Towards a Comprehensive Scaling Law of Mixture-of-Experts
作者: Guoliang Zhao, Yuhan Fu, Shuaipeng Li, Xingwu Sun, Ruobing Xie, An Wang, Weidong Han, Zhen Yang, Weixuan Sun, Yudong Zhang, Cheng-zhong Xu, Di Wang, Jie Jiang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-09-28
💡 一句话要点
针对MoE模型,提出综合性扩展法则,指导模型设计与训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 扩展法则 大语言模型 模型设计 参数效率 稀疏激活 模型缩放
📋 核心要点
- 现有稠密模型扩展法则无法直接应用于MoE模型,面临影响因素复杂、耦合关系复杂和性能影响非单调等挑战。
- 通过系统分解MoE设置,识别数据大小、模型大小、激活模型大小等五个关键因素,构建综合性MoE扩展法则。
- 实验结果表明,激活专家数量和共享专家比例的最优设置与模型架构和数据大小无关,激活参数比率随模型扩展变得稀疏。
📝 摘要(中文)
混合专家模型(MoE)已成为大语言模型中实现参数高效扩展和经济高效部署的共识方法。然而,现有的稠密模型扩展法则不适用于MoE模型,这源于三个关键挑战:影响因素的多重性、它们之间复杂的耦合关系以及其性能影响的非单调性。它们共同需要对MoE特定的扩展法则进行细粒度的研究。在这项工作中,我们对MoE设置进行了系统的分解,从大小和结构的角度确定了影响模型性能的五个关键因素(数据大小($D$)、总模型大小($N$)、激活模型大小($N_a$)、激活专家数量($G$)和共享专家比例($S$))。具体来说,我们设计了446个受控实验来表征它们的边际效应,最终构建了一个考虑所有必要因素的全面而精确的联合MoE扩展法则。此外,我们通过详细的分析推导出了$G$、$S$和$N_a/N$的理论最优和实际效率感知最优配置。我们的结果表明,$G$和$S$的最优设置与模型架构和数据大小无关。随着$N$的扩展,$N_a/N$的最佳激活参数比率变得更加稀疏。我们提出的MoE扩展法则可以作为一个准确而有见地的指导,以促进未来的MoE模型设计和训练。
🔬 方法详解
问题定义:现有稠密模型的扩展法则无法直接应用于混合专家模型(MoE),因为MoE模型的性能受到多个因素(数据量、模型大小、激活专家数量等)的复杂交互影响,且这些因素对性能的影响并非简单的线性关系。因此,需要针对MoE模型设计专门的扩展法则,以指导模型设计和训练。
核心思路:通过系统地分解MoE模型的各个组成部分,识别出影响模型性能的关键因素,并通过大量的受控实验来量化这些因素之间的关系。最终,将这些关系整合到一个综合性的扩展法则中,从而能够预测不同配置下MoE模型的性能。
技术框架:该研究主要通过实验分析来构建MoE扩展法则。具体步骤包括:1) 确定影响MoE模型性能的关键因素(数据大小D、总模型大小N、激活模型大小Na、激活专家数量G、共享专家比例S);2) 设计大量的受控实验,每次只改变一个因素,以量化该因素对模型性能的影响;3) 利用实验数据,建立一个数学模型来描述这些因素之间的关系,即MoE扩展法则;4) 基于该扩展法则,推导出G、S和Na/N的理论最优和实际效率感知最优配置。
关键创新:该研究的关键创新在于,它首次系统地研究了MoE模型的扩展法则,并提出了一个综合性的扩展法则,考虑了多个关键因素的相互作用。此外,该研究还推导出了激活专家数量、共享专家比例和激活参数比率的最优配置,为MoE模型的设计提供了有价值的指导。
关键设计:该研究设计了446个受控实验,通过控制变量法来分析各个因素对模型性能的影响。在扩展法则的构建过程中,使用了回归分析等统计方法来拟合实验数据。此外,该研究还考虑了实际效率,推导出了效率感知最优配置,使得在有限的计算资源下也能获得较好的模型性能。
🖼️ 关键图片

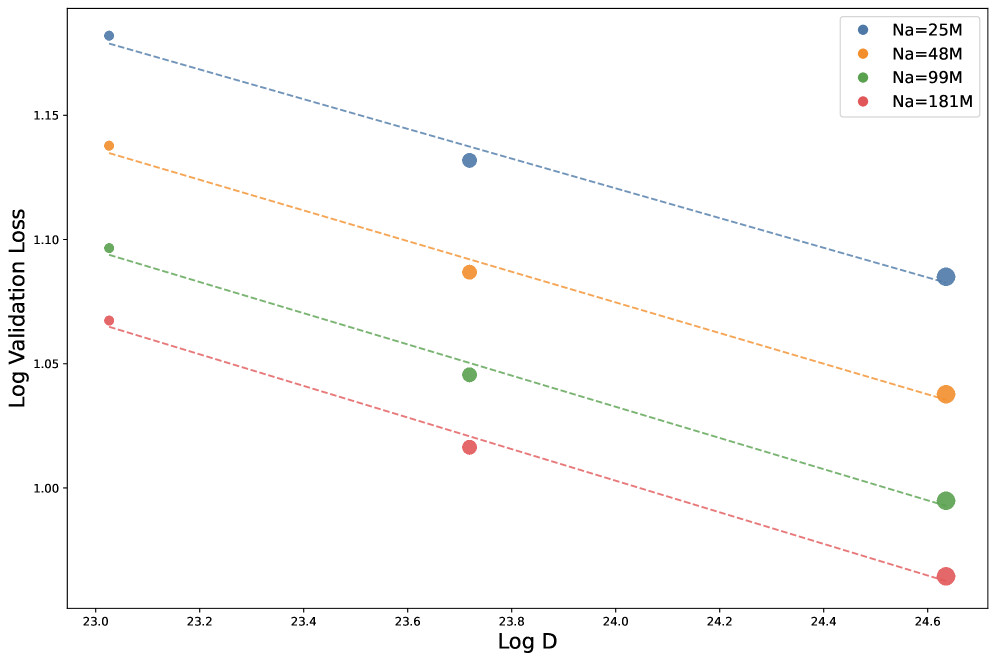

📊 实验亮点
该研究通过446个受控实验,构建了综合性的MoE扩展法则,并推导出激活专家数量($G$)和共享专家比例($S$)的最优设置与模型架构和数据大小无关。实验结果表明,随着模型规模($N$)的扩展,激活参数比率($N_a/N$)的最佳值变得更加稀疏,这为高效MoE模型设计提供了重要依据。
🎯 应用场景
该研究成果可广泛应用于大语言模型的预训练和微调,尤其是在资源受限的场景下。通过该研究提出的MoE扩展法则,可以更有效地设计和训练MoE模型,从而在相同的计算资源下获得更好的模型性能。此外,该研究还可以为未来的MoE模型架构设计提供指导。
📄 摘要(原文)
Mixture-of-Experts (MoE) models have become the consensus approach for enabling parameter-efficient scaling and cost-effective deployment in large language models. However, existing scaling laws for dense models are inapplicable to MoE models, which stems from three critical challenges: the multiplicity of influencing factors, their intricate coupling relationships and the non-monotonic nature of their performance impacts. They collectively necessitate a fine-grained investigation into MoE-specific scaling laws. In this work, we perform a systematic decomposition of MoE settings, identifying five key factors that influence model performance from both size and structural perspectives (data size ($D$), total model size ($N$), activated model size ($N_a$), number of active experts ($G$) and the ratio of shared experts ($S$)). Specifically, we design $446$ controlled experiments to characterize their marginal effects, ultimately constructing a comprehensive and precise joint MoE scaling law that considers all essential factors. Furthermore, we derive the theoretically optimal and practically efficiency-aware optimal configurations for $G$, $S$ and $N_a/N$ with detailed analyses. Our results demonstrate that the optimal settings for $G$ and $S$ are independent of both the model architecture and data size. With the scaling of $N$, the optimal activation parameter ratio of $N_a/N$ becomes sparser. Our proposed MoE scaling law could function as an accurate and insightful guidance to facilitate future MoE model design and training.