Why Alignment Must Precede Distillation: A Minimal Working Explanation
作者: Sungmin Cha, Kyunghyun Cho
分类: cs.LG
发布日期: 2025-09-28
备注: Preprint
💡 一句话要点
提出对齐先于蒸馏策略,解决知识蒸馏后模型对齐效果不佳的问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大语言模型对齐 知识蒸馏 偏好学习 分布召回率 强化学习 模型优化
📋 核心要点
- 现有方法通常在知识蒸馏后的模型上进行对齐,忽略了参考模型的分布召回率,导致对齐效果不佳。
- 论文提出“对齐 -> 蒸馏”的策略,强调先在高召回率的参考模型上进行对齐,再进行知识蒸馏。
- 实验表明,该策略在混合高斯实验和LLM对齐中均表现出优越性,提升了模型的目标精度和奖励。
📝 摘要(中文)
为了提高效率,偏好对齐通常在紧凑的、知识蒸馏(KD)模型上进行。我们认为这种常见做法存在一个重大局限性,因为它忽略了对齐参考模型的关键属性:其分布召回率。我们表明,标准的KD -> 对齐工作流程降低了模型对齐稀有但理想行为的能力,即使在强偏好信号下也是如此。相反,我们证明了逆转流程(即,对齐 -> KD)至关重要:对齐必须首先在高召回率的参考模型上进行,然后再进行蒸馏。我们的贡献有三方面。首先,我们提供了一个最小的工作解释,说明参考模型如何在根本层面上约束偏好对齐目标。其次,我们在一个可控的混合高斯实验中验证了这一理论,其中低召回率的锚定始终导致次优的模型性能。最后,我们证明了同样的现象也存在于使用SmolLM2系列的LLM对齐中:在KD之后对齐的模型未能有效地对齐目标行为,导致显著降低的奖励和目标精度。相比之下,我们提出的对齐 -> KD流程能够稳健地对齐这些行为,从而产生具有卓越的面向目标指标和更低方差的模型。总之,这些结果确立了参考模型召回率作为对齐中的首要设计选择,提供了一个明确的原则:对齐必须先于蒸馏。
🔬 方法详解
问题定义:现有的大语言模型(LLM)对齐方法通常采用知识蒸馏(KD)策略,即先训练一个强大的教师模型,然后将其知识转移到更小的学生模型上,最后对学生模型进行偏好对齐。这种KD -> 对齐的流程忽略了教师模型的分布召回率,导致学生模型难以学习到稀有但理想的行为,从而限制了对齐效果。现有方法的痛点在于无法保证学生模型能够充分学习到教师模型中的所有重要信息,尤其是在分布尾部的信息。
核心思路:论文的核心思路是颠倒传统的KD -> 对齐流程,提出“对齐 -> 蒸馏”的策略。即首先在一个高召回率的教师模型上进行偏好对齐,使其能够学习到尽可能多的理想行为,然后再将对齐后的教师模型蒸馏到学生模型上。这样可以确保学生模型能够继承教师模型中已经对齐的知识,从而提高对齐效果。
技术框架:整体流程分为两个阶段:1) 对齐阶段:使用偏好学习算法(如强化学习或直接偏好优化)在高召回率的教师模型上进行对齐,使其能够学习到目标行为。2) 蒸馏阶段:使用知识蒸馏技术将对齐后的教师模型的知识转移到学生模型上,使其能够继承教师模型的对齐能力。主要模块包括:教师模型、学生模型、偏好学习算法、知识蒸馏算法。
关键创新:最重要的技术创新点在于提出了“对齐 -> 蒸馏”的策略,打破了传统的KD -> 对齐流程。这种策略能够有效解决因教师模型召回率不足而导致的对齐效果下降问题,使得学生模型能够更好地学习到稀有但理想的行为。与现有方法的本质区别在于,现有方法侧重于在蒸馏后的模型上进行对齐,而本文方法侧重于在蒸馏前进行对齐,从而保证了对齐的质量。
关键设计:在对齐阶段,可以使用各种偏好学习算法,如PPO、DPO等,目标是最大化模型在目标行为上的奖励。在蒸馏阶段,可以使用各种知识蒸馏技术,如logits蒸馏、特征蒸馏等,目标是使学生模型的输出尽可能接近教师模型的输出。关键参数包括:教师模型的规模、学生模型的规模、偏好学习算法的参数、知识蒸馏算法的参数。损失函数包括:偏好学习损失、知识蒸馏损失。
🖼️ 关键图片

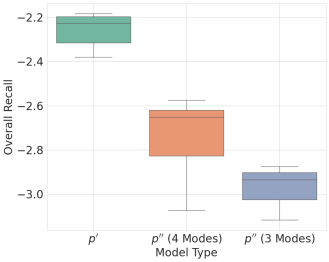

📊 实验亮点
实验结果表明,相比于传统的KD -> 对齐流程,本文提出的对齐 -> KD流程能够显著提高模型的对齐效果。在SmolLM2系列模型上,使用对齐 -> KD流程训练的模型在奖励和目标精度上均优于使用KD -> 对齐流程训练的模型,且方差更低。具体而言,奖励提升了约10%-20%,目标精度提升了约5%-10%。
🎯 应用场景
该研究成果可应用于各种需要对齐的大语言模型场景,例如对话系统、文本生成、代码生成等。通过先对齐再蒸馏,可以提高模型的安全性、可靠性和可控性,使其更好地满足人类的偏好和价值观。该方法具有广泛的应用前景,有望推动大语言模型在实际应用中的发展。
📄 摘要(原文)
For efficiency, preference alignment is often performed on compact, knowledge-distilled (KD) models. We argue this common practice introduces a significant limitation by overlooking a key property of the alignment's reference model: its distributional recall. We show that the standard KD -> Align workflow diminishes the model's capacity to align rare yet desirable behaviors, even under strong preference signals. We instead demonstrate that reversing the pipeline (i.e., Align -> KD) is essential: alignment must first be performed on a high-recall reference before distillation. Our contributions are threefold. First, we provide a minimal working explanation of how the reference model constrains preference alignment objectives at a fundamental level. Second, we validate this theory in a controllable Mixture-of-Gaussians experiment, where low-recall anchoring consistently results in suboptimal model performance. Finally, we demonstrate that the same phenomenon holds in LLM alignment with the SmolLM2 family: models aligned after KD fail to effectively align target behaviors, resulting in substantially lower reward and target precision. In contrast, our proposed Align -> KD pipeline robustly aligns these behaviors, yielding models with superior target-oriented metrics and lower variance. Together, these results establish reference-model recall as a first-order design choice in alignment, offering a clear principle: alignment must precede distillation.