Visual CoT Makes VLMs Smarter but More Fragile
作者: Chunxue Xu, Yiwei Wang, Yujun Cai, Bryan Hooi, Songze Li
分类: cs.LG, cs.CR
发布日期: 2025-09-28
💡 一句话要点
揭示Visual CoT的脆弱性并提出鲁棒性增强方法,提升VQA模型抗噪能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 链式思考 视觉语言模型 鲁棒性 图像噪声
📋 核心要点
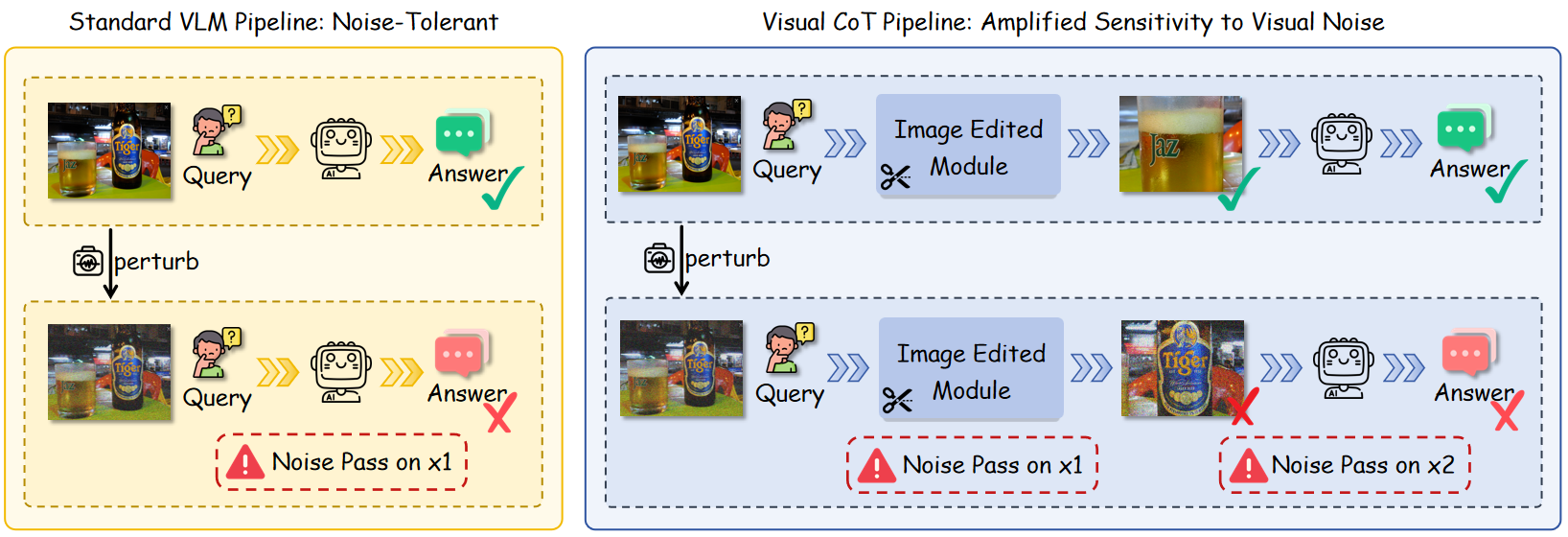
- 现有Visual CoT方法虽然提升了VLM性能,但对图像噪声的鲁棒性不足,性能下降明显。
- 通过分析Visual CoT的中间推理步骤,发现编辑后的图像块是模型脆弱性的主要来源。
- 提出一种即插即用的鲁棒性增强方法,利用Grounding DINO提供稳定的局部视觉线索。
📝 摘要(中文)
链式思考(CoT)技术显著增强了视觉语言模型(VLM)的推理能力。Visual CoT通过集成显式的视觉编辑,例如裁剪或标注感兴趣区域,到推理过程中,实现了卓越的多模态性能。然而,基于Visual CoT的VLM对图像级噪声的鲁棒性仍未被探索。本文首次对Visual CoT在视觉扰动下的鲁棒性进行了系统评估。我们的基准测试涵盖了4个视觉问答(VQA)数据集上的12种图像损坏类型,从而能够全面比较使用Visual CoT的VLM和不使用Visual CoT的VLM。结果表明,无论输入图像是干净的还是被噪声破坏的,集成Visual CoT始终可以提高绝对精度;然而,它也增加了对输入扰动的敏感性,导致与标准VLM相比,性能下降更为剧烈。通过广泛的分析,我们确定了Visual CoT的中间推理组件,即编辑过的图像块,是脆弱性的主要来源。在此分析的基础上,我们提出了一种即插即用的鲁棒性增强方法,该方法将Grounding DINO模型集成到Visual CoT流程中,提供高置信度的局部视觉线索来稳定推理。我们的工作揭示了Visual CoT中清晰的脆弱性模式,并为增强视觉鲁棒性提供了一种有效的、与架构无关的解决方案。
🔬 方法详解
问题定义:论文旨在解决Visual CoT在视觉问答任务中对图像噪声过于敏感的问题。现有的Visual CoT方法虽然提升了VLM的性能,但当输入图像受到噪声干扰时,性能会显著下降,限制了其在实际应用中的可靠性。
核心思路:论文的核心思路是识别Visual CoT中的脆弱环节,即编辑后的图像块,并引入额外的视觉信息来稳定这些环节。通过利用Grounding DINO模型提供高置信度的局部视觉线索,可以减少噪声对关键视觉区域的影响,从而提高模型的鲁棒性。
技术框架:该方法将Grounding DINO模型集成到现有的Visual CoT流程中。首先,使用Visual CoT生成编辑后的图像块。然后,利用Grounding DINO检测这些图像块中的关键对象,并提取相应的视觉特征。最后,将这些特征与原始图像和问题一起输入到VLM中进行推理,从而得到最终答案。
关键创新:该方法最重要的创新点在于识别了Visual CoT中编辑图像块的脆弱性,并提出了一种有效的、与架构无关的鲁棒性增强方案。与直接训练更鲁棒的VLM不同,该方法通过在推理过程中引入额外的视觉信息来提高模型的抗噪能力。
关键设计:Grounding DINO模型用于检测编辑图像块中的关键对象,并提取相应的视觉特征。这些特征被用来增强VLM的输入,从而提高模型对噪声的鲁棒性。具体来说,Grounding DINO的输出被用作VLM的注意力机制的先验信息,引导模型关注更可靠的视觉区域。
🖼️ 关键图片


📊 实验亮点
实验结果表明,集成了Grounding DINO的Visual CoT方法在各种图像损坏类型下均能显著提高VQA模型的鲁棒性,同时保持甚至提升了在干净图像上的性能。该方法在多个VQA数据集上都取得了显著的性能提升,证明了其有效性和通用性。
🎯 应用场景
该研究成果可应用于各种需要处理带噪声图像的视觉问答场景,例如自动驾驶、医学图像分析、遥感图像处理等。通过提高VLM对噪声的鲁棒性,可以使其在更复杂的现实环境中可靠地工作,具有重要的实际应用价值和广泛的应用前景。
📄 摘要(原文)
Chain-of-Thought (CoT) techniques have significantly enhanced reasoning in Vision-Language Models (VLMs). Extending this paradigm, Visual CoT integrates explicit visual edits, such as cropping or annotating regions of interest, into the reasoning process, achieving superior multimodal performance. However, the robustness of Visual CoT-based VLMs against image-level noise remains unexplored. In this paper, we present the first systematic evaluation of Visual CoT robustness under visual perturbations. Our benchmark spans 12 image corruption types across 4 Visual Question Answering (VQA) datasets, enabling a comprehensive comparison between VLMs that use Visual CoT, and VLMs that do not. The results reveal that integrating Visual CoT consistently improves absolute accuracy regardless of whether the input images are clean or corrupted by noise; however, it also increases sensitivity to input perturbations, resulting in sharper performance degradation compared to standard VLMs. Through extensive analysis, we identify the intermediate reasoning components of Visual CoT, i.e., the edited image patches , as the primary source of fragility. Building on this analysis, we propose a plug-and-play robustness enhancement method that integrates Grounding DINO model into the Visual CoT pipeline, providing high-confidence local visual cues to stabilize reasoning. Our work reveals clear fragility patterns in Visual CoT and offers an effective, architecture-agnostic solution for enhancing visual robustness.