LLM Interpretability with Identifiable Temporal-Instantaneous Representation
作者: Xiangchen Song, Jiaqi Sun, Zijian Li, Yujia Zheng, Kun Zhang
分类: cs.LG
发布日期: 2025-09-27 (更新: 2026-01-02)
备注: NeurIPS 2025
💡 一句话要点
提出可识别时序瞬时表示的LLM可解释性框架,提升概念关系发现能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM可解释性 因果表示学习 时序因果发现 稀疏自编码器 概念关系建模
📋 核心要点
- 现有LLM可解释性方法,如稀疏自编码器,缺乏对时序依赖和瞬时关系的建模,且缺乏理论保证。
- 论文提出可识别时序因果表示学习框架,专门针对LLM高维概念空间,捕捉时延和瞬时因果关系。
- 通过扩展SAE技术,该框架成功发现LLM激活中重要的概念关系,提升了LLM的可解释性。
📝 摘要(中文)
尽管大型语言模型(LLM)展现出卓越的能力,但理解其内部表示仍然充满挑战。稀疏自编码器(SAE)等机制可解释性工具旨在从LLM中提取可解释的特征,但缺乏时序依赖建模、瞬时关系表示以及更重要的理论保证,从而削弱了理论基础和后续分析所需的实际信心。因果表示学习(CRL)为揭示潜在概念提供了理论基础,但由于计算效率低下,现有方法无法扩展到LLM丰富的概念空间。为了弥合这一差距,我们引入了一个专为LLM高维概念空间设计的可识别时序因果表示学习框架,捕捉了时延和瞬时因果关系。我们的方法提供了理论保证,并在扩展到与真实世界复杂性相匹配的合成数据集上展示了有效性。通过使用我们的时序因果框架扩展SAE技术,我们成功地发现了LLM激活中重要的概念关系。我们的研究结果表明,对时序和瞬时概念关系进行建模可以提高LLM的可解释性。
🔬 方法详解
问题定义:现有LLM可解释性方法,例如基于稀疏自编码器(SAE)的方法,主要关注提取LLM中的可解释特征,但忽略了概念之间的时间依赖关系和瞬时因果关系。此外,这些方法缺乏理论保证,使得对LLM内部机制的理解缺乏坚实的基础。因果表示学习(CRL)虽然提供了理论基础,但计算复杂度高,难以扩展到LLM这样具有丰富概念空间的大规模模型。
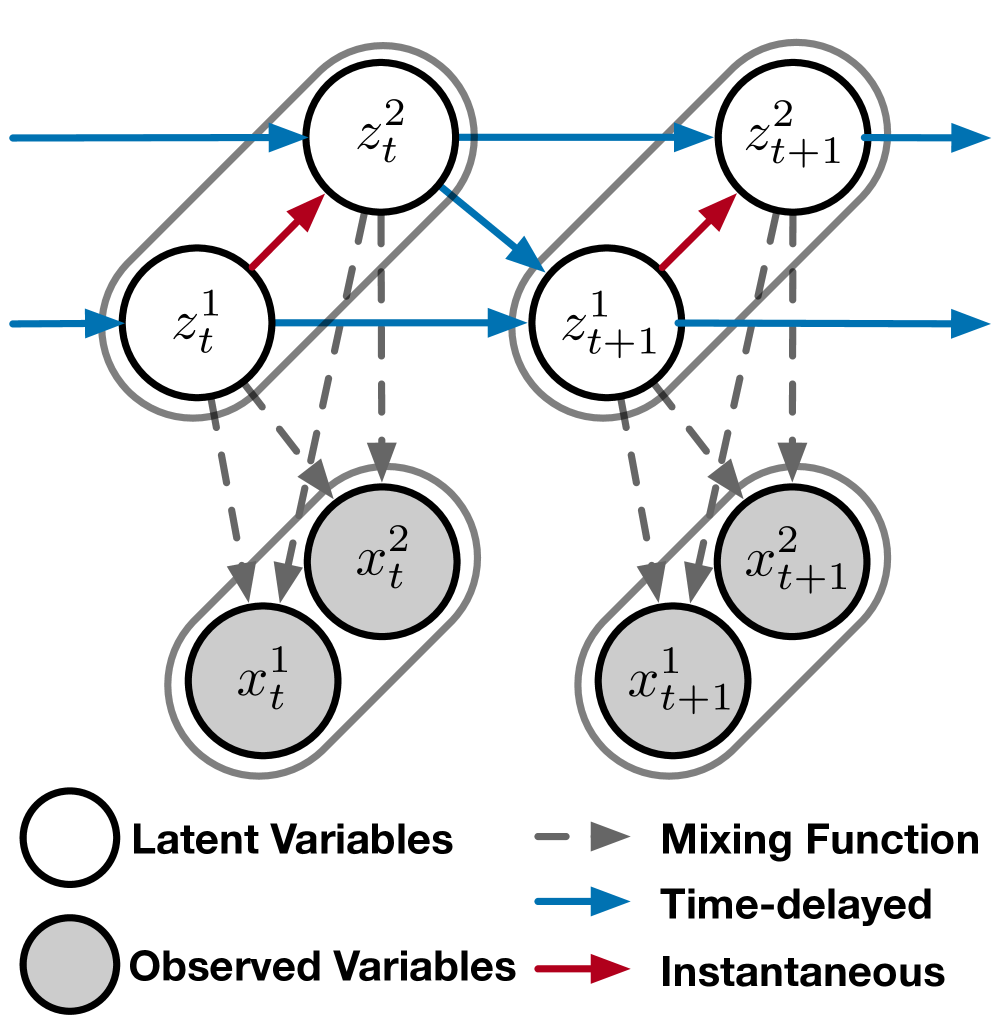
核心思路:论文的核心思路是结合因果表示学习的理论优势和稀疏自编码器的实践可行性,提出一种可识别的时序因果表示学习框架。该框架旨在同时捕捉LLM内部概念之间的时间延迟因果关系和瞬时因果关系,从而更全面地理解LLM的内部表示。通过引入可识别性约束,保证学习到的因果结构具有唯一性,避免了因果推断中的歧义性。
技术框架:该框架主要包含以下几个阶段:1) 使用稀疏自编码器从LLM的激活中提取潜在的概念表示。2) 利用时序因果发现算法,例如Granger causality或PCMCI,学习概念之间的时间延迟因果关系。3) 使用结构因果模型(SCM)或类似的因果建模方法,学习概念之间的瞬时因果关系。4) 将学习到的时序和瞬时因果关系整合到一个统一的因果图中,从而全面描述LLM内部的概念关系。
关键创新:论文的关键创新在于提出了一个可识别的时序因果表示学习框架,该框架能够同时捕捉LLM内部概念之间的时间延迟因果关系和瞬时因果关系。与现有方法相比,该框架具有更强的理论基础和更全面的概念关系建模能力。此外,通过引入可识别性约束,保证了学习到的因果结构具有唯一性。
关键设计:在时序因果发现阶段,可以选择不同的算法,例如Granger causality或PCMCI,具体选择取决于数据集的特性和计算资源的限制。在瞬时因果关系建模阶段,可以使用结构因果模型(SCM)或类似的因果建模方法。关键的设计在于如何将时序和瞬时因果关系整合到一个统一的因果图中,这需要仔细考虑不同因果关系的权重和优先级。此外,可识别性约束的选择也是一个重要的设计考虑因素,需要根据具体的应用场景进行调整。
🖼️ 关键图片


📊 实验亮点
论文在合成数据集上验证了所提出框架的有效性,并将其应用于实际的LLM激活数据。实验结果表明,该框架能够成功发现LLM内部重要的概念关系,例如,揭示了某些概念之间的因果关系,并验证了这些因果关系与LLM的行为之间的关联性。具体的性能数据和对比基线信息未知。
🎯 应用场景
该研究成果可应用于提升LLM的可解释性和可控性,例如,通过理解LLM内部的概念关系,可以更好地诊断LLM的偏差和漏洞,并设计更有效的干预措施。此外,该研究还可以用于知识发现和迁移学习,例如,将LLM学习到的概念关系迁移到其他任务或领域。
📄 摘要(原文)
Despite Large Language Models' remarkable capabilities, understanding their internal representations remains challenging. Mechanistic interpretability tools such as sparse autoencoders (SAEs) were developed to extract interpretable features from LLMs but lack temporal dependency modeling, instantaneous relation representation, and more importantly theoretical guarantees, undermining both the theoretical foundations and the practical confidence necessary for subsequent analyses. While causal representation learning (CRL) offers theoretically grounded approaches for uncovering latent concepts, existing methods cannot scale to LLMs' rich conceptual space due to inefficient computation. To bridge the gap, we introduce an identifiable temporal causal representation learning framework specifically designed for LLMs' high-dimensional concept space, capturing both time-delayed and instantaneous causal relations. Our approach provides theoretical guarantees and demonstrates efficacy on synthetic datasets scaled to match real-world complexity. By extending SAE techniques with our temporal causal framework, we successfully discover meaningful concept relationships in LLM activations. Our findings show that modeling both temporal and instantaneous conceptual relationships advances the interpretability of LLMs.