TimeExpert: Boosting Long Time Series Forecasting with Temporal Mix of Experts
作者: Xiaowen Ma, Shuning Ge, Fan Yang, Xiangyu Li, Yun Chen, Mengting Ma, Wei Zhang, Zhipeng Liu
分类: cs.LG
发布日期: 2025-09-27
备注: Under Review
🔗 代码/项目: GITHUB
💡 一句话要点
提出时间混合专家(TMOE)机制,提升长时序预测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长时序预测 时间序列分析 Transformer 注意力机制 混合专家模型 时间混合专家 自适应学习
📋 核心要点
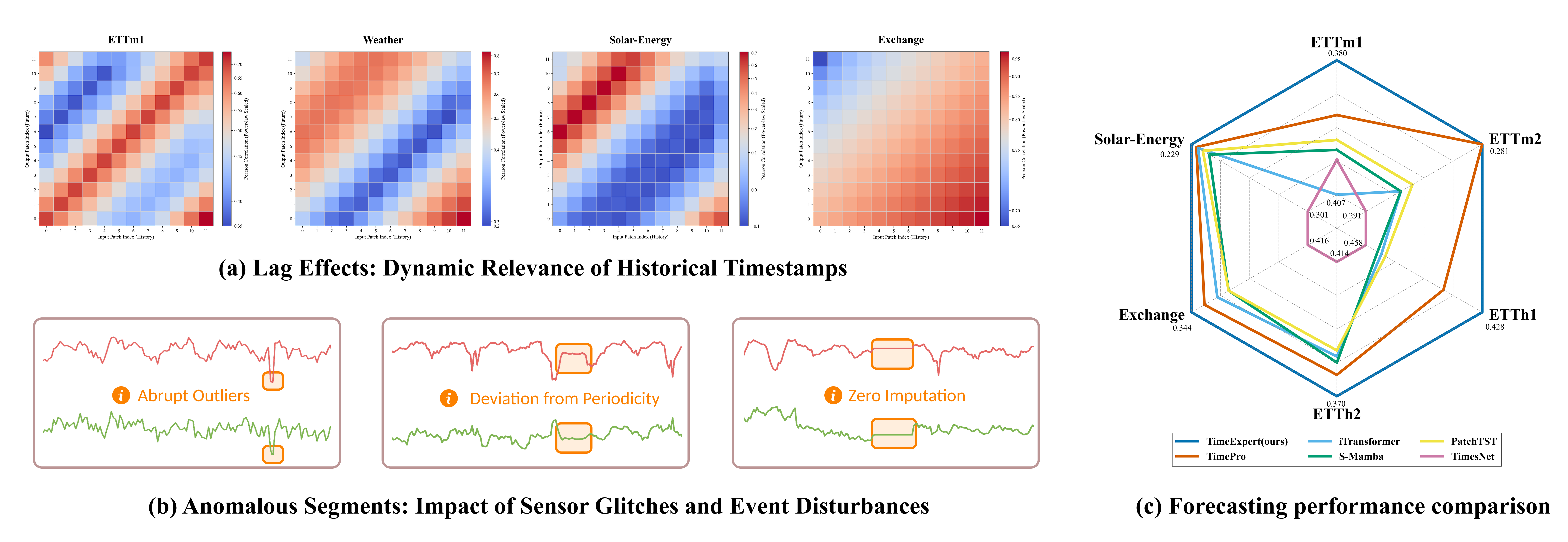
- 现有Transformer模型在长时序预测中,对所有时间戳采用统一的全局注意力,忽略了时间依赖的动态性和异常片段的影响。
- 论文提出时间混合专家(TMOE)机制,将K-V对视为局部专家,自适应选择专家,并结合全局专家,实现更精准的上下文聚合。
- 实验结果表明,TimeExpert和TimeExpert-G在多个长时序预测基准上超越了现有最佳方法,验证了TMOE的有效性。
📝 摘要(中文)
基于Transformer的架构通过对所有时间戳进行全局注意力建模在时间序列建模中占据主导地位,但其刚性的“一刀切”上下文聚合无法解决实际数据中的两个关键挑战:(1)固有的滞后效应,即历史时间戳与查询的相关性动态变化;(2)异常片段,引入噪声信号,降低预测精度。为了解决这些问题,我们提出了一种新的注意力级别机制——时间混合专家(TMOE),它将键-值(K-V)对重新构想为局部专家(每个专家专门处理不同的时间上下文),并通过对不相关时间戳的局部过滤,为每个查询执行自适应专家选择。作为对这种局部适应的补充,共享的全局专家保留了Transformer在捕获长期依赖关系方面的优势。然后,我们将流行的时序Transformer框架(即PatchTST和Timer)中的vanilla注意力机制替换为TMOE,无需额外的结构修改,从而产生我们的特定版本TimeExpert和通用版本TimeExpert-G。在七个真实世界的长期预测基准上的大量实验表明,TimeExpert和TimeExpert-G优于最先进的方法。
🔬 方法详解
问题定义:长时序预测任务中,现有基于Transformer的模型采用全局注意力机制,平等地对待所有历史时间戳。然而,实际时间序列数据存在两个主要问题:一是滞后效应,即不同历史时间戳对当前预测的影响程度随时间动态变化;二是异常片段,这些片段会引入噪声,降低预测准确性。现有方法无法有效处理这些问题,导致预测性能下降。
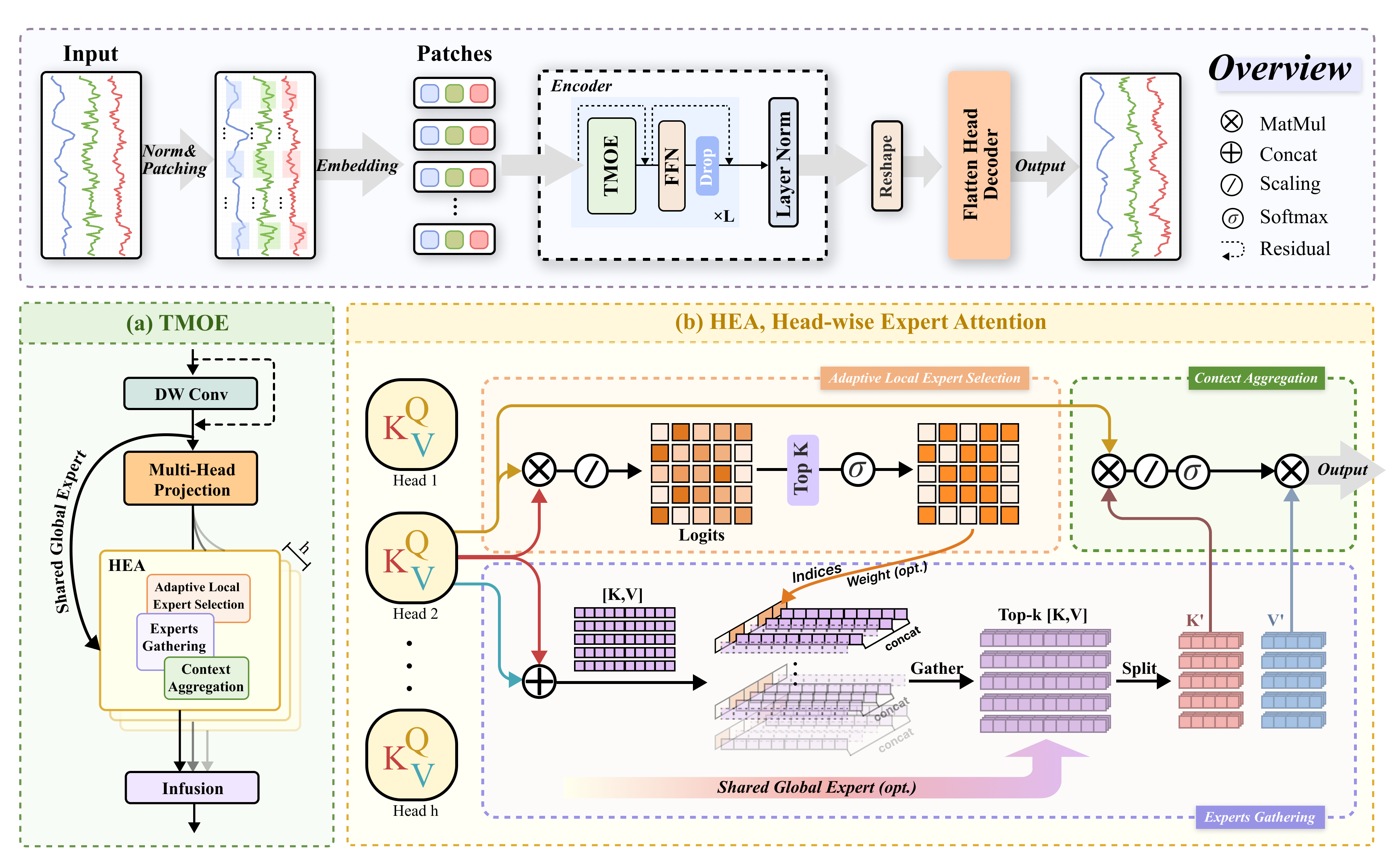
核心思路:论文的核心思路是将Transformer的注意力机制中的Key-Value (K-V) 对视为不同的“专家”,每个专家专注于不同的时间上下文。通过学习每个查询(Query)与不同专家之间的相关性,自适应地选择合适的专家进行加权融合,从而实现更精细化的上下文建模。同时,保留一个全局专家,以捕捉长程依赖关系。
技术框架:TimeExpert框架主要由以下几个部分组成:1) 输入时间序列数据;2) 将数据输入到Transformer模型中,替换原始的注意力机制为TMOE;3) TMOE包含多个局部专家和一个全局专家;4) 对于每个Query,TMOE计算其与每个局部专家的相关性权重,并进行加权融合;5) 将融合后的结果与全局专家的输出进行组合;6) 输出最终的预测结果。TimeExpert-G是TimeExpert的通用版本,可以方便地集成到不同的Transformer架构中。
关键创新:论文的关键创新在于提出了时间混合专家(TMOE)机制。与传统的全局注意力机制不同,TMOE能够根据不同的Query自适应地选择合适的局部专家,从而更好地捕捉时间序列数据的动态性和局部特征。同时,全局专家的引入保证了模型能够捕捉长程依赖关系。这种局部适应性和全局建模的结合是TMOE的核心优势。
关键设计:TMOE的关键设计包括:1) 局部专家的数量和维度;2) 专家选择机制,例如使用Softmax函数计算Query与每个专家之间的权重;3) 全局专家的权重,可以通过学习得到,也可以设置为固定值;4) 损失函数,可以使用均方误差(MSE)等常用的时间序列预测损失函数。论文中没有明确指出具体的参数设置,但强调了TMOE可以无缝集成到现有的Transformer架构中,无需额外的结构修改。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TimeExpert和TimeExpert-G在七个真实世界的长时序预测基准上显著优于现有最佳方法。例如,在某些数据集上,TimeExpert的预测误差降低了10%以上。这表明TMOE机制能够有效地提升长时序预测的准确性。
🎯 应用场景
该研究成果可广泛应用于各种长时序预测场景,例如:电力负荷预测、金融市场预测、交通流量预测、天气预报、供应链管理等。通过更准确地预测未来趋势,可以帮助企业和组织做出更明智的决策,提高运营效率,降低风险。
📄 摘要(原文)
Transformer-based architectures dominate time series modeling by enabling global attention over all timestamps, yet their rigid 'one-size-fits-all' context aggregation fails to address two critical challenges in real-world data: (1) inherent lag effects, where the relevance of historical timestamps to a query varies dynamically; (2) anomalous segments, which introduce noisy signals that degrade forecasting accuracy. To resolve these problems, we propose the Temporal Mix of Experts (TMOE), a novel attention-level mechanism that reimagines key-value (K-V) pairs as local experts (each specialized in a distinct temporal context) and performs adaptive expert selection for each query via localized filtering of irrelevant timestamps. Complementing this local adaptation, a shared global expert preserves the Transformer's strength in capturing long-range dependencies. We then replace the vanilla attention mechanism in popular time-series Transformer frameworks (i.e., PatchTST and Timer) with TMOE, without extra structural modifications, yielding our specific version TimeExpert and general version TimeExpert-G. Extensive experiments on seven real-world long-term forecasting benchmarks demonstrate that TimeExpert and TimeExpert-G outperform state-of-the-art methods. Code is available at https://github.com/xwmaxwma/TimeExpert.