CrystalGym: A New Benchmark for Materials Discovery Using Reinforcement Learning
作者: Prashant Govindarajan, Mathieu Reymond, Antoine Clavaud, Mariano Phielipp, Santiago Miret, Sarath Chandar
分类: cs.LG
发布日期: 2025-09-27
💡 一句话要点
提出 CrystalGym:一个用于强化学习材料发现的新基准测试环境
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 材料发现 密度泛函理论 晶体材料 基准测试 材料设计 奖励函数 优化算法
📋 核心要点
- 现有材料设计方法依赖高精度原子模拟,但计算成本高昂,限制了直接使用DFT信号进行训练。
- CrystalGym 提出使用强化学习直接优化材料属性,通过 DFT 计算作为奖励信号,指导材料设计。
- 实验评估了多种强化学习算法在 CrystalGym 上的性能,并分析了不同算法在不同环境设置下的效率。
📝 摘要(中文)
本研究提出了 CrystalGym,一个用于晶体材料发现的开源强化学习(RL)环境,旨在促进直接使用密度泛函理论(DFT)信号进行材料设计。由于DFT计算成本高昂,现有机器学习方法主要采用生成式方法,缺乏直接DFT反馈以改进训练和生成。CrystalGym通过基准测试常见的基于价值和基于策略的强化学习算法,来设计具有目标属性的各种晶体,例如带隙、体积模量和密度,这些属性直接从环境中的DFT计算得出。实验表明,不同的算法在样本效率和收敛性方面表现各异。此外,还研究了使用强化学习微调大型语言模型以改善基于DFT的奖励。CrystalGym旨在为强化学习研究人员和材料科学家提供一个测试平台,以解决具有实际应用意义的真实设计问题。
🔬 方法详解
问题定义:现有材料设计流程依赖于高精度的原子模拟,特别是密度泛函理论(DFT)计算。然而,DFT计算的巨大计算成本使得直接将其作为反馈信号用于机器学习模型的训练变得非常困难。因此,现有的机器学习方法,尤其是生成式方法,通常无法充分利用DFT的反馈来改进材料设计。
核心思路:本研究的核心思路是创建一个强化学习环境 CrystalGym,该环境能够模拟材料设计过程,并直接使用DFT计算作为奖励信号。通过强化学习,智能体可以学习如何优化材料的结构,以达到特定的目标属性,例如带隙、体积模量和密度。这种方法允许在材料设计循环中直接利用DFT信号,从而提高设计效率和性能。
技术框架:CrystalGym 环境包含以下主要组成部分:1) 状态空间:描述晶体材料的结构信息;2) 动作空间:定义可以对晶体结构进行的操作;3) 奖励函数:基于DFT计算的目标属性(例如带隙、体积模量、密度)来评估智能体的行为;4) 模拟器:执行DFT计算以获得奖励信号。研究人员在 CrystalGym 环境中测试了多种强化学习算法,包括基于价值的方法和基于策略的方法,以寻找最适合材料设计的算法。
关键创新:该研究的关键创新在于创建了一个能够直接使用DFT计算作为奖励信号的强化学习环境 CrystalGym。这使得研究人员能够探索使用强化学习来优化材料属性,而无需依赖于计算成本较低但精度较低的替代方法。此外,该研究还探索了使用强化学习微调大型语言模型,以改善基于DFT的奖励。
关键设计:CrystalGym 的关键设计包括:1) 精心设计的状态空间和动作空间,以确保智能体能够有效地探索材料结构空间;2) 使用 DFT 计算作为奖励函数,以确保奖励信号的准确性和可靠性;3) 提供多种预定义的材料设计任务,例如优化带隙、体积模量和密度;4) 提供易于使用的 API,以便研究人员可以轻松地集成自己的强化学习算法和材料模型。
🖼️ 关键图片
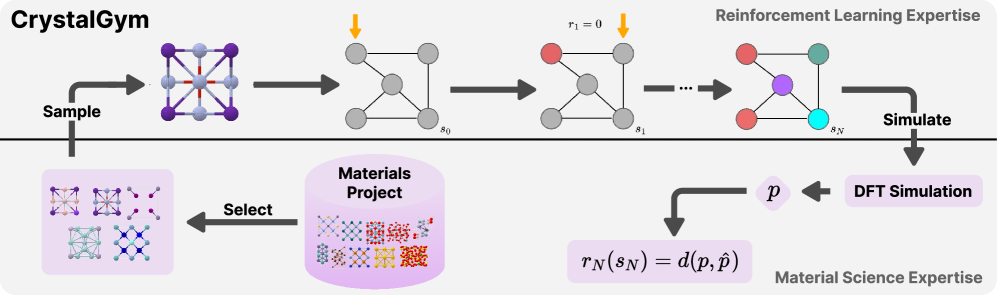

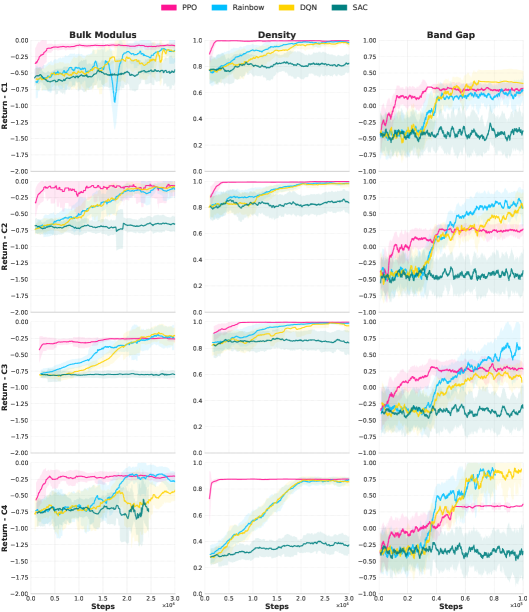
📊 实验亮点
实验结果表明,不同的强化学习算法在 CrystalGym 环境中表现各异,在样本效率和收敛性方面存在差异。虽然没有一种算法能够解决所有 CrystalGym 任务,但实验结果为选择合适的算法和环境设置提供了有价值的指导。此外,研究还表明,使用强化学习微调大型语言模型可以改善基于DFT的奖励,为未来的研究方向提供了启示。
🎯 应用场景
CrystalGym 的潜在应用领域包括新材料的发现和优化,例如用于太阳能电池、催化剂和储能设备的新型晶体材料。通过使用强化学习自动优化材料属性,可以加速材料设计过程,降低研发成本,并发现具有优异性能的新材料。该研究为材料科学和机器学习的交叉研究提供了一个有价值的平台,并有望推动相关领域的创新。
📄 摘要(原文)
In silico design and optimization of new materials primarily relies on high-accuracy atomic simulators that perform density functional theory (DFT) calculations. While recent works showcase the strong potential of machine learning to accelerate the material design process, they mostly consist of generative approaches that do not use direct DFT signals as feedback to improve training and generation mainly due to DFT's high computational cost. To aid the adoption of direct DFT signals in the materials design loop through online reinforcement learning (RL), we propose CrystalGym, an open-source RL environment for crystalline material discovery. Using CrystalGym, we benchmark common value- and policy-based reinforcement learning algorithms for designing various crystals conditioned on target properties. Concretely, we optimize for challenging properties like the band gap, bulk modulus, and density, which are directly calculated from DFT in the environment. While none of the algorithms we benchmark solve all CrystalGym tasks, our extensive experiments and ablations show different sample efficiencies and ease of convergence to optimality for different algorithms and environment settings. Additionally, we include a case study on the scope of fine-tuning large language models with reinforcement learning for improving DFT-based rewards. Our goal is for CrystalGym to serve as a test bed for reinforcement learning researchers and material scientists to address these real-world design problems with practical applications. We therefore introduce a novel class of challenges for reinforcement learning methods dealing with time-consuming reward signals, paving the way for future interdisciplinary research for machine learning motivated by real-world applications.