Bridging the Gap Between Promise and Performance for Microscaling FP4 Quantization
作者: Vage Egiazarian, Roberto L. Castro, Denis Kuznedelev, Andrei Panferov, Eldar Kurtic, Shubhra Pandit, Alexandre Marques, Mark Kurtz, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh
分类: cs.LG
发布日期: 2025-09-27 (更新: 2025-10-16)
💡 一句话要点
提出MR-GPTQ,针对FP4量化特性优化GPTQ算法,提升LLM推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: FP4量化 GPTQ 大型语言模型 模型推理加速 Hadamard变换
📋 核心要点
- 现有方法在FP4量化中面临挑战,NVFP4的小组大小限制了离群值缓解,MXFP4的二次幂缩放导致精度下降。
- MR-GPTQ通过块状Hadamard变换和格式特定优化,针对FP4的特性定制量化过程,提升量化精度。
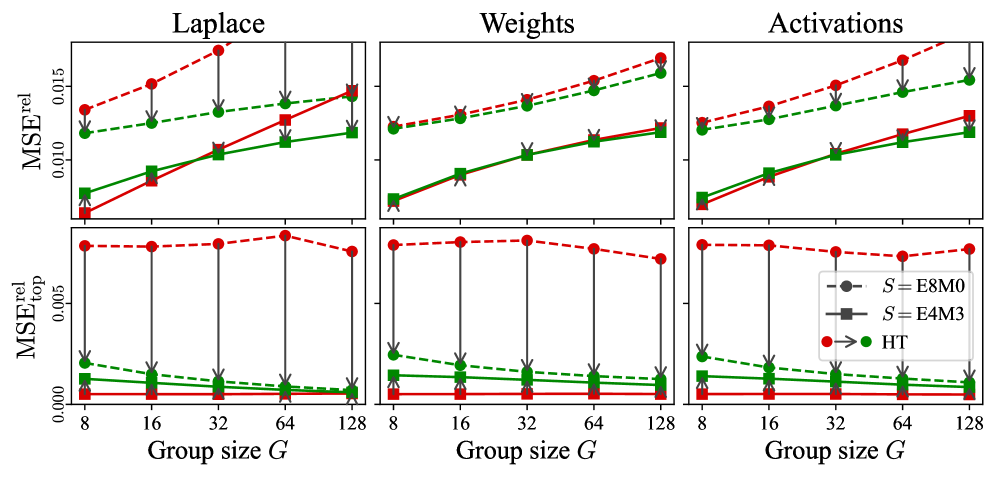
- 实验表明,MR-GPTQ在NVIDIA B200和RTX5090上实现了显著的加速,并提升了MXFP4的精度。
📝 摘要(中文)
本文全面研究了NVIDIA和AMD GPU上硬件加速的微缩放4位浮点格式MXFP4和NVFP4在大型语言模型(LLM)推理中的应用,揭示了其承诺与实际性能之间的差距。分析表明,由于NVFP4的小组大小限制了传统离群值缓解技术,以及MXFP4的二次幂缩放量化导致精度严重下降,现有方法在FP4上表现不佳。为此,本文提出了一种名为Micro-Rotated-GPTQ (MR-GPTQ) 的GPTQ量化算法变体,通过块状Hadamard变换和特定于格式的优化,专门针对FP4的独特属性定制量化过程。通过高性能GPU内核,MR-GPTQ格式实现了可忽略的开销,并通过旋转融合到权重中以及快速在线计算激活值。在NVIDIA B200上,层级加速高达3.6倍,端到端加速高达2.2倍;在RTX5090上,层级加速高达6倍,端到端加速高达4倍。实验结果表明,MR-GPTQ在精度上与最先进的方法相匹配或超过,显著提升了MXFP4的性能,使其精度接近NVFP4。结论是,FP4并非INT4的自动升级,但像MR-GPTQ这样针对格式优化的方法可以开启精度-性能权衡的新前沿。
🔬 方法详解
问题定义:论文旨在解决现有量化方法在应用于微缩放4位浮点格式(FP4,特别是MXFP4和NVFP4)时,无法充分发挥其硬件加速优势的问题。现有方法,如直接应用INT4量化策略,在FP4上表现不佳,精度损失严重,无法达到预期的性能提升。NVFP4的小组大小限制了离群值缓解,而MXFP4的二次幂缩放量化引入了较大的量化误差。
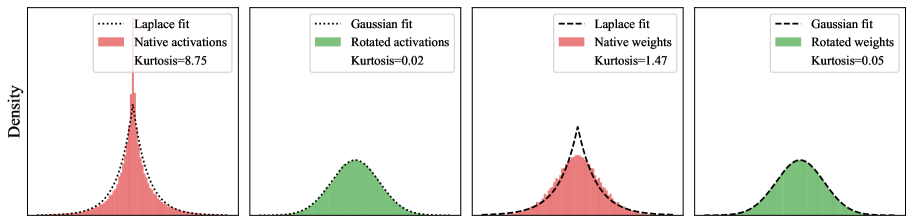
核心思路:论文的核心思路是针对FP4格式的特性,定制量化过程。通过引入Micro-Rotated-GPTQ (MR-GPTQ),一种GPTQ的变体,利用块状Hadamard变换来降低量化误差,并进行格式特定的优化,从而提高量化精度。这种方法旨在弥合FP4的理论潜力与实际性能之间的差距。
技术框架:MR-GPTQ的整体框架基于GPTQ算法,主要包含以下几个阶段:1) 权重预处理:对权重进行块状Hadamard变换,以降低量化误差;2) 量化:使用针对FP4格式优化的量化策略,将权重转换为FP4格式;3) 旋转融合:将Hadamard变换融合到权重中,减少计算开销;4) 激活值计算:使用优化的GPU内核快速在线计算激活值。
关键创新:MR-GPTQ的关键创新在于:1) 针对FP4格式的量化优化:针对MXFP4和NVFP4的特性,设计了特定的量化策略,例如,针对MXFP4的二次幂缩放,优化了量化范围;2) 块状Hadamard变换:通过Hadamard变换降低量化误差,提高量化精度;3) 高性能GPU内核:开发了高性能的GPU内核,实现了旋转融合和快速激活值计算,降低了计算开销。与现有方法的本质区别在于,MR-GPTQ不是简单地将INT4量化策略应用于FP4,而是针对FP4的特性进行了定制优化。
关键设计:MR-GPTQ的关键设计包括:1) 块大小的选择:Hadamard变换的块大小需要根据模型结构和硬件特性进行调整;2) 量化范围的优化:针对MXFP4的二次幂缩放,需要优化量化范围,以降低量化误差;3) GPU内核的优化:需要针对GPU架构,优化GPU内核,以实现高性能的旋转融合和激活值计算。
🖼️ 关键图片
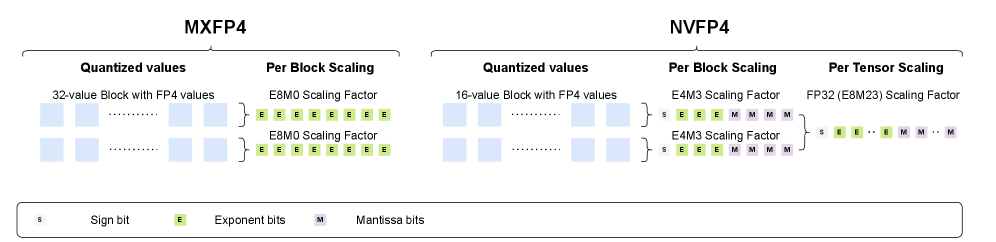
📊 实验亮点
实验结果表明,MR-GPTQ在NVIDIA B200上实现了高达3.6倍的层级加速和2.2倍的端到端加速,在RTX5090上实现了高达6倍的层级加速和4倍的端到端加速。同时,MR-GPTQ显著提升了MXFP4的精度,使其接近NVFP4的精度,证明了其在FP4量化方面的优越性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的部署和推理加速,尤其是在资源受限的边缘设备上。通过提高FP4量化的精度和效率,可以降低模型大小和计算复杂度,从而实现更快的推理速度和更低的功耗。这对于自然语言处理、智能助手、机器翻译等领域具有重要的实际价值和未来影响。
📄 摘要(原文)
The recent hardware-accelerated microscaling 4-bit floating-point formats such as MXFP4 and NVFP4, supported on NVIDIA and AMD GPUs, promise to revolutionize large language model (LLM) inference. Yet, their practical benefits remain unproven. We present the first comprehensive study of MXFP4 and NVFP4 for post-training quantization, revealing gaps between their promise and real-world performance. Our analysis shows that state-of-the-art methods struggle with FP4, due to two key issues: (1) NVFP4's small group size provably neutralizes traditional outlier mitigation techniques; (2) MXFP4's power-of-two scale quantization severely degrades accuracy due to high induced error. To bridge this gap, we introduce Micro-Rotated-GPTQ (MR-GPTQ), a variant of the classic GPTQ quantization algorithm that tailors the quantization process to FP4's unique properties, by using block-wise Hadamard transforms and format-specific optimizations. We support our proposal with a set of high-performance GPU kernels that enable the MR-GPTQ format with negligible overhead, by rotation fusion into the weights, and fast online computation of the activations. This leads to speedups vs. FP16 of up to 3.6x layer-wise, and 2.2x end-to-end on NVIDIA B200, and of 6x layer-wise and 4x end-to-end on RTX5090. Our extensive empirical evaluation demonstrates that MR-GPTQ matches or outperforms state-of-the-art accuracy, significantly boosting MXFP4, to the point where it can near the accuracy that of NVFP4. We conclude that, while FP4 is not an automatic upgrade over INT4, format-specialized methods like MR-GPTQ can unlock a new frontier of accuracy-performance trade-offs.