅接收到噪声、无信息的梯度,从而阻止了它们稳定地逃离死区,并严重阻碍了模型容量和优化。为了解决这个问题,我们提出Tequila,一种无死区陷阱的量化优化方法,通过将死区陷阱中的权重重新用作动态偏差来重新激活它们。这允许重新利用的权重在正向传播中提供连续信号,并且至关重要的是,在反向传播期间接收直接、有意义的梯度信号,从而在几乎零推理开销的情况下增强模型容量和优化。广泛的评估表明,Tequila在五个基准测试中优于最先进(SOTA)的三元量化方法。具体来说,在ARC基准测试中,它比SOTA基线实现了>4%的精度提升,几乎与全精度性能相匹配(差距小于1%),同时实现了3.0倍的推理加速。因此,Tequila为在资源受限环境中部署先进的LLM提供了一种高度实用且高效的实现。代码可在https://github.com/Tencent/AngelSlim 获取。
🔬 方法详解
问题定义:论文旨在解决大语言模型三元量化过程中出现的“死区陷阱”问题。现有三元量化方法将权重限制为{-1, 0, 1},虽然降低了计算复杂度,但大量权重容易陷入0值,导致模型容量下降和精度损失。这些陷入0值的权重接收到的梯度信息不足,难以逃离“死区”,严重影响模型优化。
核心思路:Tequila的核心思路是将陷入死区的权重重新利用为动态偏差。通过将这些权重转化为动态偏差,使其在正向传播中能够提供连续的信号,从而避免信息损失。更重要的是,这些重新利用的权重在反向传播过程中能够接收到直接且有意义的梯度信号,从而有效解决死区陷阱问题,提升模型容量和优化能力。
技术框架:Tequila方法主要包含以下几个关键步骤:1) 权重三元量化:将模型权重量化为{-1, 0, 1}。2) 死区权重识别:识别陷入死区(即量化为0)的权重。3) 动态偏差转换:将识别出的死区权重转换为动态偏差,并将其添加到相应的层。4) 训练优化:使用标准的反向传播算法对模型进行训练,动态偏差权重接收直接梯度更新。
关键创新:Tequila的关键创新在于对死区权重的重新利用。与传统的三元量化方法直接丢弃或忽略这些权重不同,Tequila将它们转化为动态偏差,使其能够继续参与模型的计算和优化。这种方法不仅避免了信息损失,还为模型引入了额外的灵活性和表达能力。
关键设计:Tequila的关键设计包括:1) 动态偏差的计算方式:动态偏差的值由死区权重决定,可以采用简单的线性变换或其他更复杂的非线性变换。2) 动态偏差的添加位置:动态偏差可以添加到激活函数之前或之后,具体位置的选择需要根据实际情况进行调整。3) 训练过程中的梯度更新:为了保证动态偏差能够有效地学习,需要对其进行特殊的梯度更新策略,例如使用更大的学习率或添加动量项。
🖼️ 关键图片


📊 实验亮点
Tequila在多个基准测试中表现出色,尤其是在ARC基准测试中,相比于最先进的三元量化方法,精度提升超过4%,并且几乎达到了全精度模型的性能水平(差距小于1%)。同时,Tequila实现了3.0倍的推理速度提升,证明了其在实际应用中的高效性。这些结果表明Tequila是一种极具竞争力的三元量化方法。
🎯 应用场景
Tequila适用于资源受限的边缘设备上部署大语言模型,例如移动设备、嵌入式系统等。通过三元量化降低模型大小和计算复杂度,同时利用Tequila方法避免精度损失,使得这些设备能够运行复杂的AI应用,例如智能助手、机器翻译、图像识别等。该技术还有助于降低云计算成本,提高AI服务的普及率。
📄 摘要(原文)
Quantization techniques are essential for the deployment of Large Language Models (LLMs) on edge devices. However, prevailing methods often rely on mixed-precision multiplication that lacks efficient hardware support, making it not feasible. Ternary weight quantization addresses this by constraining weights to {-1, 0, 1}, replacing expensive multiplications with hardware-efficient additions. However, such aggressive compression leads to significant accuracy degradation, even after costly quantization-aware training with massive data. We identify the core issue as deadzone trapping: a large number of weights are trapped at the deadzone boundary. This occurs because these weights receive only noisy, uninformative gradients, preventing stable escape from the deadzone and severely impeding model capacity and optimization. To address this issue, we propose Tequila, a trapping-free quantization optimization method that reactivates deadzone-trapped weights by repurposing them as dynamic biases. This allows the repurposed weights to provide a continuous signal in the forward pass and, critically, receive direct, meaningful gradient signals during backpropagation, thereby enhancing model capacity and optimization with nearly zero inference overhead. Extensive evaluations demonstrate that Tequila outperforms state-of-the-art (SOTA) ternary quantization methods across five benchmarks. Specifically, on the ARC benchmark, it achieves >4% accuracy gain over the SOTA baseline, nearly matching full-precision performance (within <1% gap) with a 3.0x inference speedup. Consequently, Tequila offers a highly practical and efficient implementation for the deployment of advanced LLMs in resource-constrained environments. The code is available at https://github.com/Tencent/AngelSlim.