Adaptive Token-Weighted Differential Privacy for LLMs: Not All Tokens Require Equal Protection
作者: Manjiang Yu, Priyanka Singh, Xue Li, Yang Cao
分类: cs.LG, cs.AI
发布日期: 2025-09-27
备注: 18 pages
💡 一句话要点
提出自适应Token加权差分隐私(ATDP)方法,加速LLM差分隐私训练并提升敏感信息保护。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 大型语言模型 隐私保护 自适应加权 梯度下降
📋 核心要点
- 现有DPSGD方法对所有梯度注入统一噪声,导致LLM训练时间过长,精度下降。
- ATDP自适应地为敏感和非敏感token分配不同的梯度权重,早期注入大噪声扰乱记忆,后期针对性注入。
- ATDP结合redacted微调,在保证隐私保护和精度的情况下,训练时间缩短约90%。
📝 摘要(中文)
大型语言模型(LLM)经常记忆敏感或个人信息,引发严重的隐私问题。现有的差分隐私随机梯度下降(DPSGD)变体对每个梯度步骤注入统一噪声,显著延长训练时间并降低模型精度。我们提出,将噪声主要集中在与敏感token相关的梯度上,可以显著减少DP训练时间,加强对敏感信息的保护,同时保持模型在非敏感数据上的性能。我们通过自适应Token加权差分隐私(ATDP)来实现这一想法,ATDP是vanilla DP-SGD的修改版,它自适应地为敏感和非敏感token分配不同的梯度权重。通过在训练的早期阶段采用更大的噪声尺度,ATDP迅速扰乱对敏感内容的记忆。因此,ATDP只需要在标准微调后进行几个额外的轻量级后处理epochs,主要针对与敏感token对应的参数注入有针对性的噪声,从而最大限度地减少对模型通用能力的影响。ATDP可以无缝集成到任何现有的基于DP的微调pipeline中,或者直接应用于非私有模型,作为一种快速的隐私增强措施。此外,结合初始的redacted微调阶段,ATDP形成了一个简化的DP pipeline,实现了与最先进的DP-SGD方法相当的canary保护,显著降低了DP微调的计算开销,将训练时间缩短了约90%,同时实现了相当或更优越的隐私保护和最小的精度下降。
🔬 方法详解
问题定义:大型语言模型容易记忆敏感信息,而现有的差分隐私训练方法(如DPSGD)通过对所有梯度添加噪声来保护隐私,但这种方式会显著增加训练时间和降低模型精度。如何在保证隐私的前提下,减少训练开销,同时保持模型性能,是本文要解决的核心问题。
核心思路:论文的核心思路是并非所有token都需要同等程度的隐私保护。敏感token(包含个人信息等)的梯度需要更强的噪声注入,而非敏感token则可以减少噪声注入。通过自适应地调整不同token的梯度权重,可以在保护敏感信息的同时,减少对模型整体性能的影响,并加速训练过程。
技术框架:ATDP方法主要包含以下几个阶段: 1. 标准微调:首先进行标准的LLM微调。 2. 自适应Token加权:根据token的敏感程度,自适应地分配梯度权重。敏感token分配更高的权重,非敏感token分配较低的权重。 3. 差分隐私训练:使用加权后的梯度进行DPSGD训练,对梯度注入噪声。 4. 轻量级后处理:在微调后,针对敏感token对应的参数进行额外的噪声注入,进一步加强隐私保护。 5. Redacted微调 (可选):在ATDP之前,可以先进行redacted微调,移除训练数据中的敏感信息,进一步提升隐私保护效果。
关键创新:ATDP的关键创新在于自适应的token加权机制。与传统的DPSGD对所有梯度注入相同噪声不同,ATDP能够根据token的敏感程度动态调整噪声注入的强度。这种方法能够更有效地利用噪声预算,在保护敏感信息的同时,减少对模型性能的影响。
关键设计:ATDP的关键设计包括: 1. 梯度权重分配策略:如何确定每个token的敏感程度,并根据敏感程度分配梯度权重。论文可能采用启发式方法或基于模型的预测来确定token的敏感程度。 2. 噪声尺度调整:如何根据梯度权重调整噪声尺度,以满足差分隐私的要求。权重高的token对应的梯度注入更大的噪声。 3. Redacted微调策略:如果采用redacted微调,需要设计有效的策略来移除训练数据中的敏感信息,同时避免对模型性能产生过大的影响。
🖼️ 关键图片

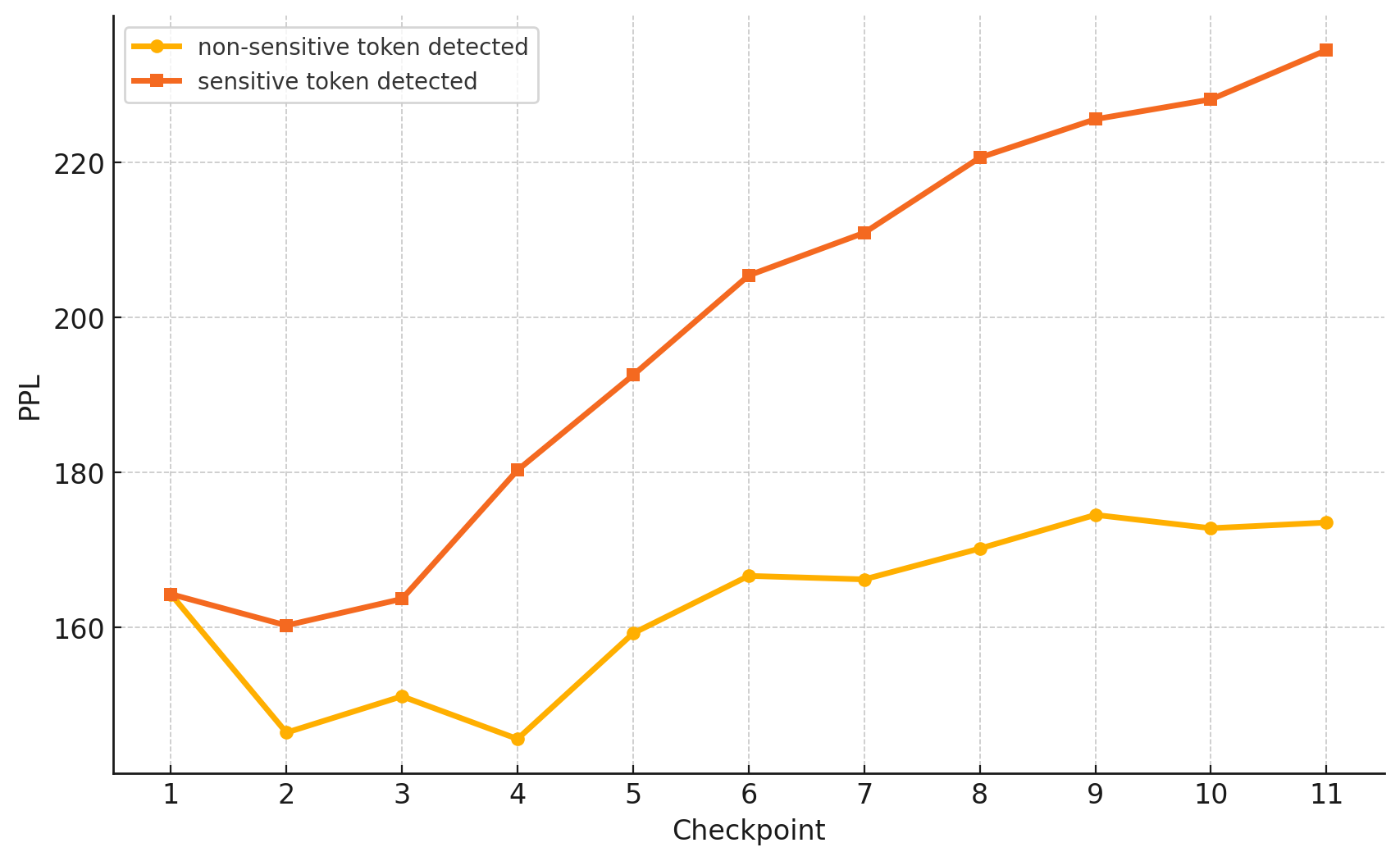
📊 实验亮点
实验结果表明,ATDP方法在保证与最先进的DP-SGD方法相当的canary保护水平下,能够将DP微调的计算开销降低约90%,显著缩短训练时间。同时,ATDP在隐私保护和模型精度方面也取得了相当或更优越的结果,表明其在实际应用中具有很高的价值。
🎯 应用场景
ATDP方法可应用于各种需要保护用户隐私的LLM应用场景,例如:医疗健康领域的电子病历分析、金融领域的客户信息处理、教育领域的个性化学习辅导等。该方法能够降低差分隐私训练的成本,加速LLM在隐私敏感领域的部署,并提升用户对AI服务的信任度。
📄 摘要(原文)
Large language models (LLMs) frequently memorize sensitive or personal information, raising significant privacy concerns. Existing variants of differential privacy stochastic gradient descent (DPSGD) inject uniform noise into every gradient step, significantly extending training time and reducing model accuracy. We propose that concentrating noise primarily on gradients associated with sensitive tokens can substantially decrease DP training time, strengthen the protection of sensitive information, and simultaneously preserve the model's performance on non-sensitive data. We operationalize this insight through Adaptive Token-Weighted Differential Privacy (ATDP), a modification of vanilla DP-SGD that adaptively assigns different gradient weights to sensitive and non-sensitive tokens. By employing a larger noise scale at the early stage of training, ATDP rapidly disrupts memorization of sensitive content. As a result, ATDP only requires a few additional epochs of lightweight post-processing following standard fine-tuning, injecting targeted noise primarily on parameters corresponding to sensitive tokens, thus minimally affecting the model's general capabilities. ATDP can be seamlessly integrated into any existing DP-based fine-tuning pipeline or directly applied to non-private models as a fast privacy-enhancing measure. Additionally, combined with an initial redacted fine-tuning phase, ATDP forms a streamlined DP pipeline that achieves comparable canary protection to state-of-the-art DP-SGD methods, significantly reduces the computational overhead of DP fine-tuning, shortening training time by approximately 90 percent, while achieving comparable or superior privacy protection and minimal accuracy degradation.