Two-Scale Latent Dynamics for Recurrent-Depth Transformers
作者: Francesco Pappone, Donato Crisostomi, Emanuele Rodolà
分类: cs.LG
发布日期: 2025-09-27 (更新: 2025-11-13)
💡 一句话要点
针对循环深度Transformer,提出基于二阶步长差的早退机制,提升效率与稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 循环深度Transformer 早退机制 二阶差分 序列建模 计算效率
📋 核心要点
- 循环深度Transformer在计算资源受限时,通过迭代优化隐变量来提升性能,但现有早退策略效率和稳定性不足。
- 论文提出一种基于模型步长二阶差分的早退机制,利用循环迭代过程中的几何特性,更准确地判断何时停止迭代。
- 实验表明,该方法在性能、稳定性和时间效率上优于基于KL散度的早退策略及其一阶变体,验证了其有效性。
📝 摘要(中文)
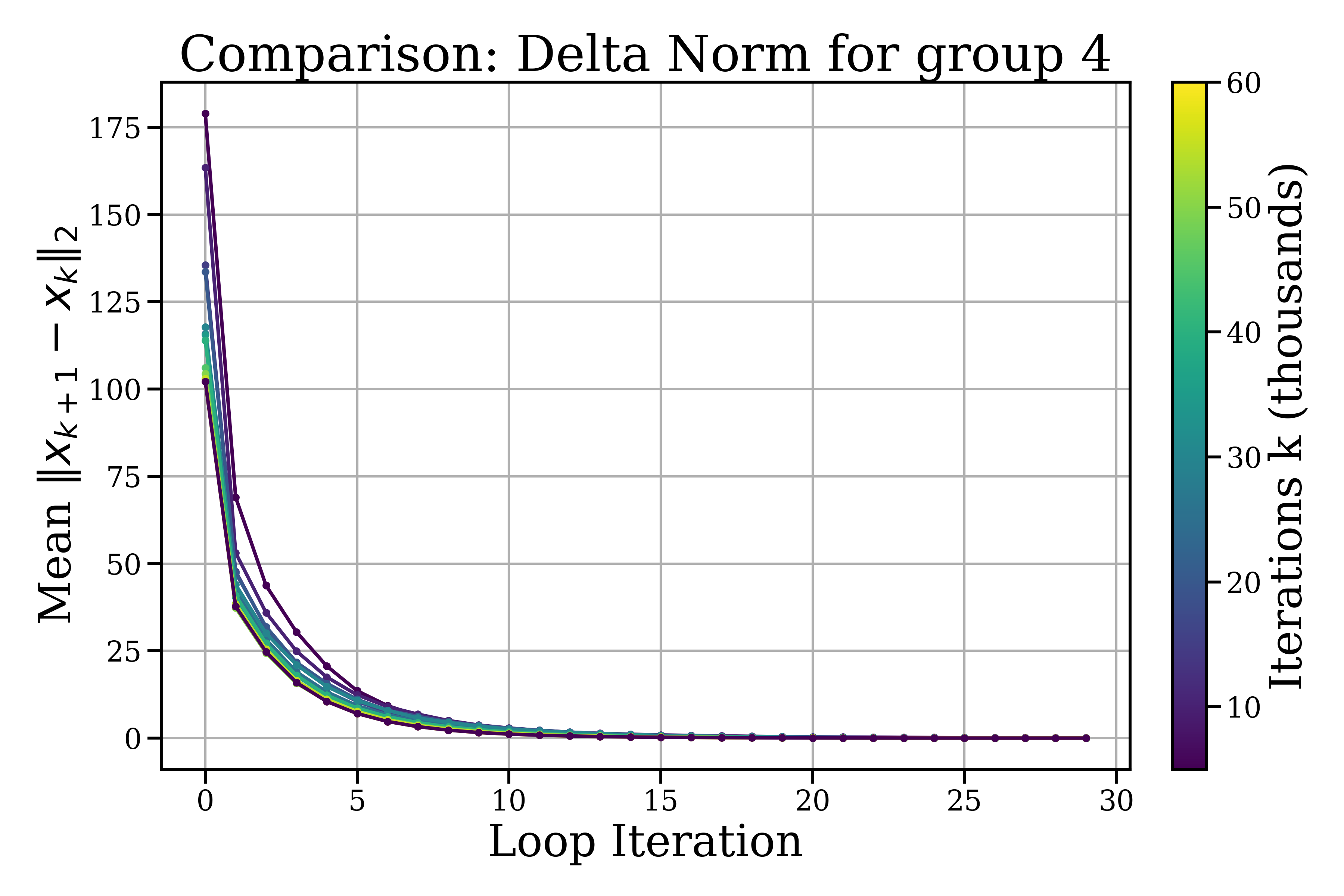
循环深度Transformer通过在发出token之前迭代潜在计算来扩展测试时计算。本文研究了这些迭代的几何特性,并提出了一个简单的双尺度操作图景:(i)在一个循环块内,更新充当小规模的细化;(ii)在连续的块之间,状态经历更大规模的漂移。通过训练,我们的测量表明循环步长变得更小,并且彼此越来越正交,这表明更好地局部建模精细结构,而不是仅仅朝着一个方向推进。这些动态促使我们提出了一种基于模型步长二阶差分的早退机制,我们表明,与Geiping等人基于KL散度的退出策略及其朴素的一阶对应策略相比,该机制在性能、稳定性和时间效率方面都更优越。
🔬 方法详解
问题定义:循环深度Transformer旨在通过在token生成前进行多次迭代计算来提升性能,尤其是在计算资源有限的情况下。然而,如何有效地确定何时停止迭代(即早退机制)是一个关键问题。现有的基于KL散度的早退策略以及简单的一阶变体,在性能、稳定性和时间效率方面存在不足,无法充分利用循环迭代过程中的信息。
核心思路:论文的核心思路是观察到循环深度Transformer在迭代过程中存在两种尺度的动态变化:循环块内的精细调整和小规模漂移,以及跨块的更大规模变化。通过分析迭代步长的几何特性,特别是二阶差分,可以更准确地判断迭代是否收敛,从而实现更有效的早退。
技术框架:整体框架基于循环深度Transformer,其核心在于循环块的迭代过程。论文的关键在于提出了新的早退机制,该机制基于模型在迭代过程中的步长二阶差分。具体而言,计算连续迭代步长之间的差异,并利用该差异的幅度作为早退的指标。当该指标低于某个阈值时,则认为迭代已经收敛,可以提前退出。
关键创新:最重要的技术创新点在于利用了迭代步长的二阶差分作为早退的依据。与现有方法相比,二阶差分能够更敏感地捕捉迭代过程中的细微变化,从而更准确地判断迭代是否收敛。这种方法避免了KL散度计算的复杂性,并且能够更好地适应循环深度Transformer的动态特性。
关键设计:关键设计在于二阶差分的计算方式和早退阈值的设定。具体而言,步长二阶差分可以通过计算连续三个迭代状态之间的差分得到。早退阈值的设定需要根据具体的任务和数据集进行调整,可以通过实验来确定最佳的阈值范围。此外,论文可能还涉及一些正则化项或损失函数的设计,以进一步提高模型的稳定性和性能(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
论文提出的基于二阶步长差的早退机制,在性能、稳定性和时间效率方面均优于基于KL散度的早退策略及其一阶变体。具体性能提升数据未知,但强调了在相同性能水平下,新方法能够显著减少计算量,并提高模型的稳定性。
🎯 应用场景
该研究成果可应用于各种需要高效计算的序列建模任务,例如机器翻译、语音识别、文本生成等。通过更智能的早退机制,可以在保证性能的同时显著降低计算成本,特别是在资源受限的边缘设备上具有重要意义。未来的研究可以探索更复杂的动态特性,进一步优化早退策略。
📄 摘要(原文)
Recurrent-depth transformers scale test-time compute by iterating latent computations before emitting tokens. We study the geometry of these iterates and argue for a simple, two-scale operational picture: (i) within a looped block, updates act as small-scale refinements; (ii) across consecutive blocks, states undergo a larger-scale drift. Across training, our measurements show that loop steps become smaller and increasingly orthogonal to one another, indicating better local modeling of fine structure rather than merely pushing in a single direction. These dynamics motivate an early-exit mechanism based on the model's second-order difference in step-size, which we show is superior in terms of performance, stability and time-efficiency, when compared to the KL-divergence exit strategy of Geiping et al. and its naive first-order counterpart.