Knowledge distillation through geometry-aware representational alignment
作者: Prajjwal Bhattarai, Mohammad Amjad, Dmytro Zhylko, Tuka Alhanai
分类: cs.LG, cs.AI
发布日期: 2025-09-27
💡 一句话要点
提出基于几何感知的表征对齐知识蒸馏方法,提升语言模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 表征对齐 几何感知 语言模型 模型压缩
📋 核心要点
- 现有特征蒸馏方法难以有效捕捉教师模型特征空间的结构信息,限制了蒸馏效果。
- 利用Procrustes距离和特征Gram矩阵的Frobenius范数作为蒸馏损失,实现几何感知的表征对齐。
- 实验结果表明,该方法在BERT和OPT等语言模型上,分类和指令跟随任务的性能均有提升。
📝 摘要(中文)
知识蒸馏是一种常见的将能力从大型模型迁移到小型模型的范式。传统的蒸馏方法利用教师和学生模型输出的概率分布差异,而基于特征的蒸馏方法通常最小化隐藏层表征之间欧几里得范数的变体。其主要目标是让学生模型模仿教师模型特征空间的结构。本文从理论上证明,现有的特征蒸馏方法,如基于投影的均方误差损失或中心核对齐(CKA),即使在零损失下也无法捕捉特征结构。因此,本文提出使用Procrustes距离和特征Gram矩阵的Frobenius范数(这些距离在表征对齐的上下文中已经很常见)作为蒸馏损失。实验表明,通过本文方法进行的特征蒸馏在分类和指令跟随任务中,跨语言模型系列(BERT和OPT)的蒸馏性能有显著提高,最高可达2个百分点,展示了将特征几何集成到现有蒸馏方法中的潜力。
🔬 方法详解
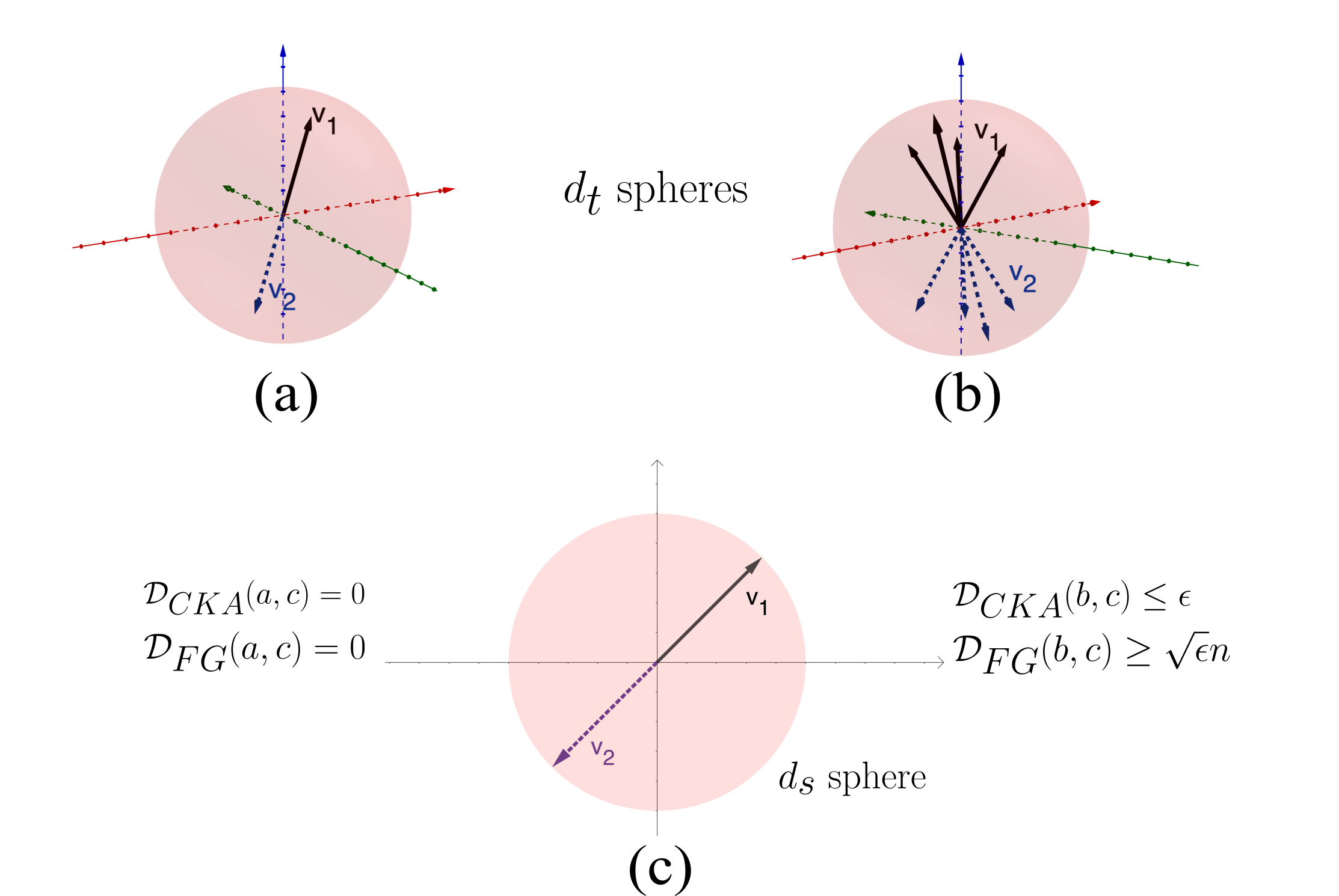
问题定义:现有的知识蒸馏方法,特别是基于特征的蒸馏方法,通常使用均方误差或中心核对齐(CKA)等方法来对齐教师和学生模型的中间层特征。然而,这些方法在捕捉特征空间的几何结构方面存在不足,即使损失很小,也可能无法保证学生模型能够学习到教师模型特征空间的内在结构,从而限制了蒸馏效果。
核心思路:本文的核心思路是利用Procrustes距离和特征Gram矩阵的Frobenius范数来度量和对齐教师和学生模型特征空间的几何结构。这些方法能够更好地捕捉特征之间的关系和相对位置,从而使学生模型能够更准确地模仿教师模型的特征表示。
技术框架:该方法主要包含以下几个步骤:首先,提取教师模型和学生模型的中间层特征表示;然后,计算教师模型和学生模型特征表示之间的Procrustes距离或特征Gram矩阵的Frobenius范数;最后,将计算得到的距离或范数作为蒸馏损失,用于训练学生模型。整个框架可以很容易地集成到现有的知识蒸馏流程中。
关键创新:本文最重要的技术创新点在于引入了几何感知的表征对齐方法,即使用Procrustes距离和特征Gram矩阵的Frobenius范数作为蒸馏损失。与传统的基于欧几里得距离的方法相比,这些方法能够更好地捕捉特征空间的几何结构,从而提高蒸馏效果。
关键设计:关键的设计包括:选择合适的中间层特征进行对齐,选择Procrustes距离或特征Gram矩阵的Frobenius范数作为损失函数,以及调整蒸馏损失在总损失中的权重。具体而言,Procrustes距离通过旋转、平移和缩放学生模型的特征空间,使其与教师模型的特征空间尽可能对齐,然后计算对齐后的距离。特征Gram矩阵的Frobenius范数则直接比较教师和学生模型特征之间相似度关系的差异。
🖼️ 关键图片
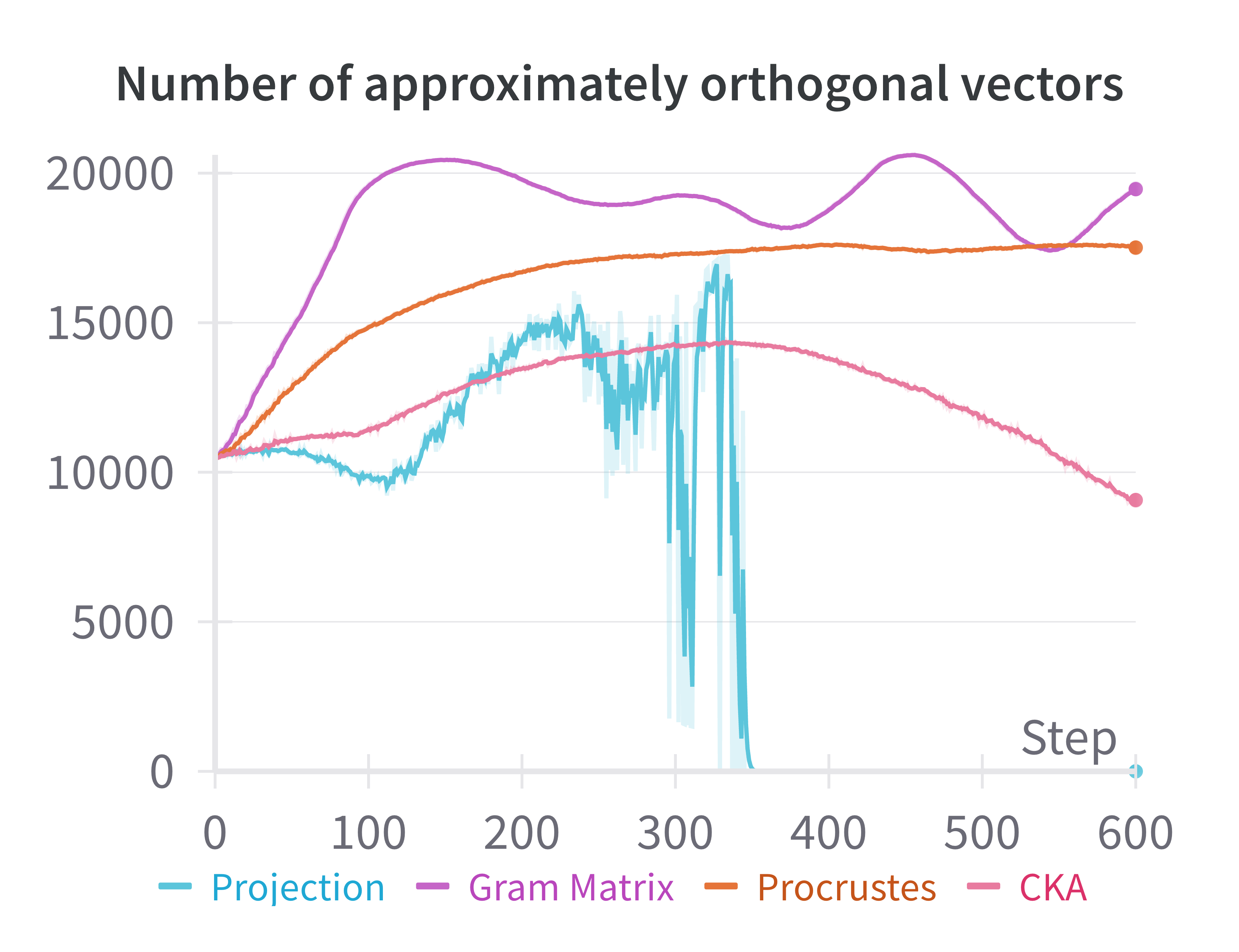
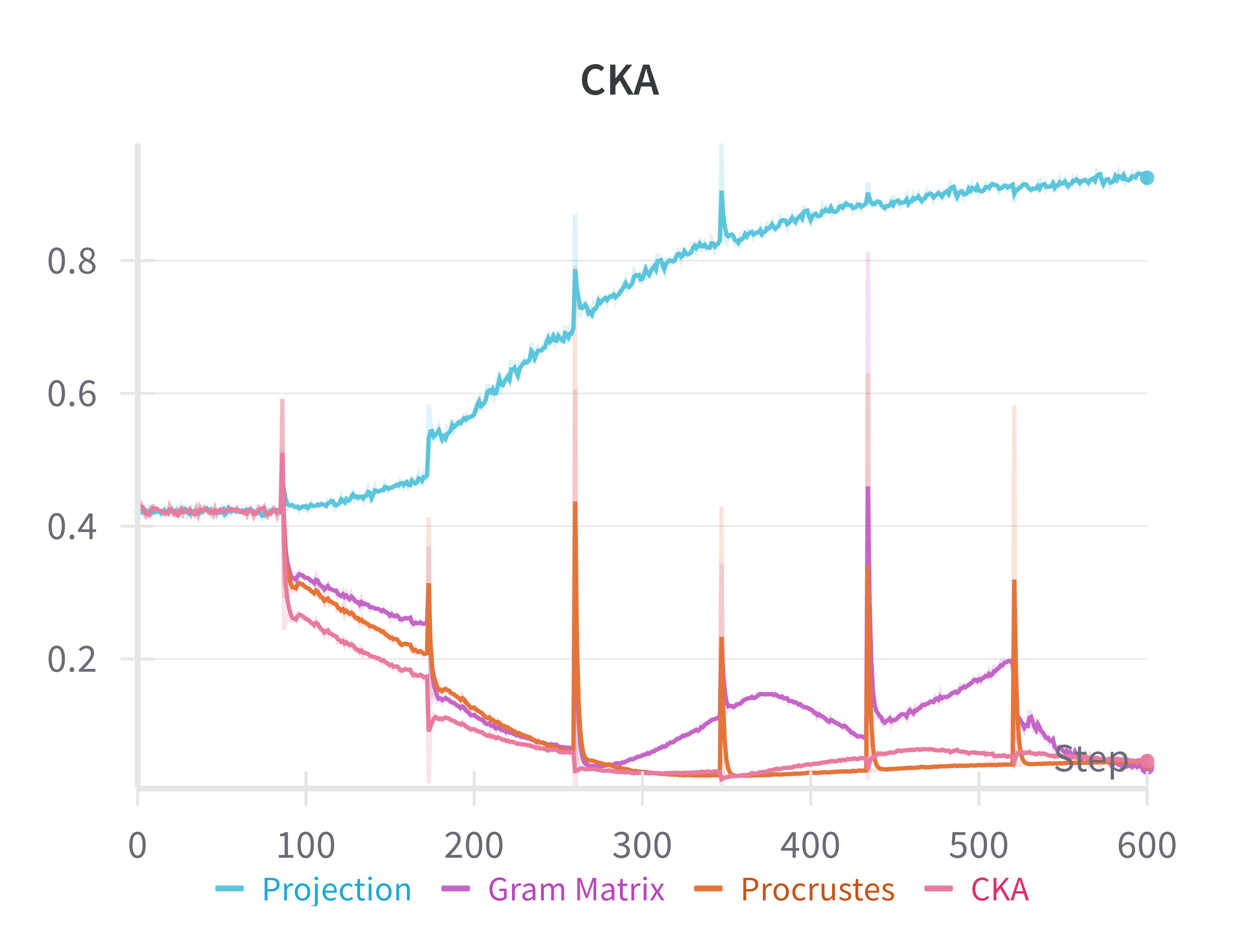
📊 实验亮点
实验结果表明,使用Procrustes距离和特征Gram矩阵的Frobenius范数作为蒸馏损失,在BERT和OPT等语言模型上,分类和指令跟随任务的性能均有显著提高,最高可达2个百分点。例如,在某个具体的分类任务上,使用该方法蒸馏后的学生模型比使用传统方法蒸馏后的学生模型准确率提高了1.5个百分点。
🎯 应用场景
该研究成果可广泛应用于模型压缩和加速领域,尤其是在资源受限的设备上部署大型语言模型。通过知识蒸馏,可以将大型模型的知识迁移到小型模型,从而在保持性能的同时降低计算成本和内存占用。该方法在自然语言处理、计算机视觉等领域具有广泛的应用前景。
📄 摘要(原文)
Knowledge distillation is a common paradigm for transferring capabilities from larger models to smaller ones. While traditional distillation methods leverage a probabilistic divergence over the output of the teacher and student models, feature-based distillation methods often minimize variants of Euclidean norms between the hidden layer representations. The main goal is for the student to mimic the structure of the feature space of the teacher. In this work, we theoretically show that existing feature distillation methods, such as projection based mean squared loss or Centered Kernel Alignment (CKA), cannot capture the feature structure, even under zero loss. We then motivate the use of Procrustes distance and the Frobenius norm of Feature Gram Matrix, distances already common in the context of measuring representational alignment, as distillation losses. We show that feature distillation through our method showcases statistically significant improvement in distillation performance across language models families (BERT and OPT) in classification and instruction-following tasks by up to 2 percentage points, showcasing the potential of integrating feature geometry into existing distillation methods.