Improving constraint-based discovery with robust propagation and reliable LLM priors
作者: Ruiqi Lyu, Alistair Turcan, Martin Jinye Zhang, Bryan Wilder
分类: cs.LG
发布日期: 2025-09-28
💡 一句话要点
MosaCD:结合鲁棒传播与可靠LLM先验改进基于约束的因果发现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 因果发现 条件独立性测试 大型语言模型 因果图 边缘方向传播
📋 核心要点
- 传统基于约束的因果发现方法易受CI测试误差和搜索不完备的影响,导致级联错误。
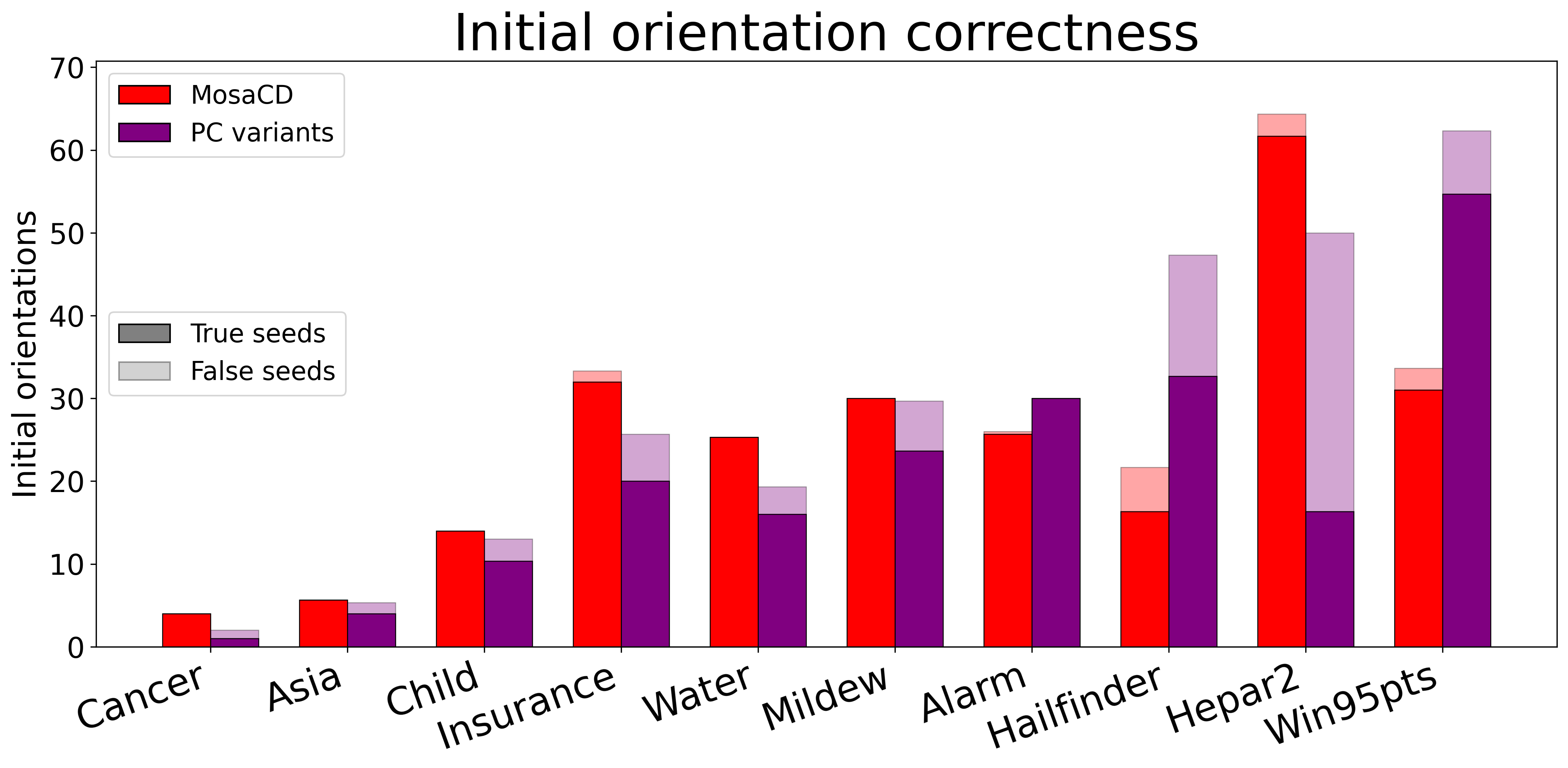
- MosaCD利用CI测试和LLM先验构建高置信度种子集,并采用置信度降序传播策略,提高边缘方向确定的可靠性。
- 实验表明,MosaCD在真实世界图上优于现有方法,这归功于其更可靠的初始种子和鲁棒的传播策略。
📝 摘要(中文)
从观测数据中学习因果结构是科学建模和决策制定的核心。基于约束的方法旨在恢复因果有向无环图(DAG)中的条件独立(CI)关系。传统的PC算法及其后续方法首先确定v结构,然后从这些种子传播边缘方向,但它们假设完美的CI测试和分离子集的穷举搜索。这些假设在实践中经常被违反,导致最终图中的级联错误。最近的研究探索了使用大型语言模型(LLM)作为专家,提示节点集以确定边缘方向,这可以在假设不满足时增强边缘方向的确定。然而,这些方法隐含地假设了完美的专家,这对于容易产生幻觉的LLM来说是不现实的。我们提出了MosaCD,一种因果发现方法,它从CI测试和LLM注释中获得的高置信度种子集中传播边缘。为了过滤幻觉,我们引入了利用LLM位置偏差的洗牌查询,仅保留高置信度种子。然后,我们应用一种新颖的置信度降序传播策略,该策略首先确定最可靠的边缘方向,并且可以与任何基于骨架的发现方法集成。在多个真实世界的图上,MosaCD在最终图构建中实现了比现有基于约束的方法更高的准确性,这主要是由于初始种子的可靠性和鲁棒的传播策略的提高。
🔬 方法详解
问题定义:论文旨在解决基于约束的因果发现方法中,由于不完美的条件独立性(CI)测试和不完备的搜索策略导致的级联错误问题。现有方法对CI测试的准确性要求过高,并且在边缘方向传播过程中容易放大初始错误,导致最终因果图的结构不准确。此外,直接使用LLM进行因果发现时,LLM固有的幻觉问题也会引入噪声。
核心思路:MosaCD的核心思路是结合传统的CI测试和LLM的先验知识,构建一个高置信度的初始种子集,然后使用一种鲁棒的传播策略,从这些种子出发,逐步确定因果图的边缘方向。通过引入洗牌查询来过滤LLM的幻觉,并优先传播置信度高的边缘,从而减少错误传播的可能性。
技术框架:MosaCD的整体框架包含以下几个主要阶段: 1. 骨架学习:使用传统的基于约束的方法(如PC算法)学习因果图的骨架结构。 2. 种子集构建:结合CI测试的结果和LLM的预测,构建一个高置信度的初始种子集。LLM通过回答关于边缘方向的问题来提供先验知识,并使用洗牌查询来过滤幻觉。 3. 边缘方向传播:使用一种置信度降序的传播策略,从种子集中的边缘出发,逐步确定其他边缘的方向。优先传播置信度高的边缘,以减少错误传播。 4. 图完善:对最终的因果图进行完善,例如消除环路等。
关键创新:MosaCD的关键创新在于以下几点: 1. 高置信度种子集:结合CI测试和LLM先验,并通过洗牌查询过滤LLM幻觉,从而构建更可靠的初始种子集。 2. 置信度降序传播:优先传播置信度高的边缘,从而减少错误传播的可能性。 3. 与现有方法的兼容性:MosaCD可以与任何基于骨架的发现方法集成,具有良好的通用性。
关键设计: * 洗牌查询:通过对LLM的输入进行洗牌,利用LLM的位置偏差来识别和过滤幻觉。如果LLM对洗牌后的输入给出不同的答案,则认为该预测不可靠。 * 置信度评估:对CI测试和LLM预测的结果进行置信度评估,并根据置信度对边缘进行排序。 * 传播策略:设计了一种置信度降序的传播策略,优先传播置信度高的边缘,并根据已确定的边缘方向来推断其他边缘的方向。
🖼️ 关键图片
📊 实验亮点
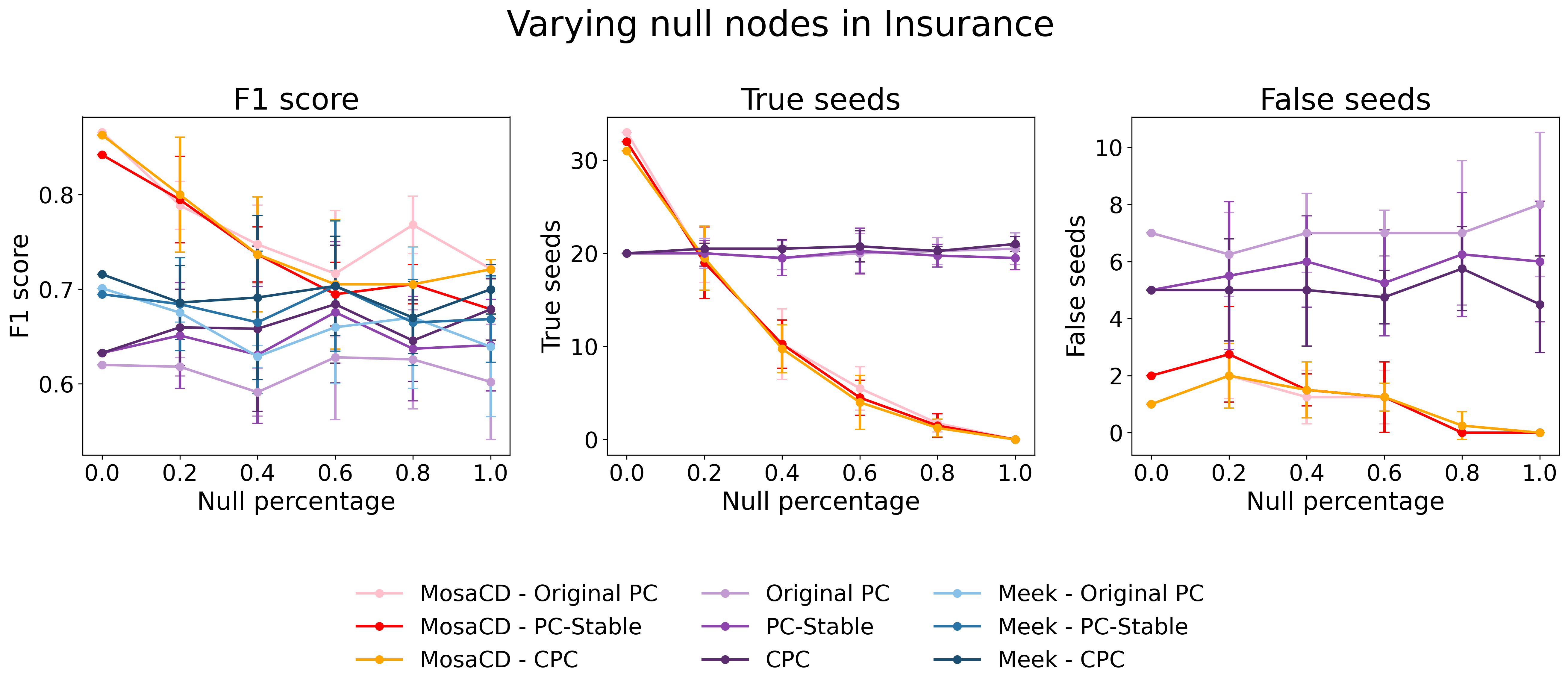
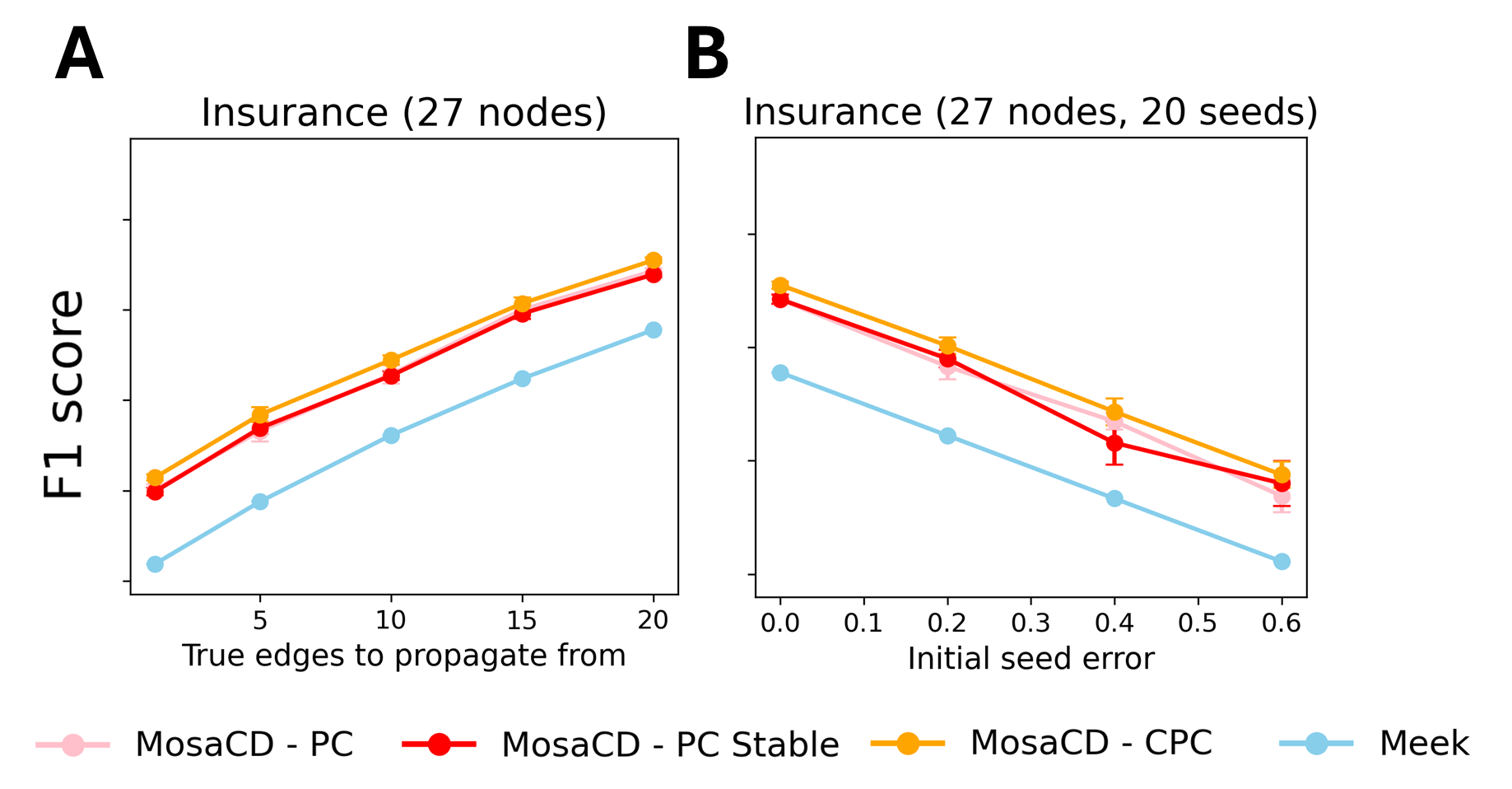
实验结果表明,MosaCD在多个真实世界图上实现了比现有基于约束的方法更高的准确性。具体来说,MosaCD在最终图构建中显著优于PC算法及其变体,以及直接使用LLM进行因果发现的方法。这主要是由于MosaCD能够构建更可靠的初始种子集,并采用鲁棒的传播策略,从而减少了错误传播的可能性。
🎯 应用场景
MosaCD可应用于多个领域,如生物医学、经济学和社会科学等,用于发现变量之间的因果关系。例如,在生物医学中,可以用于识别疾病的风险因素和治疗靶点;在经济学中,可以用于分析政策对经济的影响;在社会科学中,可以用于研究社会现象的成因。该研究有助于提高因果推断的准确性和可靠性,为决策提供更可靠的依据。
📄 摘要(原文)
Learning causal structure from observational data is central to scientific modeling and decision-making. Constraint-based methods aim to recover conditional independence (CI) relations in a causal directed acyclic graph (DAG). Classical approaches such as PC and subsequent methods orient v-structures first and then propagate edge directions from these seeds, assuming perfect CI tests and exhaustive search of separating subsets -- assumptions often violated in practice, leading to cascading errors in the final graph. Recent work has explored using large language models (LLMs) as experts, prompting sets of nodes for edge directions, and could augment edge orientation when assumptions are not met. However, such methods implicitly assume perfect experts, which is unrealistic for hallucination-prone LLMs. We propose MosaCD, a causal discovery method that propagates edges from a high-confidence set of seeds derived from both CI tests and LLM annotations. To filter hallucinations, we introduce shuffled queries that exploit LLMs' positional bias, retaining only high-confidence seeds. We then apply a novel confidence-down propagation strategy that orients the most reliable edges first, and can be integrated with any skeleton-based discovery method. Across multiple real-world graphs, MosaCD achieves higher accuracy in final graph construction than existing constraint-based methods, largely due to the improved reliability of initial seeds and robust propagation strategies.