Emergence of Superposition: Unveiling the Training Dynamics of Chain of Continuous Thought
作者: Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, Yuandong Tian
分类: cs.LG
发布日期: 2025-09-27 (更新: 2025-10-06)
备注: 29 pages, 5 figures
💡 一句话要点
揭示连续思维链中叠加机制的涌现:通过训练动态分析Transformer的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 连续思维链 大型语言模型 推理能力 叠加机制 训练动态 有向图可达性 Transformer 索引匹配logit
📋 核心要点
- 大型语言模型推理能力不足,连续思维链通过隐式并行思考提升推理能力,但其训练机制尚不明确。
- 本文通过理论分析简化的Transformer在有向图可达性问题上的训练动态,揭示叠加机制的涌现过程。
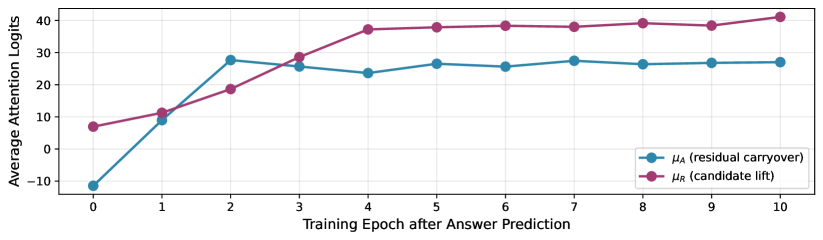
- 研究发现,索引匹配logit在训练中先增加后有界,平衡了探索和利用,促使模型学习到叠加机制。
📝 摘要(中文)
本文研究了连续思维链(continuous CoT)如何提升大型语言模型(LLMs)的推理能力,该方法通过隐式并行思考实现。前期工作表明,配备连续CoT的两层Transformer可以通过在连续思维中保持多个推理轨迹的叠加来有效地解决有向图可达性问题。然而,叠加机制如何从基于梯度的训练方法中自然学习仍然不清楚。为了填补这一空白,本文从理论上分析了一个简化的两层Transformer在有向图可达性问题上的训练动态,以揭示叠加机制如何在训练过程中涌现,分为两个阶段:(i)自回归扩展连续思维的思维生成阶段,以及(ii)将思维转化为最终答案的预测阶段。分析表明,在使用连续思维进行训练时,索引匹配logit(反映模型局部搜索能力强度的重要指标)将首先增加,然后在温和的假设下保持有界。有界的索引匹配logit有效地平衡了推理过程中的探索和利用:模型将利用局部问题结构来识别合理的搜索轨迹,并在不确定哪个解决方案正确时,为多个此类轨迹分配相当的权重以进行探索,从而产生叠加。实验结果跟踪了logits的增长,进一步验证了该理论。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中,连续思维链(Continuous CoT)方法背后的训练机制问题。虽然Continuous CoT已被证明可以提高LLM的推理能力,特别是通过在“连续思维”中维护多个推理轨迹的叠加来实现,但目前尚不清楚这种叠加机制是如何通过标准的梯度下降训练方法学习到的。现有的理论工作主要集中在证明Continuous CoT的有效性,而缺乏对训练过程本身的深入理解。
核心思路:论文的核心思路是通过分析一个简化的两层Transformer模型在有向图可达性问题上的训练动态,来揭示叠加机制是如何在训练过程中自发涌现的。作者认为,理解训练过程中关键指标(如索引匹配logit)的变化,可以帮助解释模型如何学习到在多个可能的推理路径上进行“叠加”的能力。
技术框架:论文将训练过程分为两个阶段:(1)思维生成阶段:模型自回归地扩展连续思维,生成一系列中间状态。(2)预测阶段:模型将生成的连续思维转化为最终答案。作者通过数学推导,分析了在这些阶段中,索引匹配logit(index-matching logit)的变化规律。索引匹配logit反映了模型在局部搜索中找到正确推理步骤的能力。
关键创新:论文的关键创新在于从理论上揭示了叠加机制在Continuous CoT训练中的涌现过程。通过分析索引匹配logit的变化,作者证明了在训练过程中,模型会自发地学习到一种平衡探索和利用的策略。具体来说,索引匹配logit会先增加,然后在一个有界的范围内波动。这种有界性使得模型既能利用已知的局部结构进行推理,又能保持对多种可能推理路径的探索,从而实现叠加。
关键设计:论文使用了一个简化的两层Transformer模型,并针对有向图可达性问题设计了特定的训练目标。关键的数学推导集中在分析索引匹配logit的梯度和变化趋势上。作者通过引入一些温和的假设,证明了索引匹配logit的有界性。此外,实验部分通过跟踪logits的增长,验证了理论分析的正确性。
🖼️ 关键图片

📊 实验亮点
实验结果通过跟踪logits的增长,验证了理论分析的正确性。具体来说,实验观察到索引匹配logit在训练初期快速增长,随后趋于稳定,并保持在一个有界的范围内。这与理论分析中预测的“先增加后有界”的趋势相符,从而为叠加机制的涌现提供了经验证据。
🎯 应用场景
该研究成果有助于更好地理解和优化大型语言模型的推理能力,特别是在需要复杂推理和搜索的任务中。例如,可以应用于知识图谱推理、规划问题、代码生成等领域。通过理解叠加机制的训练过程,可以设计更有效的训练策略,提升模型的泛化能力和鲁棒性。
📄 摘要(原文)
Previous work shows that the chain of continuous thought (continuous CoT) improves the reasoning capability of large language models (LLMs) by enabling implicit parallel thinking, and a subsequent work provided theoretical insight by showing that a two-layer transformer equipped with continuous CoT can efficiently solve directed graph reachability by maintaining a superposition of multiple reasoning traces in the continuous thought. However, it remains unclear how the superposition mechanism is naturally learned from gradient-based training methods. To fill this gap, we theoretically analyze the training dynamics of a simplified two-layer transformer on the directed graph reachability problem to unveil how the superposition mechanism emerges during training in two training stages -- (i) a thought-generation stage that autoregressively expands the continuous thought, and (ii) a prediction stage that converts the thought into the final answer. Our analysis reveals that during training using continuous thought, the index-matching logit, an important quantity which reflects the strength of the model's local search ability, will first increase and then remain bounded under mild assumptions. The bounded index-matching logit effectively balances exploration and exploitation during the reasoning process: the model will exploit local problem structures to identify plausible search traces, and assign comparable weights to multiple such traces to explore when it is uncertain about which solution is correct, which results in superposition. Our experimental results tracking the growth of logits further validate our theory.