Critique to Verify: Accurate and Honest Test-Time Scaling with RL-Trained Verifiers
作者: Zhicheng Yang, Zhijiang Guo, Yinya Huang, Yongxin Wang, Yiwei Wang, Xiaodan Liang, Jing Tang
分类: cs.LG
发布日期: 2025-09-27
备注: 15 pages, 7 figures
💡 一句话要点
提出Mirror-Critique框架,通过强化学习训练验证器,提升大语言模型测试时推理的准确性和可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时缩放 强化学习 验证器训练 批判信号
📋 核心要点
- 现有大语言模型测试时缩放方法依赖奖励模型选择,但难以识别少量正确答案,限制了性能。
- Mirror-Critique框架通过对比模型生成解与真实解,利用高质量批判信号训练验证器。
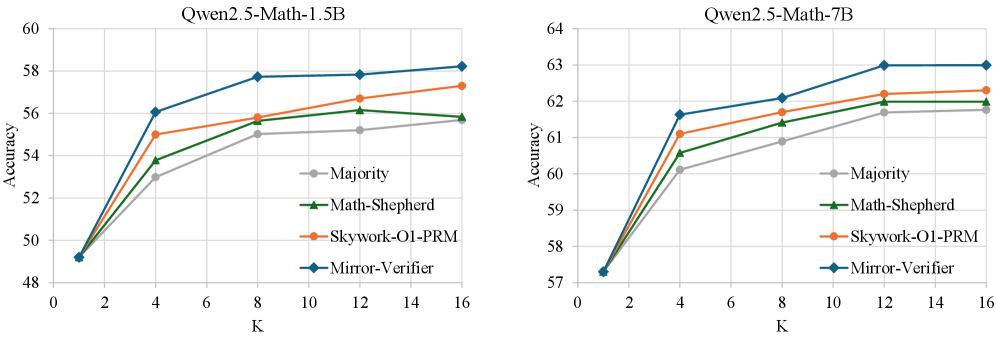
- 实验表明,Mirror-Verifier显著提升了解的准确性,并增强了模型识别自身能力边界的能力。
📝 摘要(中文)
本文提出了一种名为Mirror-Critique的框架,旨在提升大语言模型(LLMs)在测试时通过解采样和聚合进行缩放的推理性能。现有方法通常采用奖励模型选择,但其无法有效识别少量但正确的答案,限制了其效果。Mirror-Critique通过对比模型生成的解与ground-truth解,利用丰富的批判信号训练验证器。该框架使用一个小型指令调优模型,通过拒绝采样合成高质量的批判数据,教导验证器识别错误之处及其原因。合成数据用于冷启动RLVR过程中的LLMs,进一步提高验证能力。最终的Mirror-Verifier通过为每个解生成多个批判,并将它们聚合成一个验证分数,用于加权投票或选择性弃权,从而评估候选解。实验结果表明,Mirror-Verifier在解的准确性方面显著优于多数投票,并提高了求解器识别和放弃超出其能力范围之外问题的能力。
🔬 方法详解
问题定义:现有的大语言模型在测试时进行缩放(Test-time scaling)时,通常采用解采样和聚合的方法来提升推理性能。然而,常用的奖励模型选择方法无法有效地识别那些少数但正确的答案,导致其性能提升受限,甚至不如简单的多数投票策略。因此,如何训练一个能够准确识别正确答案,并有效区分错误答案的验证器,是本文要解决的核心问题。
核心思路:本文的核心思路是通过引入更具信息量的批判信号来训练验证器。具体来说,通过对比模型生成的解与ground-truth解,让验证器学习识别解的正确与错误之处,以及错误的原因。这种对比学习的方式能够提供更丰富的监督信息,从而提升验证器的判断能力。
技术框架:Mirror-Critique框架主要包含以下几个阶段:1) 批判数据合成:使用一个小型指令调优模型,通过拒绝采样的方式,生成高质量的批判数据。这些数据不仅包含解的正确与否的信息,还包含错误的原因。2) 验证器训练:使用合成的批判数据冷启动强化学习(RL)过程,训练验证器。3) 解评估与聚合:使用训练好的Mirror-Verifier评估候选解,为每个解生成多个批判,并将这些批判聚合成一个验证分数。4) 加权投票或选择性弃权:根据验证分数,对候选解进行加权投票,或者选择性地放弃回答那些验证分数较低的问题。
关键创新:本文最重要的技术创新点在于引入了“镜像批判”(Mirror-Critique)的概念,即通过对比模型生成的解与ground-truth解,来生成更具信息量的批判信号。这种方法能够有效地解决现有奖励模型选择方法中批判信号不足的问题,从而提升验证器的判断能力。与现有方法相比,Mirror-Critique能够提供更细粒度的反馈信息,帮助验证器更好地理解解的正确与错误之处。
关键设计:在批判数据合成阶段,使用了拒绝采样策略来保证批判数据的质量。在验证器训练阶段,使用了强化学习(RL)方法,并利用合成的批判数据进行冷启动,加速了训练过程。在解评估阶段,为每个解生成多个批判,并通过聚合这些批判来得到最终的验证分数。具体的损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Mirror-Verifier在解的准确性方面显著优于多数投票策略,并且提高了求解器识别和放弃超出其能力范围之外问题的能力。具体的性能提升数据在论文中进行了详细展示(未知)。与现有方法相比,Mirror-Critique能够更有效地提升大语言模型在测试时的推理性能。
🎯 应用场景
该研究成果可应用于各种需要大语言模型进行推理和决策的场景,例如问答系统、对话机器人、代码生成等。通过提高模型推理的准确性和可靠性,可以提升用户体验,并降低模型出错的风险。此外,该方法还可以用于评估模型的知识边界,帮助模型更好地识别自身的能力范围,从而避免回答超出其能力范围的问题。
📄 摘要(原文)
Test-time scaling via solution sampling and aggregation has become a key paradigm for improving the reasoning performance of Large Language Models (LLMs). While reward model selection is commonly employed in this approach, it often fails to identify minority-yet-correct answers, which limits its effectiveness beyond that of simple majority voting. We argue that this limitation stems from a lack of informative critique signals during verifier training. To bridge this gap, we introduce Mirror-Critique, a framework that trains a verifier with informative critiques. Our key insight is to leverage the rich critique signal by contrasting model-generated solutions with ground-truth solutions. We deploy a small instruction-tuned model to synthesize high-quality critique data with rejection sampling that teaches the verifier not only what is wrong, but also why. The synthetic data is used to cold-start the LLMs in the RLVR process to further improve the verification ability. The resulting Mirror-Verifier is deployed to evaluate candidate solutions by generating multiple critiques per solution, aggregating them into a verify score used for weighted voting or selective abstention. The experimental results show that our Mirror-Verifier significantly outperforms majority voting in terms of solution accuracy and also improves the solver's honesty to recognize and abstain from answering beyond its capability boundaries.