Learning without Global Backpropagation via Synergistic Information Distillation
作者: Chenhao Ye, Ming Tang
分类: cs.LG, cs.AI
发布日期: 2025-09-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出协同信息蒸馏(SID)框架,解决深度学习反向传播的扩展性瓶颈。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 协同信息蒸馏 无反向传播学习 并行训练 深度学习 可扩展性 鲁棒性 局部目标函数
📋 核心要点
- 反向传播存在更新锁定和高内存消耗问题,限制了深度学习模型的可扩展性。
- 协同信息蒸馏(SID)将深度学习重构为局部协同细化问题的级联,实现模块间的并行训练。
- 实验结果表明,SID在分类精度上与反向传播相当甚至超越,并具有更好的可扩展性和鲁棒性。
📝 摘要(中文)
反向传播(BP)是深度学习的基础,但存在两个关键的可扩展性瓶颈:更新锁定,即网络模块在整个反向传播完成之前保持空闲;以及由于存储用于梯度计算的激活而导致的高内存消耗。为了解决这些限制,我们引入了协同信息蒸馏(SID),这是一种新颖的训练框架,它将深度学习重新定义为局部协同细化问题的级联。在SID中,深度网络被构建为模块的流水线,每个模块都被施加一个局部目标,以细化关于ground-truth目标的概率信念。该目标平衡了对目标的保真度与来自其前置模块的信念的一致性。通过解耦模块之间的反向依赖关系,SID能够实现并行训练,从而消除了更新锁定并大大降低了内存需求。同时,这种设计保留了标准的正向推理过程,使SID成为BP的多功能替代品。我们提供了理论基础,证明SID保证了网络深度带来的单调性能提升。在实验上,SID始终匹配或超过BP的分类精度,表现出卓越的可扩展性和对标签噪声的显著鲁棒性。
🔬 方法详解
问题定义:论文旨在解决深度学习中反向传播算法(BP)存在的两个主要问题:一是更新锁定,即网络中的模块必须等待整个反向传播过程完成后才能更新参数,导致训练效率低下;二是高内存消耗,因为需要存储大量的激活值用于计算梯度。这些问题限制了深度学习模型在更大规模数据集和更深层网络上的应用。
核心思路:论文的核心思路是将深度学习过程重新定义为一系列局部协同细化问题。每个网络模块不再依赖全局的反向传播信号,而是通过一个局部目标来优化自身,该目标结合了对真实标签的预测和来自前一个模块的信念。这种设计解耦了模块之间的依赖关系,使得它们可以并行训练。
技术框架:SID框架将深度网络视为一个模块的流水线。每个模块接收来自前一个模块的输入,并输出一个关于ground-truth目标的概率信念。每个模块的目标函数包含两部分:一部分是衡量模块自身预测与真实标签之间的差异(fidelity to the target),另一部分是衡量模块的预测与前一个模块的信念之间的一致性(consistency to the belief)。通过优化这个局部目标函数,每个模块逐步细化对真实标签的预测。整个网络的前向推理过程与标准的前向网络相同。
关键创新:SID的关键创新在于它打破了反向传播的全局依赖性,实现了模块间的并行训练。与传统的反向传播算法相比,SID不需要存储大量的激活值,从而显著降低了内存消耗。此外,SID通过局部目标函数的协同优化,保证了网络性能的单调提升。
关键设计:SID的关键设计包括:1) 局部目标函数的设计,需要平衡预测的准确性和模块间的一致性;2) 模块间信念传递的方式,如何有效地利用前一个模块的信息;3) 损失函数的选择,可以使用交叉熵损失等标准损失函数,并根据具体任务进行调整。论文中没有详细说明具体的网络结构,SID可以应用于各种不同的网络结构。
🖼️ 关键图片


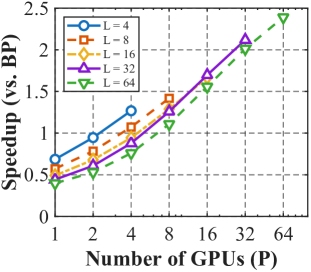
📊 实验亮点
SID在多个图像分类数据集上进行了实验,结果表明,SID在分类精度上与反向传播算法相当甚至超越。更重要的是,SID在训练过程中显著降低了内存消耗,并表现出更好的可扩展性和对标签噪声的鲁棒性。例如,在存在标签噪声的情况下,SID的性能下降幅度明显小于反向传播算法。
🎯 应用场景
SID框架具有广泛的应用前景,尤其适用于大规模数据集和深度神经网络的训练。它可以应用于图像识别、自然语言处理、语音识别等领域,并有望加速深度学习模型在资源受限设备上的部署。此外,SID的并行训练特性使其能够充分利用分布式计算资源,提高训练效率。
📄 摘要(原文)
Backpropagation (BP), while foundational to deep learning, imposes two critical scalability bottlenecks: update locking, where network modules remain idle until the entire backward pass completes, and high memory consumption due to storing activations for gradient computation. To address these limitations, we introduce Synergistic Information Distillation (SID), a novel training framework that reframes deep learning as a cascade of local cooperative refinement problems. In SID, a deep network is structured as a pipeline of modules, each imposed with a local objective to refine a probabilistic belief about the ground-truth target. This objective balances fidelity to the target with consistency to the belief from its preceding module. By decoupling the backward dependencies between modules, SID enables parallel training and hence eliminates update locking and drastically reduces memory requirements. Meanwhile, this design preserves the standard feed-forward inference pass, making SID a versatile drop-in replacement for BP. We provide a theoretical foundation, proving that SID guarantees monotonic performance improvement with network depth. Empirically, SID consistently matches or surpasses the classification accuracy of BP, exhibiting superior scalability and pronounced robustness to label noise.Code is available at: https://github.com/ychAlbert/sid-bp