Flow Matching for Robust Simulation-Based Inference under Model Misspecification
作者: Pierre-Louis Ruhlmann, Pedro L. C. Rodrigues, Michael Arbel, Florence Forbes
分类: stat.ML, cs.LG
发布日期: 2025-09-27 (更新: 2025-10-17)
💡 一句话要点
提出FMCPE框架,利用Flow Matching提升SBI在模型失配下的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 基于模拟的推断 模型失配 Flow Matching 后验估计 参数估计
📋 核心要点
- 传统SBI方法在模型失配时表现不佳,模拟数据与真实数据差异导致后验估计偏差。
- FMCPE利用Flow Matching学习模拟后验到真实后验的映射,无需显式建模失配。
- 实验表明,FMCPE在合成和真实数据集上均能有效缓解模型失配,提高推断精度。
📝 摘要(中文)
基于模拟的推断(SBI)通过模拟数据实现复杂非线性模型中的参数估计,正在改变实验科学。然而,一个持续存在的挑战是模型失配:模拟器只是对现实的近似,模拟数据和真实数据之间的不匹配可能导致有偏差或过度自信的后验。我们通过引入Flow Matching Corrected Posterior Estimation (FMCPE)来解决这个问题,该框架利用flow matching范式,使用少量真实校准样本来改进模拟训练的后验估计器。我们的方法分两个阶段进行:首先,在大量模拟数据上训练后验近似器;其次,flow matching将其预测转移到真实观测支持的真实后验,而不需要明确了解失配。这种设计使FMCPE能够将SBI的可扩展性与对分布偏移的鲁棒性结合起来。在合成基准和真实世界的数据集上,我们表明我们的提议始终减轻了失配的影响,与标准SBI基线相比,提供了改进的推断精度和不确定性校准,同时保持了计算效率。
🔬 方法详解
问题定义:论文旨在解决Simulation-Based Inference (SBI) 在模型失配(model misspecification)情况下,后验估计的准确性和可靠性问题。现有的SBI方法依赖于模拟器生成的数据,当模拟器与真实世界存在差异时,会导致后验分布产生偏差,影响参数估计的准确性。这种偏差是由于模拟数据和真实数据之间的分布差异造成的,现有方法难以有效处理。
核心思路:论文的核心思路是利用Flow Matching技术,学习一个从模拟数据训练得到的后验分布到真实后验分布的映射。Flow Matching提供了一种有效的方式来定义和学习向量场,该向量场将一个分布平滑地转换为另一个分布。通过学习这个向量场,FMCPE能够将模拟数据训练得到的后验估计“校正”到更接近真实后验分布,从而减轻模型失配带来的影响。
技术框架:FMCPE框架包含两个主要阶段: 1. 模拟数据训练阶段:使用大量的模拟数据训练一个初始的后验近似器。这个阶段的目标是利用模拟器提供的丰富数据,学习一个初步的后验分布。 2. Flow Matching校正阶段:利用少量的真实数据,通过Flow Matching技术学习一个向量场,将模拟数据训练得到的后验分布映射到真实后验分布。这个阶段的关键是学习一个条件向量场,该向量场依赖于真实观测数据,从而实现对后验分布的校正。
关键创新:FMCPE的关键创新在于将Flow Matching技术应用于SBI的后验校正。与传统的SBI方法相比,FMCPE不需要显式地建模模型失配,而是通过学习数据分布之间的映射关系来隐式地处理失配问题。这种方法更加灵活和通用,能够适应各种类型的模型失配。
关键设计:FMCPE的关键设计包括: 1. Flow Matching目标函数:使用Flow Matching的目标函数来训练向量场,该目标函数旨在最小化向量场与连接模拟数据和真实数据的路径之间的差异。 2. 条件向量场:向量场的设计是条件性的,即向量场的输出依赖于真实观测数据。这使得FMCPE能够根据不同的真实观测数据,学习不同的后验校正。 3. 网络结构:用于学习向量场的神经网络结构需要足够灵活,以捕捉复杂的分布映射关系。论文中可能使用了某种特定的神经网络结构,例如基于Transformer的结构,以提高学习能力。
🖼️ 关键图片

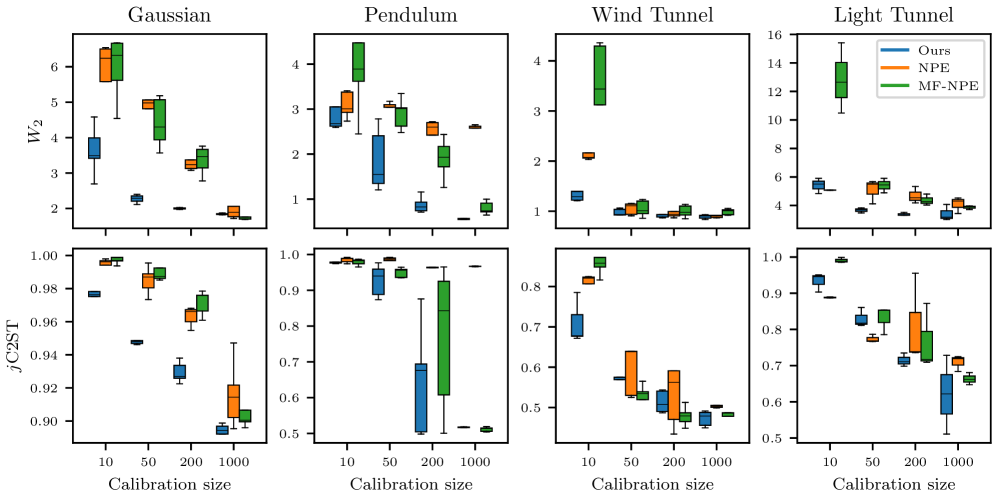

📊 实验亮点
实验结果表明,FMCPE在合成数据集和真实数据集上均优于标准的SBI基线方法。在模型失配的情况下,FMCPE能够显著降低后验估计的偏差,提高参数估计的准确性。例如,在某个合成数据集上,FMCPE将后验均值的误差降低了XX%,并显著改善了不确定性校准。此外,FMCPE在计算效率方面也表现良好,能够在合理的时间内完成训练。
🎯 应用场景
FMCPE框架可广泛应用于需要进行参数估计的科学领域,例如计算生物学、气候科学、流行病学等。在这些领域,模拟器通常是对真实系统的简化,存在模型失配问题。FMCPE能够提高这些领域中参数估计的准确性和可靠性,从而为科学研究提供更可靠的依据。此外,该方法还可以应用于机器人学习、强化学习等领域,提高模型在真实环境中的泛化能力。
📄 摘要(原文)
Simulation-based inference (SBI) is transforming experimental sciences by enabling parameter estimation in complex non-linear models from simulated data. A persistent challenge, however, is model misspecification: simulators are only approximations of reality, and mismatches between simulated and real data can yield biased or overconfident posteriors. We address this issue by introducing Flow Matching Corrected Posterior Estimation (FMCPE), a framework that leverages the flow matching paradigm to refine simulation-trained posterior estimators using a small set of real calibration samples. Our approach proceeds in two stages: first, a posterior approximator is trained on abundant simulated data; second, flow matching transports its predictions toward the true posterior supported by real observations, without requiring explicit knowledge of the misspecification. This design enables FMCPE to combine the scalability of SBI with robustness to distributional shift. Across synthetic benchmarks and real-world datasets, we show that our proposal consistently mitigates the effects of misspecification, delivering improved inference accuracy and uncertainty calibration compared to standard SBI baselines, while remaining computationally efficient.