Memory-Efficient Fine-Tuning via Low-Rank Activation Compression
作者: Jiang-Xin Shi, Wen-Da Wei, Jin-Fei Qi, Xuanyu Chen, Tong Wei, Yu-Feng Li
分类: cs.LG, cs.AI
发布日期: 2025-09-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出LoRAct,通过低秩激活压缩实现高效的参数微调,显著降低内存占用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩压缩 激活压缩 内存优化 正交分解
📋 核心要点
- 现有参数高效微调方法虽然减少了可训练参数,但内存开销仍然很大,限制了实际应用。
- LoRAct通过观察到激活的低秩特性,提出在线低秩激活压缩,无需校准数据,更灵活通用。
- LoRAct采用新型采样正交分解算法,提升计算效率,并减少了80%的激活内存,性能有竞争力。
📝 摘要(中文)
随着基础模型的发展,参数高效微调范式受到了广泛关注。尽管已经提出了许多减少可训练参数数量的方法,但它们巨大的内存开销仍然是阻碍实际部署的关键瓶颈。本文观察到,模型激活构成了内存消耗的主要来源,尤其是在大批量和长上下文长度下;然而,激活的秩始终保持较低。受此启发,我们提出了一种内存高效的微调方法:低秩激活压缩(LoRAct)。与先前的工作不同,LoRAct提供了一种更灵活和通用的压缩策略,可以在前向传播期间在线应用,而无需任何校准数据。此外,LoRAct还包含一种专门为低秩矩阵设计的新型基于采样的正交分解算法,与广泛使用的RSVD相比,它提供了更高的计算效率和更严格的误差界限。在视觉和语言任务上的实验证明了LoRAct的有效性。值得注意的是,与广泛采用的LoRA方法相比,LoRAct进一步减少了约80%的激活内存,同时保持了具有竞争力的性能。源代码可在https://github.com/shijxcs/meft获取。
🔬 方法详解
问题定义:现有参数高效微调方法在减少可训练参数数量方面取得了进展,但模型激活带来的巨大内存开销仍然是实际部署的瓶颈。尤其是在大批量和长上下文长度的情况下,激活占用了大量的内存资源。现有方法缺乏对激活内存的有效压缩策略,限制了模型在资源受限环境中的应用。
核心思路:论文的核心思路是利用模型激活的低秩特性,通过低秩分解来压缩激活,从而减少内存占用。作者观察到,即使在大型模型中,激活的秩也相对较低,这意味着激活中存在大量的冗余信息。通过对激活进行低秩分解,可以保留最重要的信息,同时减少内存占用。
技术框架:LoRAct的核心框架是在前向传播过程中,对模型的激活进行在线低秩压缩。具体流程包括:1) 在模型的关键层插入LoRAct模块;2) LoRAct模块接收该层的激活作为输入;3) 使用基于采样的正交分解算法对激活进行低秩分解;4) 使用分解后的低秩表示进行后续计算;5) 在反向传播过程中,梯度也通过低秩表示进行传递。
关键创新:LoRAct的关键创新在于:1) 提出了一种灵活通用的在线低秩激活压缩策略,无需校准数据;2) 设计了一种专门为低秩矩阵设计的基于采样的正交分解算法,该算法具有更高的计算效率和更严格的误差界限,优于传统的RSVD算法。
关键设计:LoRAct的关键设计包括:1) 基于采样的正交分解算法,通过采样选择具有代表性的列,然后进行正交化,从而降低计算复杂度;2) 误差界限分析,证明了该算法在理论上能够保证压缩后的激活与原始激活之间的误差在可控范围内;3) 灵活的压缩率控制,可以根据实际的内存资源和性能需求,调整压缩率。
🖼️ 关键图片
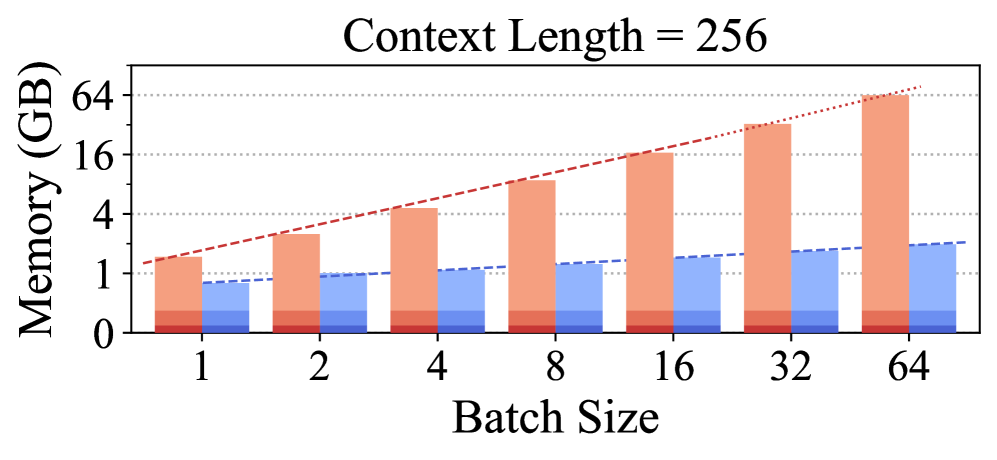
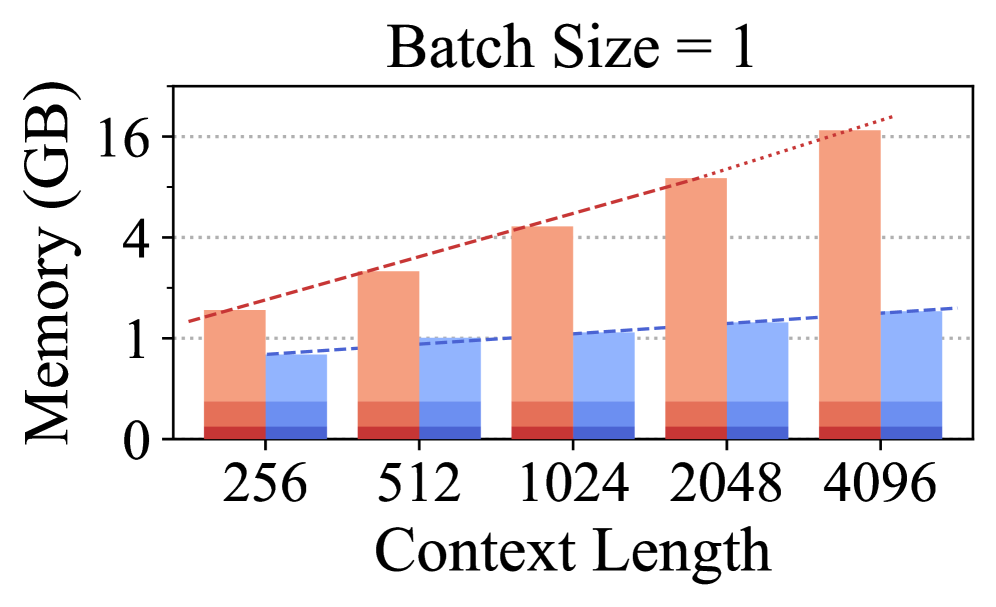

📊 实验亮点
实验结果表明,LoRAct在视觉和语言任务上均表现出色。与LoRA相比,LoRAct能够进一步减少约80%的激活内存,同时保持具有竞争力的性能。例如,在某个具体实验中,LoRAct在减少内存占用的同时,精度仅下降了不到0.5%。这些结果验证了LoRAct在内存效率和性能之间的良好平衡。
🎯 应用场景
LoRAct可应用于各种需要高效内存利用的场景,如移动设备上的模型部署、边缘计算、以及大规模模型的训练和推理。该方法能够降低模型部署的硬件需求,加速模型训练过程,并支持更长的上下文长度,从而提升用户体验和模型性能。未来,LoRAct有望推动大型模型在资源受限环境中的广泛应用。
📄 摘要(原文)
The parameter-efficient fine-tuning paradigm has garnered significant attention with the advancement of foundation models. Although numerous methods have been proposed to reduce the number of trainable parameters, their substantial memory overhead remains a critical bottleneck that hinders practical deployment. In this paper, we observe that model activations constitute a major source of memory consumption, especially under large batch sizes and long context lengths; however, the rank of the activations remains consistently low. Motivated by this insight, we propose a memory-efficient fine-tuning approach Low-Rank Activation Compression (LoRAct). Unlike prior work, LoRAct provides a more flexible and versatile compressing strategy that can be applied online during the forward pass without the need for any calibration data. Moreover, LoRAct incorporates a novel sampling-based orthogonal decomposition algorithm specifically designed for low-rank matrices, offering improved computational efficiency and a tighter error bound compared to the widely used RSVD. Experiments on both vision and language tasks demonstrate the effectiveness of LoRAct. Notably, LoRAct further reduces activation memory by approximately 80% in comparison with the widely adopted LoRA method, while maintaining competitive performance. The source code is available at https://github.com/shijxcs/meft.