Knowledge Homophily in Large Language Models
作者: Utkarsh Sahu, Zhisheng Qi, Mahantesh Halappanavar, Nedim Lipka, Ryan A. Rossi, Franck Dernoncourt, Yu Zhang, Yao Ma, Yu Wang
分类: cs.LG, cs.AI, cs.CL, cs.SI
发布日期: 2025-09-28 (更新: 2026-01-15)
💡 一句话要点
探索大语言模型中的知识同质性,并提出基于图神经网络的知识评估方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识图谱 知识同质性 图神经网络 主动学习
📋 核心要点
- 现有方法缺乏对LLM内部知识结构组织的探索,阻碍了知识注入和推理问答等应用。
- 论文核心思想是发现LLM中存在知识同质性,即相邻实体具有相似的知识掌握程度。
- 通过GNN模型预测实体知识性,提升主动标注效率和多跳推理问答性能。
📝 摘要(中文)
本文研究了大语言模型(LLMs)中知识的结构组织,受到认知神经科学中语义聚类和启动效应的启发,探索了LLMs中类似的知识同质性模式。通过知识检查将LLM知识映射到图表示中,并在三元组和实体层面进行分析,发现LLMs倾向于拥有关于图中位置更近的实体的相似知识水平。基于这种同质性原则,提出了一个图神经网络(GNN)回归模型,通过利用邻域分数来估计三元组的实体级知识性得分。预测的知识性使我们能够优先检查不太知名的三元组,从而在相同的标注预算下最大化知识覆盖率。这不仅提高了微调LLMs以注入知识的主动标注效率,而且增强了推理密集型问答中的多跳路径检索。
🔬 方法详解
问题定义:论文旨在解决如何评估大语言模型(LLM)中不同知识点的掌握程度,以及如何利用这些信息来更有效地注入知识和提升推理能力的问题。现有方法缺乏对LLM内部知识结构的理解,无法区分LLM擅长和不擅长的知识,导致知识注入效率低下,推理过程也难以选择合适的知识路径。
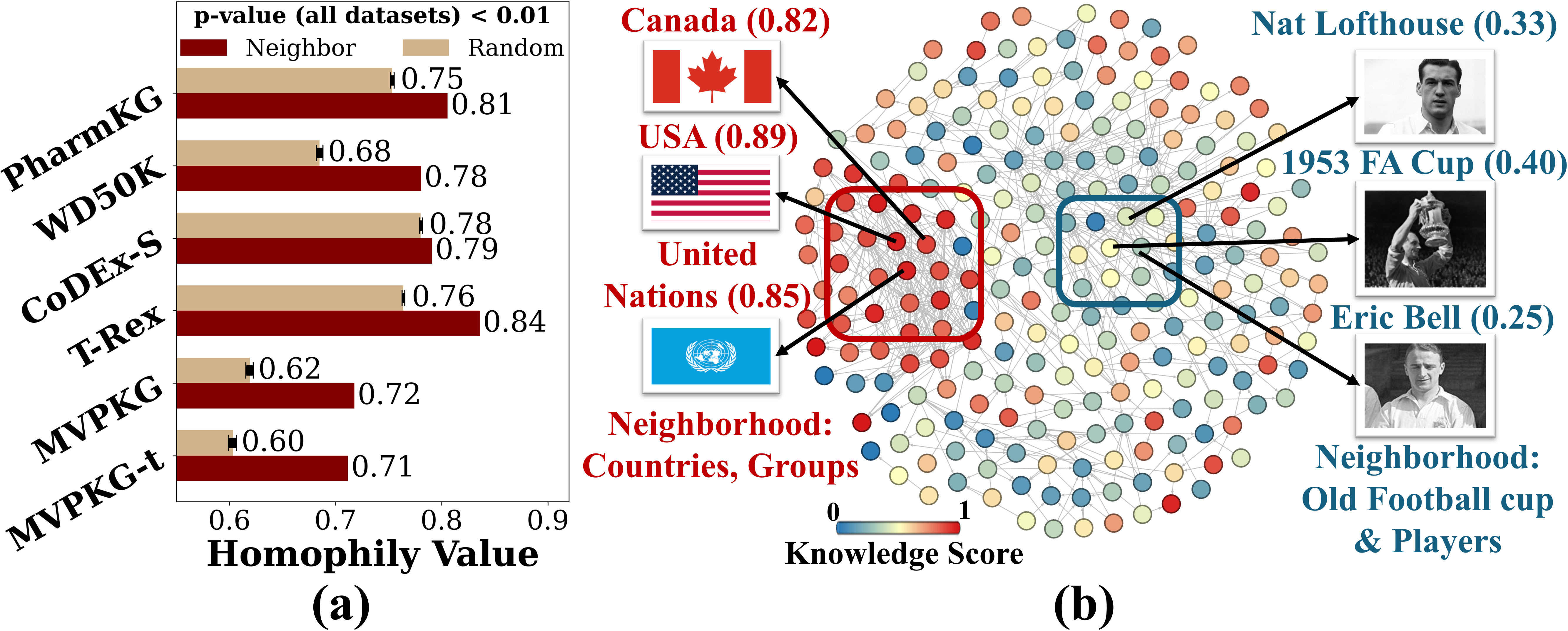
核心思路:论文的核心思路是受到认知神经科学中知识组织方式的启发,认为LLM内部的知识也存在“同质性”,即在知识图谱中相邻的实体,LLM对它们的掌握程度也应该相似。因此,可以通过分析LLM对已知实体的掌握程度,来预测其对未知实体的掌握程度。
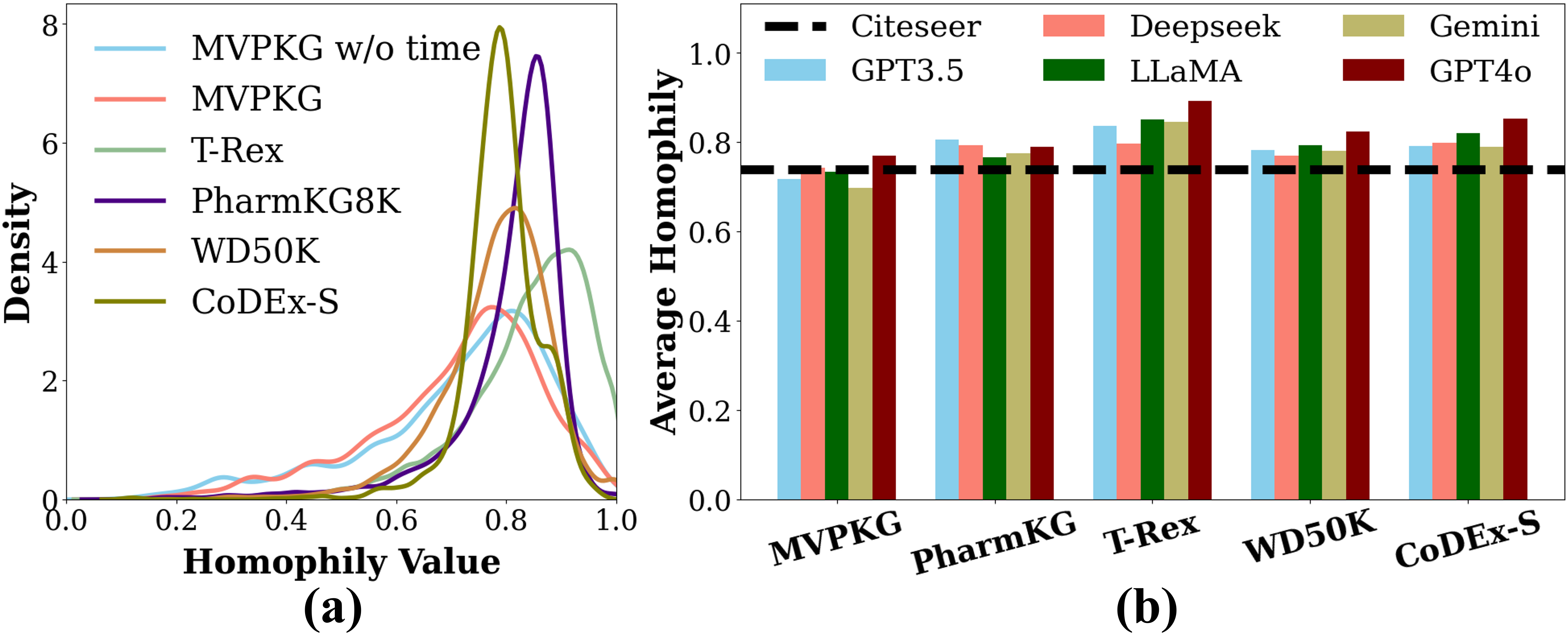
技术框架:论文的技术框架主要包括以下几个步骤:1) 知识图谱构建:将LLM的知识表示为图结构,节点代表实体,边代表实体之间的关系。2) 知识检查:通过提问的方式,评估LLM对每个实体或三元组的掌握程度,得到知识性得分。3) 知识同质性分析:分析图中相邻实体之间的知识性得分的相关性,验证知识同质性假设。4) GNN模型构建:构建一个图神经网络(GNN)回归模型,利用邻域实体的知识性得分来预测目标实体的知识性得分。
关键创新:论文最重要的创新点在于发现了LLM中存在的知识同质性现象,并将其应用于知识评估和知识注入。与现有方法相比,该方法不再孤立地评估每个知识点,而是考虑了知识点之间的关联性,从而更准确地评估LLM的知识掌握程度。
关键设计:GNN模型的设计是关键。具体来说,论文使用图卷积网络(GCN)作为GNN的基本单元,通过多层GCN来聚合邻域信息。损失函数采用均方误差(MSE),用于衡量预测的知识性得分与实际知识性得分之间的差距。此外,论文还设计了一种主动学习策略,优先选择知识性得分较低的实体进行标注,以提高知识注入的效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于GNN的知识性预测方法能够有效地预测LLM对实体的知识掌握程度。通过主动学习策略,可以在相同的标注预算下,显著提高LLM的知识覆盖率。此外,在多跳推理问答任务中,利用预测的知识性得分选择知识路径,可以提高答案的准确率。
🎯 应用场景
该研究成果可应用于提升大语言模型的知识水平和推理能力。例如,在知识图谱问答中,可以利用预测的知识性得分来选择更可靠的知识路径,提高答案的准确性。在知识注入方面,可以指导主动学习过程,优先标注LLM不擅长的知识,提高知识覆盖率。此外,该方法还可以用于评估不同LLM的知识差异,为模型选择和组合提供依据。
📄 摘要(原文)
Large Language Models (LLMs) have been increasingly studied as neural knowledge bases for supporting knowledge-intensive applications such as question answering and fact checking. However, the structural organization of their knowledge remains unexplored. Inspired by cognitive neuroscience findings, such as semantic clustering and priming, where knowing one fact increases the likelihood of recalling related facts, we investigate an analogous knowledge homophily pattern in LLMs. To this end, we map LLM knowledge into a graph representation through knowledge checking at both the triplet and entity levels. After that, we analyze the knowledgeability relationship between an entity and its neighbors, discovering that LLMs tend to possess a similar level of knowledge about entities positioned closer in the graph. Motivated by this homophily principle, we propose a Graph Neural Network (GNN) regression model to estimate entity-level knowledgeability scores for triplets by leveraging their neighborhood scores. The predicted knowledgeability enables us to prioritize checking less well-known triplets, thereby maximizing knowledge coverage under the same labeling budget. This not only improves the efficiency of active labeling for fine-tuning to inject knowledge into LLMs but also enhances multi-hop path retrieval in reasoning-intensive question answering.