PT$^2$-LLM: Post-Training Ternarization for Large Language Models
作者: Xianglong Yan, Chengzhu Bao, Zhiteng Li, Tianao Zhang, Kaicheng Yang, Haotong Qin, Ruobing Xie, Xingwu Sun, Yulun Zhang
分类: cs.LG, cs.AI
发布日期: 2025-09-27 (更新: 2026-01-30)
备注: Accepted at ICLR 2026
🔗 代码/项目: GITHUB
💡 一句话要点
PT$^2$-LLM:面向大语言模型的后训练三值化框架,实现高效压缩与加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练量化 三值化 模型压缩 模型加速
📋 核心要点
- 现有大语言模型部署受限于其巨大的内存和计算需求,后训练量化中的三值化方法面临无训练参数优化和异常值量化难题。
- PT$^2$-LLM提出非对称三值量化器,通过迭代三值拟合和激活感知网格对齐两阶段细化流程,最小化量化误差并匹配全精度输出。
- 实验表明,PT$^2$-LLM在低内存成本下,性能媲美SOTA 2-bit PTQ方法,并加速预填充和解码过程,实现端到端加速。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出令人印象深刻的能力,但其庞大的内存和计算需求阻碍了部署。三值化作为一种有前途的压缩技术,因其显著的尺寸缩减和高计算效率而备受关注。然而,由于无训练参数优化以及由异常值和分散权重带来的量化困难,其在后训练量化(PTQ)设置中的潜力仍未得到充分探索。为了解决这些问题,我们提出了PT$^2$-LLM,一个专为LLM定制的后训练三值化框架。其核心是一个非对称三值量化器,配备了一个两阶段细化流程:(1)迭代三值拟合(ITF),在最佳三值网格构建和灵活舍入之间交替,以最小化量化误差;(2)激活感知网格对齐(AGA),进一步细化三值网格,以更好地匹配全精度输出。此外,我们提出了一种即插即用的基于结构相似性的重排序(SSR)策略,该策略利用列间结构相似性来简化量化并减轻异常值的影响,从而进一步提高整体性能。大量实验表明,PT$^2$-LLM在内存成本更低的情况下,提供了与最先进的(SOTA) 2-bit PTQ方法相比具有竞争力的性能,同时加速了预填充和解码,从而实现了端到端加速。代码和模型将在https://github.com/XIANGLONGYAN/PT2-LLM上提供。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)在后训练量化(PTQ)场景下,使用三值化进行压缩时面临的挑战。现有方法在无训练的情况下难以优化参数,并且模型中存在的异常值和分散的权重分布使得量化过程更加困难,导致性能下降。
核心思路:论文的核心思路是通过设计一个非对称三值量化器,并结合两阶段的细化流程以及结构相似性重排序策略,来优化量化过程,从而在不进行训练的情况下,实现对LLM的高效三值化压缩。这种设计旨在最小化量化误差,并减轻异常值的影响。
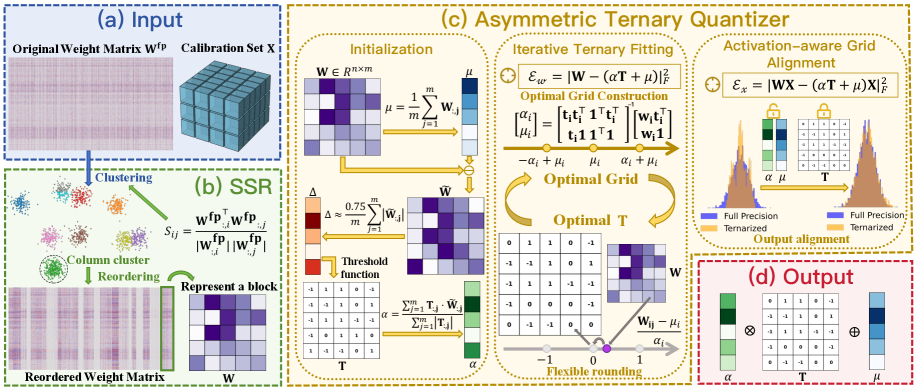
技术框架:PT$^2$-LLM框架主要包含以下几个模块: 1. 非对称三值量化器:作为量化的核心组件,负责将全精度权重映射到三值表示。 2. 迭代三值拟合(ITF):通过交替优化三值网格和灵活舍入,逐步逼近全精度权重,最小化量化误差。 3. 激活感知网格对齐(AGA):根据激活函数的输出,进一步调整三值网格,使其更好地匹配全精度模型的行为。 4. 结构相似性重排序(SSR):利用列间结构相似性,对权重矩阵进行重排序,以减轻异常值的影响,并简化量化过程。
关键创新:论文的关键创新在于: 1. 两阶段细化流程(ITF+AGA):通过迭代优化量化网格,并结合激活感知,更精确地逼近全精度权重,显著降低了量化误差。 2. 结构相似性重排序(SSR):通过对权重矩阵进行重排序,有效地缓解了异常值对量化的影响,提升了整体性能。 与现有方法相比,PT$^2$-LLM无需训练即可实现高效的三值化,并且在处理异常值方面具有更强的鲁棒性。
关键设计: * 非对称三值量化器:允许正负量化范围不对称,更灵活地适应权重的分布。 * 迭代三值拟合(ITF):采用交替优化的方式,逐步逼近最优的三值表示。 * 激活感知网格对齐(AGA):利用激活函数的统计信息,动态调整量化网格。 * 结构相似性重排序(SSR):基于列间结构相似性进行重排序,具体相似度度量方式未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PT$^2$-LLM在内存成本更低的情况下,能够达到与最先进的2-bit PTQ方法相媲美的性能。此外,PT$^2$-LLM还能够加速预填充和解码过程,实现端到端的加速效果。具体的性能提升数据和对比基线需要在论文中进一步查找。
🎯 应用场景
PT$^2$-LLM适用于对计算资源和内存有严格限制的场景,例如移动设备、边缘计算设备等。通过三值化压缩,可以显著降低大语言模型的存储空间和计算复杂度,使其能够在资源受限的环境中部署和运行,从而扩展LLM的应用范围,例如移动端的智能助手、离线翻译等。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive capabilities across diverse tasks, but their large memory and compute demands hinder deployment. Ternarization has gained attention as a promising compression technique, delivering substantial size reduction and high computational efficiency. However, its potential in the post-training quantization (PTQ) setting remains underexplored, due to the challenge of training-free parameter optimization and the quantization difficulty posed by outliers and dispersed weights. To address these issues, we propose PT$^2$-LLM, a post-training ternarization framework tailored for LLMs. At its core is an Asymmetric Ternary Quantizer equipped with a two-stage refinement pipeline: (1) Iterative Ternary Fitting (ITF), which alternates between optimal ternary grid construction and flexible rounding to minimize quantization error, and (2) Activation-aware Grid Alignment (AGA), which further refines the ternary grid to better match full-precision outputs. In addition, we propose a plug-and-play Structural Similarity-based Reordering (SSR) strategy that leverages inter-column structural similarity to ease quantization and mitigate outlier effects, further enhancing overall performance. Extensive experiments demonstrate that PT$^2$-LLM delivers competitive performance against state-of-the-art (SOTA) 2-bit PTQ methods with lower memory cost, while also accelerating both prefill and decoding to achieve end-to-end speedup. The code and models will be available at https://github.com/XIANGLONGYAN/PT2-LLM.