Towards Monotonic Improvement in In-Context Reinforcement Learning
作者: Wenhao Zhang, Shao Zhang, Xihuai Wang, Yang Li, Ying Wen
分类: cs.LG, cs.AI
发布日期: 2025-09-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出Context Value Informed ICRL,解决ICRL中因上下文歧义导致的性能退化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文强化学习 ICRL 上下文价值 单调改进 序列模型
📋 核心要点
- 现有ICRL方法在测试时无法像训练数据那样持续改进,存在因模型自身动作导致的上下文歧义问题。
- 论文提出Context Value Informed ICRL (CV-ICRL),利用上下文价值作为显式信号,指导策略学习。
- 实验表明,CV-ICRL能有效缓解性能下降,提升ICRL在不同任务和环境中的整体能力。
📝 摘要(中文)
上下文强化学习(ICRL)已成为一种有前景的范式,它通过利用过去的经验作为上下文,无需更新参数即可快速适应新任务。最近的方法在大规模序列模型上训练来自在线RL的单调策略改进数据,旨在持续改进测试时的性能。然而,我们的实验分析揭示了一个关键缺陷:这些模型在测试时无法像训练数据那样表现出持续的改进。从理论上讲,我们将这种现象识别为上下文歧义,即模型自身随机动作可能产生一个交互历史,该历史误导性地类似于训练数据中次优策略的交互历史,从而启动了不良动作选择的恶性循环。为了解决上下文歧义,我们引入了上下文价值到训练阶段,并提出了上下文价值指导的ICRL(CV-ICRL)。CV-ICRL使用上下文价值作为显式信号,表示理论上策略在当前上下文中可实现的理想性能。随着上下文的扩展,上下文价值可以包含更多与任务相关的信息,因此理想的性能应该是单调不减的。我们证明了上下文价值收紧了相对于理想的、单调改进策略的性能差距的下界。我们进一步提出了两种在训练和测试时估计上下文价值的方法。在Dark Room和Minigrid测试平台上进行的实验表明,CV-ICRL有效地缓解了性能下降,并提高了各种任务和环境中的整体ICRL能力。该论文的源代码和数据可在https://github.com/Bluixe/towards_monotonic_improvement 获取。
🔬 方法详解
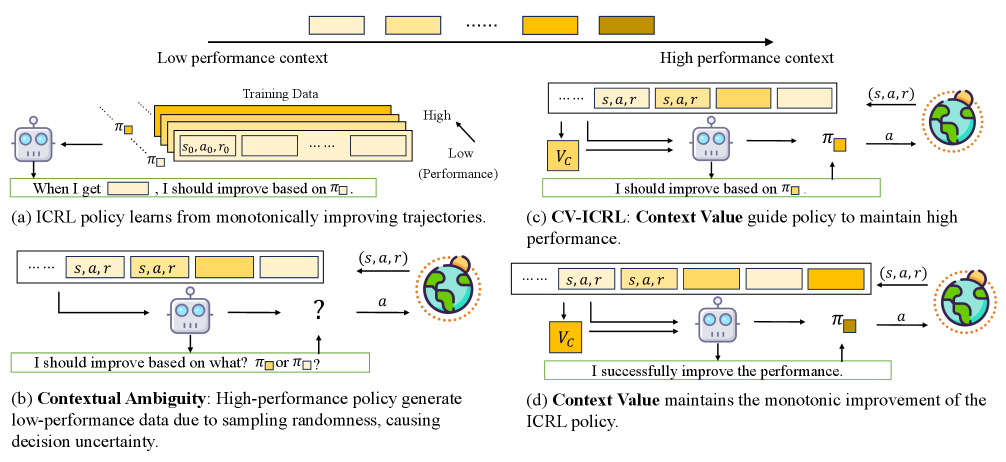
问题定义:ICRL旨在通过上下文学习快速适应新任务,但现有方法在测试时无法保证单调的性能提升。主要原因是模型自身的随机动作会产生误导性的交互历史,导致模型错误地认为当前策略是次优的,从而选择更差的动作,形成恶性循环,即上下文歧义问题。
核心思路:论文的核心思路是引入“上下文价值”(Context Value)的概念,作为策略在给定上下文下理论上可达到的理想性能的显式信号。通过在训练过程中利用上下文价值,引导模型学习更优的策略,从而缓解上下文歧义问题。上下文价值随着上下文的扩展,应包含更多任务相关信息,因此理想性能应单调不减。
技术框架:CV-ICRL的整体框架是在标准的ICRL训练流程中加入上下文价值的估计和利用。主要包含以下几个阶段:1) 使用在线RL生成训练数据,包括状态、动作、奖励和上下文信息;2) 估计上下文价值,论文提出了两种估计方法;3) 使用序列模型(如Transformer)训练ICRL策略,同时将上下文价值作为额外的输入信号;4) 在测试时,使用训练好的ICRL策略进行决策,并根据上下文价值进行调整。
关键创新:论文最重要的创新点在于提出了上下文价值的概念,并将其作为显式信号引入ICRL的训练过程中。这与以往的ICRL方法不同,以往的方法主要依赖于隐式地学习上下文信息,而忽略了对策略性能的直接指导。通过上下文价值,模型可以更准确地评估当前策略的优劣,从而避免陷入上下文歧义的陷阱。
关键设计:论文提出了两种估计上下文价值的方法。具体的技术细节未知,摘要中没有详细描述。损失函数的设计也未知,但推测会包含一项鼓励策略输出与上下文价值一致的项。网络结构方面,应该是在原有的序列模型基础上,增加了上下文价值作为输入。
🖼️ 关键图片
📊 实验亮点
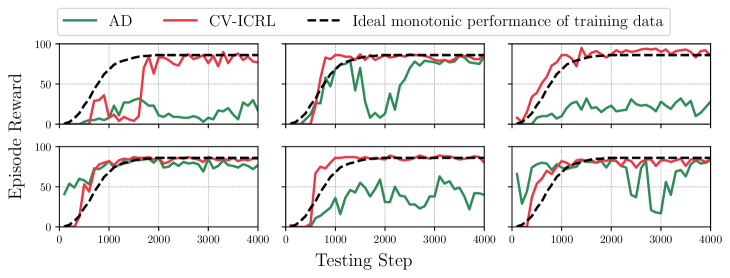
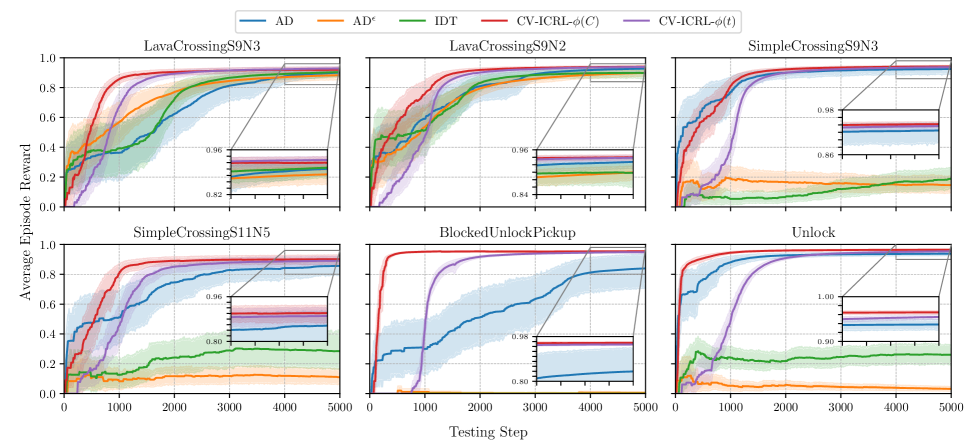
论文在Dark Room和Minigrid测试平台上进行了实验,结果表明CV-ICRL能够有效缓解性能下降,并提升ICRL在各种任务和环境中的整体能力。具体的性能数据和提升幅度未知,需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域,尤其适用于需要在未知环境中快速适应新任务的场景。通过利用上下文价值,可以提高智能体在复杂环境中的学习效率和泛化能力,降低对大量训练数据的依赖,并提升系统的鲁棒性和可靠性。
📄 摘要(原文)
In-Context Reinforcement Learning (ICRL) has emerged as a promising paradigm for developing agents that can rapidly adapt to new tasks by leveraging past experiences as context, without updating their parameters. Recent approaches train large sequence models on monotonic policy improvement data from online RL, aiming to a continue improved testing time performance. However, our experimental analysis reveals a critical flaw: these models cannot show a continue improvement like the training data during testing time. Theoretically, we identify this phenomenon as Contextual Ambiguity, where the model's own stochastic actions can generate an interaction history that misleadingly resembles that of a sub-optimal policy from the training data, initiating a vicious cycle of poor action selection. To resolve the Contextual Ambiguity, we introduce Context Value into training phase and propose Context Value Informed ICRL (CV-ICRL). CV-ICRL use Context Value as an explicit signal representing the ideal performance theoretically achievable by a policy given the current context. As the context expands, Context Value could include more task-relevant information, and therefore the ideal performance should be non-decreasing. We prove that the Context Value tightens the lower bound on the performance gap relative to an ideal, monotonically improving policy. We fruther propose two methods for estimating Context Value at both training and testing time. Experiments conducted on the Dark Room and Minigrid testbeds demonstrate that CV-ICRL effectively mitigates performance degradation and improves overall ICRL abilities across various tasks and environments. The source code and data of this paper are available at https://github.com/Bluixe/towards_monotonic_improvement .